
 Patrick Hathaway
Patrick Hathaway
JavaScript has been breaking websites (and SEOs) for over a decade, and it’s not slowing down anytime soon.
Yes, Google is much better at handling JS than it used to be. But let’s not kid ourselves; if your important content only appears after a user clicks, scrolls, or waits for an overworked script to hydrate, you’re basically playing hide-and-seek with Googlebot. And spoiler: Googlebot isn’t very patient.
And LLM crawl bots, they simply don't care if you've got content executed by JavaScript.
The problem is, modern websites lean on JavaScript more than ever. Think single-page apps, endless scrolls, client-side rendering, and fancy frameworks like React, Vue, or Next.js. Great for developers, sometimes not so great for SEO.
This guide is here to cut through the noise. I’ll walk you through how to crawl a JavaScript website, how Google processes JavaScript in 2025, as well as when you should and when you don’t need to. Along the way, I’ll show you where JavaScript still causes chaos, and how you can stop your content from disappearing into the void.
If you’ve ever spent an evening staring at “empty” HTML source code, wondering why your product pages don’t rank, you’re in the right place. Grab a coffee (or something stronger) and let’s dive in.
Interested in learning about JavaScript SEO? Register for our free on-demand training sessions. Sign up now
Why JavaScript still causes SEO headaches
If you’ve been in SEO long enough, you’ll know that “JavaScript SEO” is basically a polite way of saying “Google might ignore half your website - and LLMs definitely will.”
The core issue hasn’t changed: search engines don’t see the web the way humans do. You load a page, everything looks shiny, interactive, and full of content. Googlebot loads the same page and sometimes… nothing. A barren HTML shell with a couple of <script> tags and no sign of the good stuff.
Even in 2025, the biggest headaches look like this:
Delayed rendering: Your content is technically there, but it only shows up after JavaScript runs. If Googlebot doesn’t execute it quickly (or at all), that content may never be indexed.
Links hidden behind JS: Infinite scroll, mega-menus, or AJAX-powered navigation can leave Googlebot stranded, unable to crawl deeper.
User-triggered content: If a product grid only loads after someone clicks “Show more,” guess what? Google isn’t clicking.
Framework quirks: Modern frameworks like React, Vue, Angular, and Next.js are powerful, but misconfigured SSR or hydration can leave search engines with broken, half-rendered pages.
Even when Google does get around to rendering your site, you can still run into problems with crawl budget and Core Web Vitals. JavaScript-heavy sites often ship bloated bundles that choke performance. And performance is very much a ranking signal.
So yes, things are “better” than they were five years ago. But better doesn’t mean good. If your business relies on organic traffic, ignoring JavaScript SEO is basically asking Google, ChatGPT, Perplexity and all the other players to ghost you.
How Googlebot processes JavaScript today
Google’s ability to handle JavaScript has come a long way since the “Fetch & Render” days (RIP). But let’s be clear: just because Google can process JS, doesn’t mean it always goes smoothly.
Here’s the simplified version of what happens when Googlebot meets your shiny, JS-heavy site in 2025:
1. Crawl the raw HTML
Googlebot still starts with the plain old HTML it gets from the server. If there’s no meaningful content or links in there, you’ve already got a problem.
2. Queue for rendering
Google has to put pages in a rendering queue, and depending on resource demands, that can mean delays before your JS even gets executed. Yes, it’s better than it used to be, but it’s still not instant.
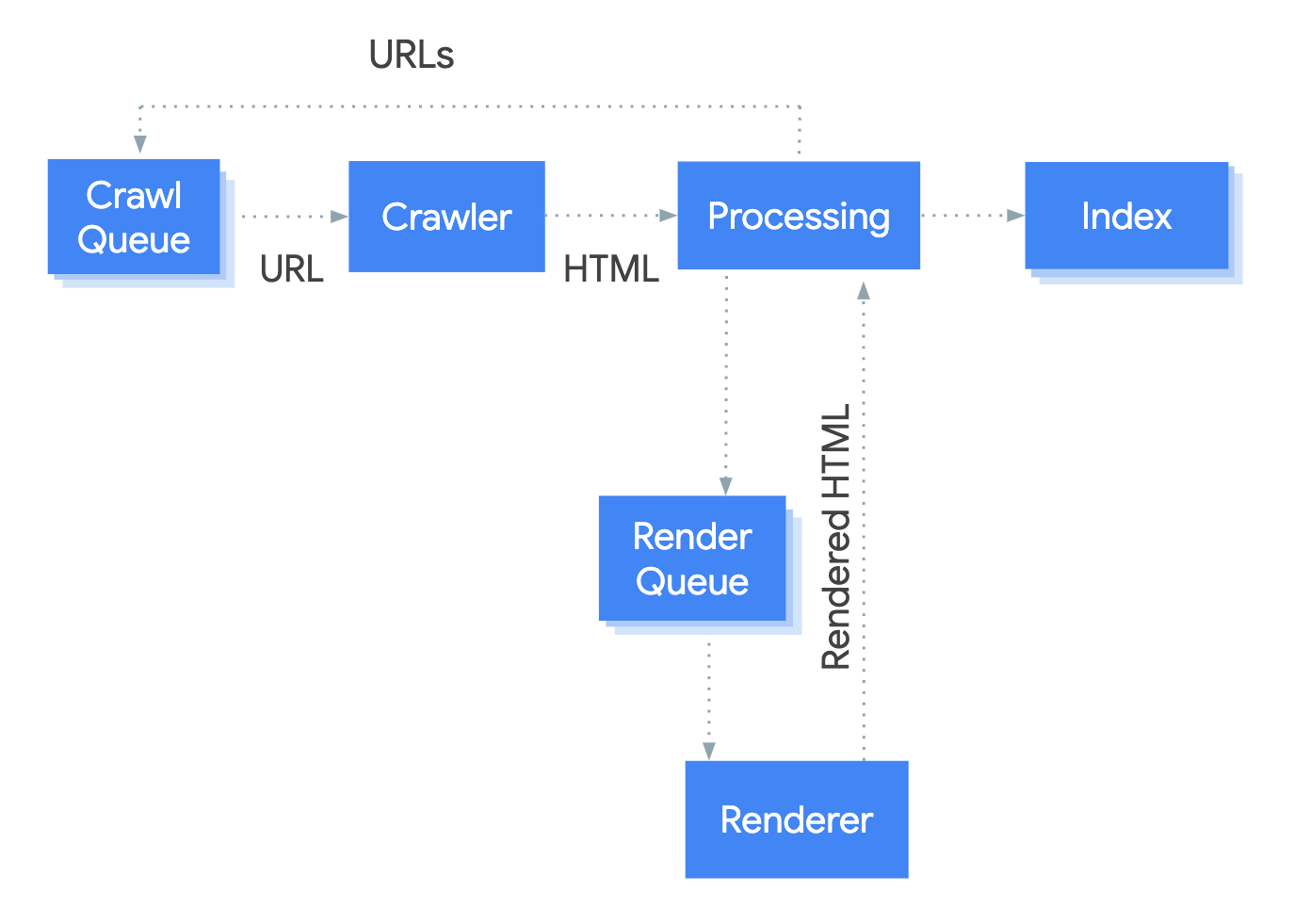
3. Render with evergreen Chromium
Google uses a headless, evergreen version of Chrome to run your JavaScript (same as Sitebulb!), fetch resources, and build the DOM. If your scripts are blocked, deferred badly, or rely on user interaction (e.g. click to load products), you may never make it to the finish line.
4. Index the rendered output
Only once Google has the rendered HTML+DOM does it attempt to index the content. This is why you’ll sometimes see “two-wave indexing”: first wave for raw HTML, second wave after rendering.
5. Rank (maybe)
Even if your page makes it this far, performance bottlenecks (slow hydration, layout shifts, Core Web Vitals disasters) can hold you back.
If you want official receipts, Google’s own documentation on JavaScript SEO lays this out in polite, corporate language. I just prefer the blunt version.
Tools to test JavaScript rendering
If you want to know whether Google can actually see your content, you can’t just trust your browser. You need to look at things the way a crawler does. Luckily, there are a bunch of tools (including Sitebulb) that make this less of a guessing game.
Here are the ones worth your time in 2025:
Google Search Console’s URL Inspection tool
Paste in a URL, hit “Test Live URL,” and you’ll see what Googlebot can fetch and render right now. If your product descriptions are missing in 'View Tested Page', you’ve got a problem.
Rich Results Test
Mostly pitched as a way to check structured data, but Google's Rich Results Test also shows a rendered HTML snapshot in 'View Tested Page'. Handy if you’re testing whether important content makes it into Google’s view of the page.
Chrome DevTools
The Elements panel shows you the live, rendered DOM, which is the closest thing to “what Google sees” after JavaScript has executed. Pair it with the Network panel to check whether key resources are actually loading, and use the Console to catch JavaScript errors that might block rendering.
Lighthouse (via Chrome DevTools or PageSpeed Insights)
Google officially retired the old Mobile-Friendly Test and Mobile Usability reports, so Lighthouse is now the go-to for mobile and rendering audits. You can run it straight from Chrome DevTools or through PageSpeed Insights.
Lighthouse gives you more than just performance scores: it shows whether content is blocked from rendering, highlights layout shifts, and flags accessibility or SEO issues. (It's also used within Sitebulb's Performance Report.)
Rendering Difference Engine
The team at Gray Dot Co made the Chrome extension they'd always wanted for quickly identifying discrepancies between the response HTML and rendered HTML on any webpage. Note that it does this page by page and not in bulk.
Sitebulb (desktop & cloud)
Yes, this is the part where I mention Sitebulb, because it’s built to handle this exact problem. Sitebulb doesn’t just crawl raw HTML; it also renders pages, so you can compare source vs. rendered DOM side by side - AND you can do it in bulk. Plus, if you’re working on a big JS-heavy site, Sitebulb Cloud means you don’t have to melt your laptop running it.
Psssst! Sitebulb doesn't charge anything extra for JavaScript crawling. This is one of the reasons we're such an appealing alternative to JetOctopus, Botify, Lumar and other crawlers.
Fixing rendering issues: modern solutions
So you’ve discovered that Googlebot isn’t seeing what you thought it was. The good news is there are proven ways to fix it.
Here are the main approaches in 2025:
Server-side rendering (SSR)
This is the gold standard. The server builds and serves a fully-rendered HTML page, so Googlebot doesn’t have to do the heavy lifting. Frameworks like Next.js, Nuxt, and Remix make SSR easier than it used to be, but don’t underestimate the complexity. If your dev team hears “SSR” and suddenly needs a long holiday, you’ll know why.
Pros: Search engines get content instantly, better for crawl budget, performance usually improves.
Cons: More moving parts on the server side, more headaches when debugging.
Static site generation (SSG)
Instead of rendering on the fly, you pre-render everything into static HTML files. Think Jamstack setups with Gatsby or Next.js in SSG mode. Great for content-heavy sites that don’t change every five seconds.
Pros: Blazing fast, very SEO-friendly, fewer runtime errors.
Cons: Not ideal if you’ve got thousands of pages changing constantly (like ecommerce stock). Build times can get silly.
Dynamic rendering (fallback option)
Dynamic rendering is the idea of serving bots a pre-rendered version of your site, while users get the normal JS-heavy version. Google still grudgingly documents it, but they’ve been clear: it’s a last resort, not a best practice. Tools like Rendertron or services like Prerender.io can help, but treat this as a temporary solution, not a cure.
Pros: Quick fix if you’re stuck with a site that can’t be rebuilt right now.
Cons: Maintenance nightmare, risk of cloaking if you mess it up, not future-proof.
Hybrid approaches
Many modern frameworks blur the lines, for example your homepage and category pages are SSR, but logged-in dashboards are client-side rendered.
Pros: Flexibility to balance performance, dev resources, and SEO.
Cons: Requires planning and a team that knows what they’re doing (and can agree on it).
At the end of the day, there’s no “one-size-fits-all” fix. The right solution depends on your site, your dev stack, and your appetite for complexity. But the worst thing you can do is cross your fingers and hope Google just figures it out.
How Sitebulb handles rendering
Sitebulb offers two different ways of crawling:
HTML Crawler
Chrome Crawler
The HTML Crawler uses the traditional method of downloading the source HTML and parsing it, without rendering JavaScript.
The Chrome Crawler utilizes headless Chromium (like Google) to render the page, then parse the rendered HTML. Since it takes time to compile and fire all the JavaScript in order to render the time, it is necessarily slower to crawl with the Chrome Crawler.
As we have mentioned above, however, some websites rely on client-side JavaScript and therefore can only be crawled with the Chrome Crawler.
Selecting the Chrome Crawler when setting up a new project, or in the crawler settings will allow you to crawl JavaScript sites.
Trying to crawl a JavaScript website without rendering
As a brief aside, we're first going to investigate what happens when you try to crawl a JavaScript website without rendering, which means selecting the 'HTML Crawler' in the settings.
Let's take a look...
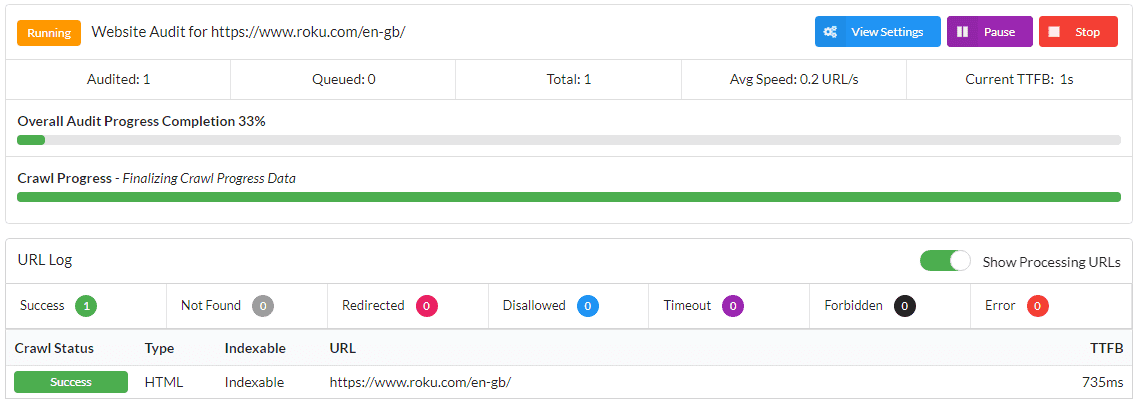
One page.
Why only one page? Because the response HTML (the stuff you can see with 'View Source') only contains a bunch of scripts and some fallback text.
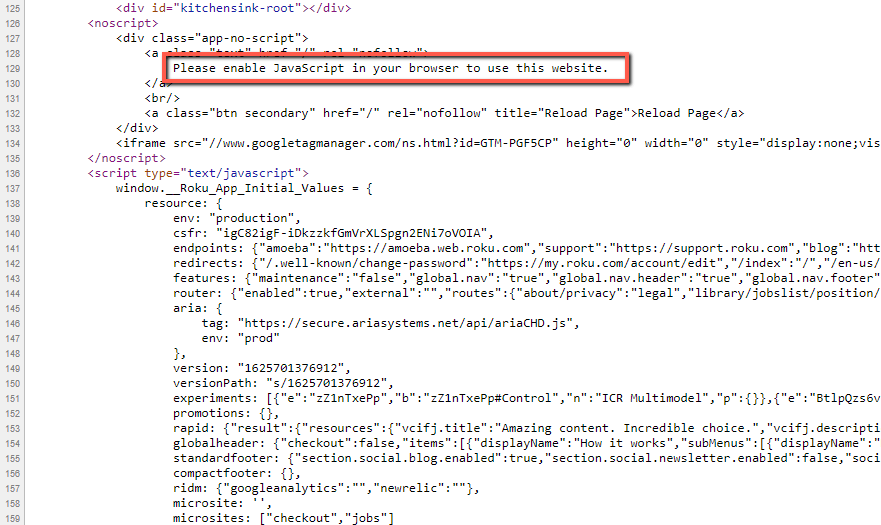
You simply can't see the meat and bones of the page - the product images, description, technical spec, video, and most importantly, links to other pages... everything a web crawler needs in order to understand your page content.
On websites like this you absolutely need to use the Chrome Crawler to get back any meaningful crawl data.
How to crawl JavaScript websites with Sitebulb
Every time you set up a new Project in Sitebulb, you have the option of setting it up to use the HTML Crawler or the Chrome Crawler. If you are crawling a JavaScript website, this is the first step you need to cover:

Secondly, you will also need to consider the render timeout, as this affects how much of the page content Sitebulb is actually able to access.
You will find this in the Crawler Settings on the left hand side, and the Render Timeout dropdown is right underneath 'Crawler Type' on the right.

By default, this is set at 1 second, which is absolutely fine for most sites that do not have a high dependence on JavaScript. However, websites built using a JavaScript framework have a very high dependence on JavaScript, so this needs to be set with some care.
What is this render timeout?
The render timeout is essentially how long Sitebulb will wait for rendering to complete before taking an 'HTML snapshot' of each web page.
Justin Briggs, a highly technical SEO, published a post waaaaay back in 2016 but is still an excellent primer on handling JavaScript content for SEO, which will help us explain where the Render Timeout fits in.
I strongly advise you go and read the whole post, but at the very least, the screenshot below shows the sequence of events that occur when a browser requests a page that is dependent upon JavaScript rendered content:

The 'Render Timeout' period used by Sitebulb starts just after #1, the Initial Request. So essentially, the render timeout is the time you need to wait for everything to load and render on the page. Say you have the Render Timeout set to 4 seconds, this means that the each page has 4 seconds for all the content to finish loading and any final changes to take effect.
Anything that changes after these 4 seconds will not be captured and recorded by Sitebulb.
Render timeout example
I'll demonstrate with an example, again using the Roku site we looked at earlier.
In my first audit I used the HTML Crawler - 1 URL crawled
In my second audit I used the Chrome Crawler with a 3 second render timeout - 139 URLs crawled
In my third audit I used the Chrome Crawler was a 5 second render timeout - 144 URLs crawled
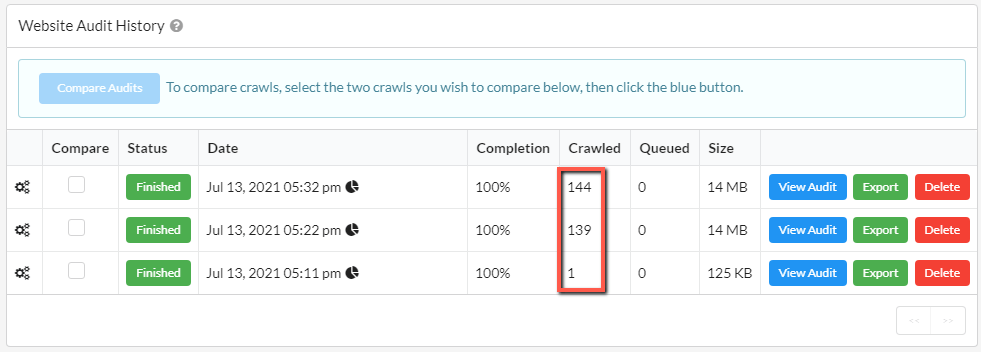
Digging into a little more detail about these two Chrome audits, there were 5 more internal HTML URLs found with the 5 second timeout. This means that, in the audit with a 3 second render timeout, the content which contains links to those URLs had not been loaded when Sitebulb took the snapshot.
I actually crawled it one more time after this with a 10 second render timeout, but there was no difference to the 5 second render timeout, which suggests that 5 seconds is sufficient to see all the content on this website.
On another example site, I experimented with not setting a render timeout at all, and crawling the site again with a 5 second timeout. Comparing the two Crawl Maps shows stark differences:
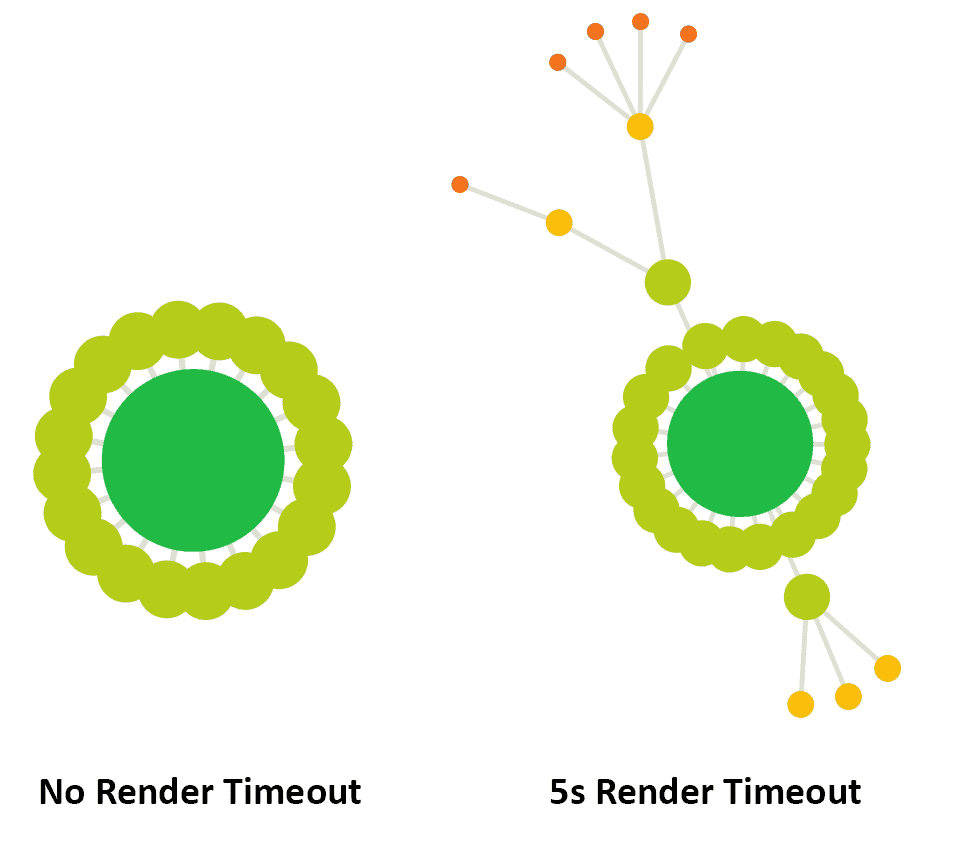
Clearly, this can have a profound impact upon your understanding of the website and its architecture, which underlines why it is very important to set the correct render timeout in order for Sitebulb to see all of the content.
Recommended render timeout
Understanding why the render timeout exists does not actually help us decide what to set it at.
Although Google have never published anything official about how long they wait for a page to render, most industry experts tend to concur that 5 seconds is generally considered to be 'about right'.
Either way, all this will show you is an approximation of what a search engine may be seeing. If you want to crawl ALL the content on your site, then you'll need to develop a better understanding of how the content on your website actually renders.
To do this, head to Chrome's DevTools Console. Right click on the page and hit 'Inspect', then select 'Network' from the tabs in the Console, and then reload the page. I've positioned the dock to the right of my screen to demonstrate:

Keep your eye on the waterfall graph that builds, and the timings that are recorded in the summary bar at the bottom:
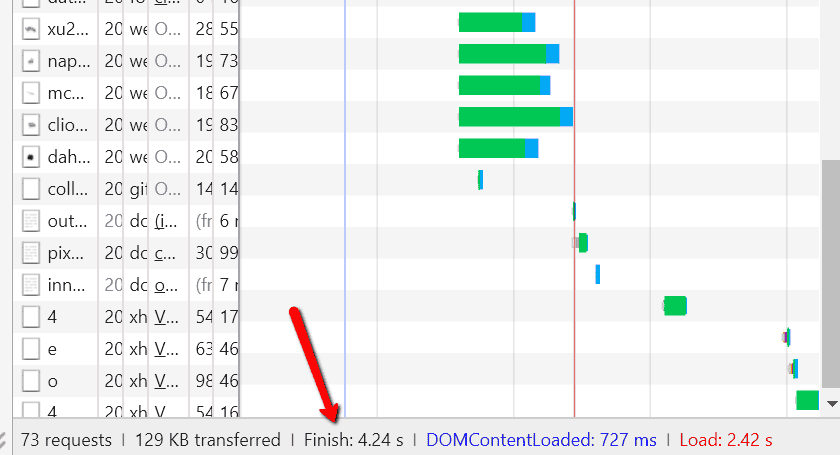
So we have 3 times recorded here:
DOMContentLoaded: 727 ms (= 0.727 s)
Load: 2.42 s
Finish: 4.24 s
You can find the definitions for 'DOMContentLoaded' and 'Load' from the image above that I took from Justin Briggs' post. The 'Finish' time is exactly that, when the content is fully rendered and any changes or asynchronous scripts have completed.
If the website content depends on JavaScript changes, then you really need to wait for the 'Finish' time, so use this as a rule of thumb for determining the render timeout.
Bear in mind that so far we've only looked at a single page. To develop a better picture of what's going on, you'd need to check a number of pages/page templates and check the timings for each one.
If you are going to be crawling with the Chrome Crawler, we urge you to experiment further with the render timeout so you can set your Projects up to correctly crawl all your content every time.
Rendering data from Google Tag Manager
Some SEOs use Google Tag Manager (GTM) in order to dynamically change on-page elements, either as a full-blown optimization solution, or as a proof-of-concept to justify budget for 'proper' dev work.
If you are unfamiliar with this, check out Dave Ashworth's post for Organic Digital - How To: Do Dynamic Product Meta Data in Magento Using GTM - which describes how he used GTM to dynamically re-write and localize the titles and meta descriptions for thousands of pages, with impressive results:
Most other web crawler tools won't be able to pick up the data inserted by GTM, which means they don't allow you to actually audit this data. This is because by default they block tracking scripts, which can have the affect of bloating audit data.
Here at Sitebulb, we have accounted for that too, and actually give you the option to turn this off, so you CAN collect on-page data dynamically inserted or changed using Google Tag Manager.
To do this, when setting up your audit, head over to the 'URL Exclusions' tab on the left hand menu, and navigate to the 'Block Scripts' tab to untick the option marked 'Block Ad and Tracking Scripts', which will always be ticked by default:

And then when you go ahead and crawl the site, Sitebulb will correctly extract the GTM-altered meta data. Note that you may need to tweak the render timeout.
Side effects of crawling with JavaScript
Almost every website you will ever see uses JavaScript to some degree: interactive elements, pop-ups, analytics codes, dynamic page elements... all controlled by JavaScript.
However, most websites do not employ JavaScript to dynamically alter the majority of the content on a given web page. For websites like this, there is no real benefit in crawling with JavaScript enabled. In fact, in terms of reporting, there is literally no difference at all:

And there are actually a couple of downsides to crawling with the Chrome Crawler, for example:
Crawling with the Chrome Crawler means you need to fetch and render every single page resource (JavaScript, Images, CSS, etc...) - which is more resource intensive for both your local machine that runs Sitebulb, and the server that the website is hosted on.
As a direct result of #1 above, crawling with the Chrome Crawler is slower than with the HTML Crawler, particularly if you have set a long render timeout. On some sites, and with some settings, it can end up taking 6-10 X longer to complete.
So if you find that the website does not have a large dependence on JavaScript, you may prefer to crawl with the HTML Crawler.
Note: there is one other reason you would choose the Chrome Crawler, and that is if you want to audit Performance or Accessibility, both of which require the use of the Chrome Crawler.
Comparing response vs rendered HTML
This is where you can make use of Sitebulb's unique report: Response vs Render, which is generated automatically whenever you use the Chrome Crawler.
What this does is render the page like normal, then runs a comparison of the rendered HTML against the response HTML (i.e. the 'View Source' HTML). It will check for differences in terms of all the important SEO elements:
Meta robots
Canonical
Page title
Meta description
Internal links
External links
Then the report in Sitebulb will show you if JavaScript has changed or modified any of these important elements:
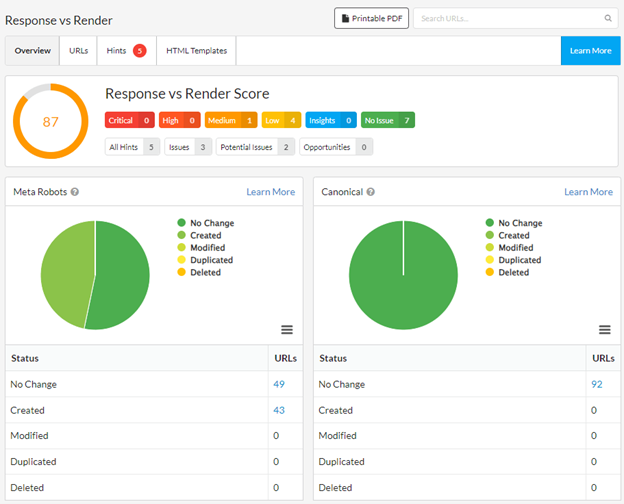
If every element is listed as 'No Change', the website has little to no dependence on JavaScript. If you see almost everything showing up as 'Created' or 'Modified', you are mostly likely dealing with a JavaScript framework or a single page application.
Often it is not quite as clear-cut, and you’ll find the website has some dependence on JavaScript on some pages - this is where the Response vs Render report is especially useful, as it will pick out these issues for you to address.
If any key DOM elements are being affected by JavaScript, Sitebulb will flags these up to you via the Hints tab:
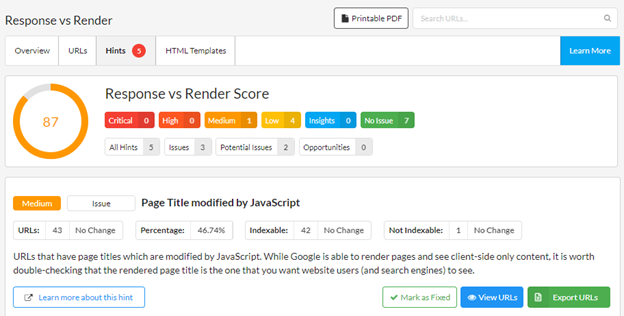
You may also come across instances where the website didn't change the main content, but did insert JavaScript links, then you'd see 'No Change' for most of the sections but lots of links created or modified in the links section:
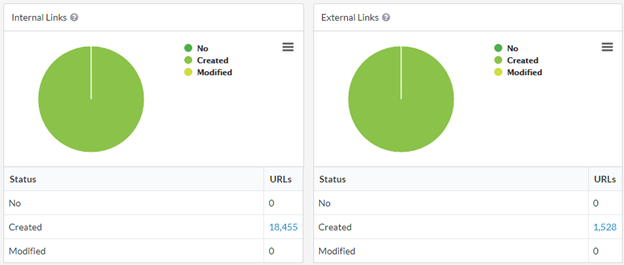
This reliance on JavaScript links means that if you DON'T crawl with JavaScript rendering, you will not be able to crawl the whole site.
For the most comprehensive understanding of how this report works, check out our response vs render comparison guide.
Include JavaScript in your 'discovery workflow'
When working on technical SEO for any new or unfamiliar website, part of your initial process involves discovery - what type of platform are they on, what kind of tracking/analytics are they using, how big is the website etc...
Our suggestion is that JavaScript should also enter this workflow, so you can be confident if rendering is required when crawling the site. Essentially the point of this is to determine the level of dependence upon JavaScript, and whether you need to render the pages in your audits moving forwards.
But also, knowing this could help you unpick issues with crawling or indexing, or affect how you tackle things like internal link optimization.
A simple workflow could look like this:
Run an exploratory Sitebulb audit using the Chrome Crawler
Analyze the Response vs Render report to see if JavaScript is affecting any of the content during rendering
Include the results of this in your audit, and make a decision for future audits as to whether the Chrome Crawler is needed or not. Remember that you may need to render content even if the website is not using a JavaScript framework.
Sam recently shared in our Real-World JavaScript SEO Problems webinar: “We use the response vs render report on Sitebulb. We run that in our regular client audits and it’s part of our processes when any key change is being made. I love the tool!”
…which was nice. And if you need further convincing that this is a good idea, just ask yourself 'what would Aleyda do...?'
Conclusion
JavaScript isn’t going away. If anything, it’s spreading... more frameworks, more complexity, more opportunities to accidentally hide your most important content.
Yes, Google’s rendering has improved. But as Aleyda noted: “In very, very little cases, I have found that everything is supposed to be indexed as expected.”
And it’s not just search engines you need to think about. With the rise of large language models (LLMs) powering AI search assistants and copilots, there’s a new reality: LLM crawlers don’t render JavaScript either. They typically consume the raw HTML of a page. So if your content only exists after JS execution, you’re invisible not just to Googlebot but to AI-driven discovery too.
That makes JavaScript SEO more critical than ever. Testing what’s in your raw vs rendered output, making sure your core content and links exist in HTML, and spotting bloated bundles or hidden navigation isn’t optional. It’s survival.
So don’t wait for rankings (or AI visibility) to slip before you act. Crawl it. Render it. Compare it. Fix it. Because until both Google and LLM crawlers start executing your JavaScript perfectly (don’t hold your breath), auditing JavaScript SEO isn’t going anywhere.
Try out Sitebulb's JavaScript crawling
If you're looking for a way to crawl and render your own JavaScript site, you can download Sitebulb here, and try it free for 14 days.
You might also like:

Patrick spends most of his time trying to keep the documentation up to speed with Gareth's non-stop development. When he's not doing that, he can usually be found abusing Sitebulb customers in his beloved release notes.
Related Articles
 AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean
AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean


 What AI Agents See: The Accessibility Tree Is an SEO Surface
What AI Agents See: The Accessibility Tree Is an SEO Surface
 The Brand-First Technical Audit: Why Your Entity Health Is a Technical SEO Problem
The Brand-First Technical Audit: Why Your Entity Health Is a Technical SEO Problem

 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.