Free Webinar: Website Migrations & Redirect Mapping Dos & Don’ts Sign up now!



This article explains how you can find isolated pages on your website using Sitebulb's SEO website audit software.
Sitebulb will report on isolated URLs as long as 'Search Engine Optimization' is ticked as one of the audit options when you set up the audit (it is always pre-checked by default). The 'Isolated HTML URLs' report shows as a section of the Indexability report.
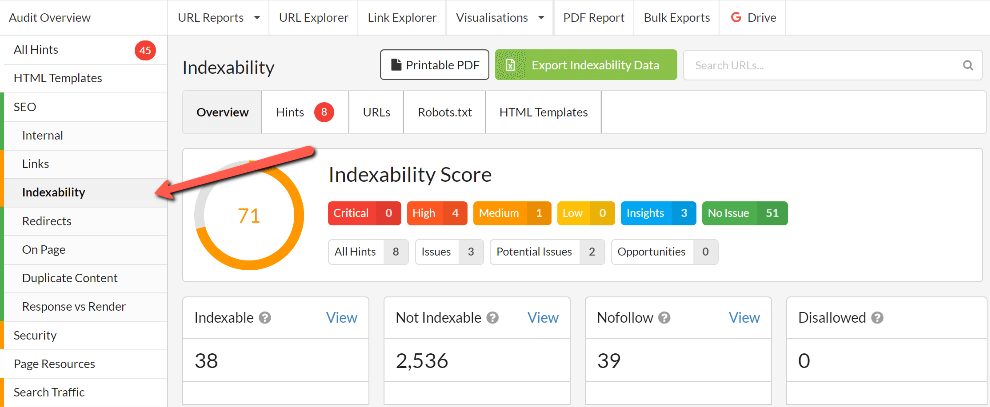
Scroll down within the Indexability report to find the relevant table.
Isolated pages can be both complex and subtle, yet Sitebulb will surface them for you automatically. However, you still need to understand what's happening, which requires a bit of digging and investigating.
From the table, click 'View URLs' for the state you wish to investigate further;
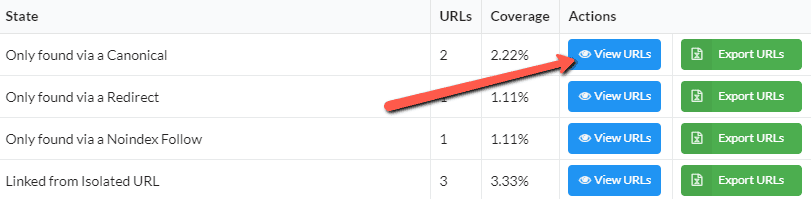
This will take you to a URL List, with an orange 'Crawl Path' button on the left - press this to investigate a specific URL;
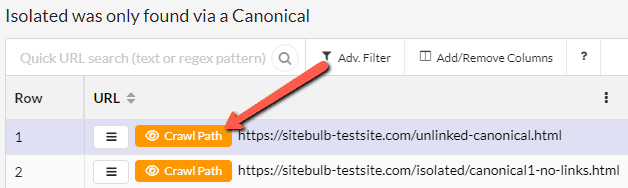
This will then show you how Sitebulb traversed the website to find the isolated URL:
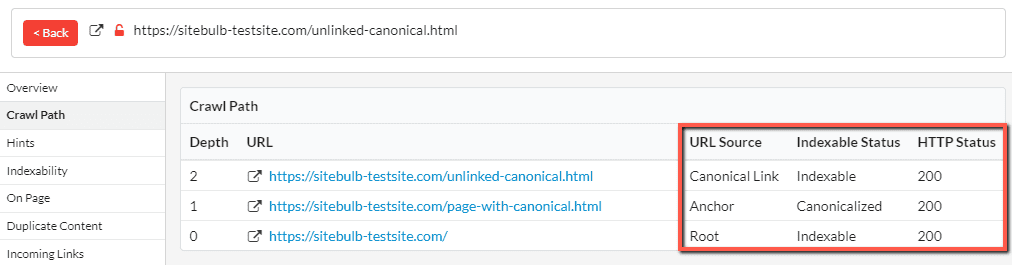
In this case, the homepage (Depth 0) links via an anchor to the URL at Depth 1. This URL is canonicalized to the URL at Depth 2. You can clearly see how the URL was found by tracing back the steps in the crawl path.
You can also verify that the URL is indeed isolated, and not connected to the link graph, by checking the incoming links:
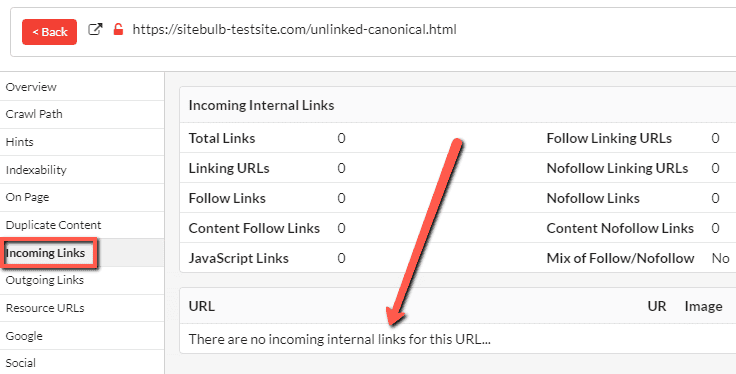
In addition to the 'isolated pages' panel on the Indexability report, you will also find these issues listed in the Indexability Hints;
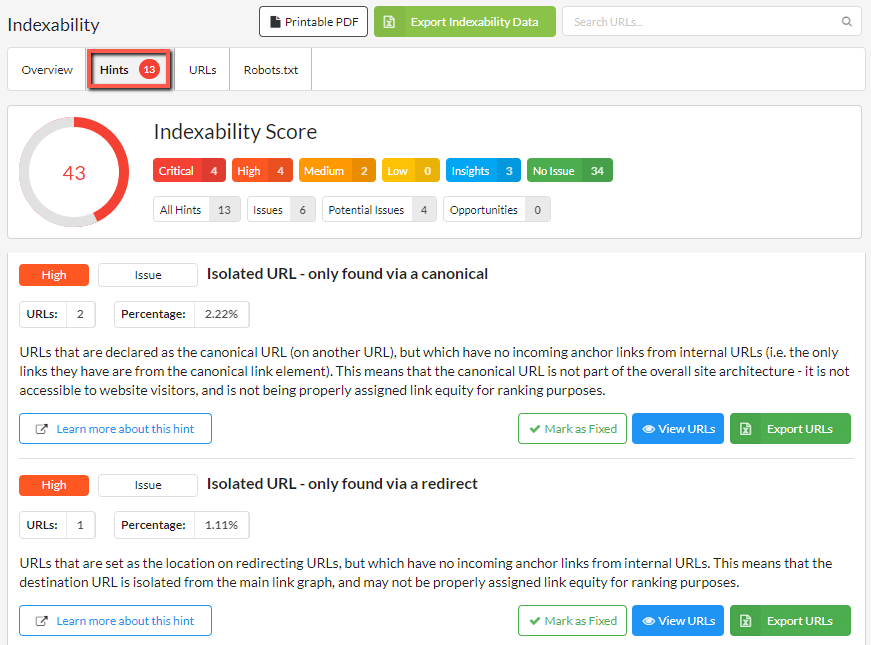
The 'Learn More' pages for each of these Hints contain specific instructions for how to tackle each type of isolated page: