

 Ashleigh Noad
Ashleigh Noad
Ashleigh Noad, Senior SEO Consultant at BuiltVisible, takes us through the risks of relying on JavaScript for internal linking and best practices for link crawlability.
The role of JavaScript in the SEO industry has long been a divisive topic among digital marketers and developers alike. Chances are that you have heard opinions ranging from wholehearted endorsement to staunch criticism, with the reality being somewhere in the middle.
This article sheds light on the nuanced relationship between SEO and JavaScript, with a focus on internal links. I’ll answer questions like, can Google crawl JavaScript links, and is JavaScript bad for SEO?
The objective is to help empower those working in or collaborating with SEO teams to identify and address common JS challenges. In turn, this will also highlight considerations that can help determine the potential impact of having internal links available in the HTML versus the rendered DOM.
Interested in learning about JavaScript SEO? Sign up for our free on-demand JavaScript SEO training course. Register for the course
Contents:
- Is JavaScript bad for SEO?
- Can Google crawl JavaScript links?
- Recap: How Google processes JavaScript
- What if a whole website relies on JavaScript?
- Internal linking and crawlability: best practice
- How to check if a web page has JavaScript links
- Considerations for JavaScript links
Is JavaScript bad for SEO?
Yes, it is true that some uses of JavaScript can be detrimental to SEO performance. This can often be the case for websites who rely on JavaScript to generate entire webpages or to inject important on-page elements.
But there are a lot of uses of JavaScript which enhance interactivity and make for great user experiences – and often they do not have a detrimental impact on organic performance.
…Ok, but can Google crawl JavaScript links?
The simple answer is “not reliably". For internal links relying on JavaScript, the most common challenges can be broadly categorized into two groups:
- Inability for search engines to discover the internal links at all
- Inability for search engines to reliably and efficiently crawl internal links
In order to identify and propose potential solutions, we first need to have an understanding of how search engines process JavaScript and what their limitations are.
This article will mostly refer to Google’s process for understanding and rendering JavaScript. Although thought to be more limited in their rendering abilities, these principles will also apply to Bing-powered search engines.
Recap: Google and JavaScript processing
Google has provided guidance to help us understand the three different phases required for how Google processes JavaScript: crawling, rendering and indexing.
However, you will often see this process summarised as having ‘two waves of indexing’ because Google’s three phases are not linear.
I would recommend reading Google’s official documentation to fully understand the rendering process, or this Sitebulb article on JavaScript indexing, but for a quick reminder, you can follow a recap below:
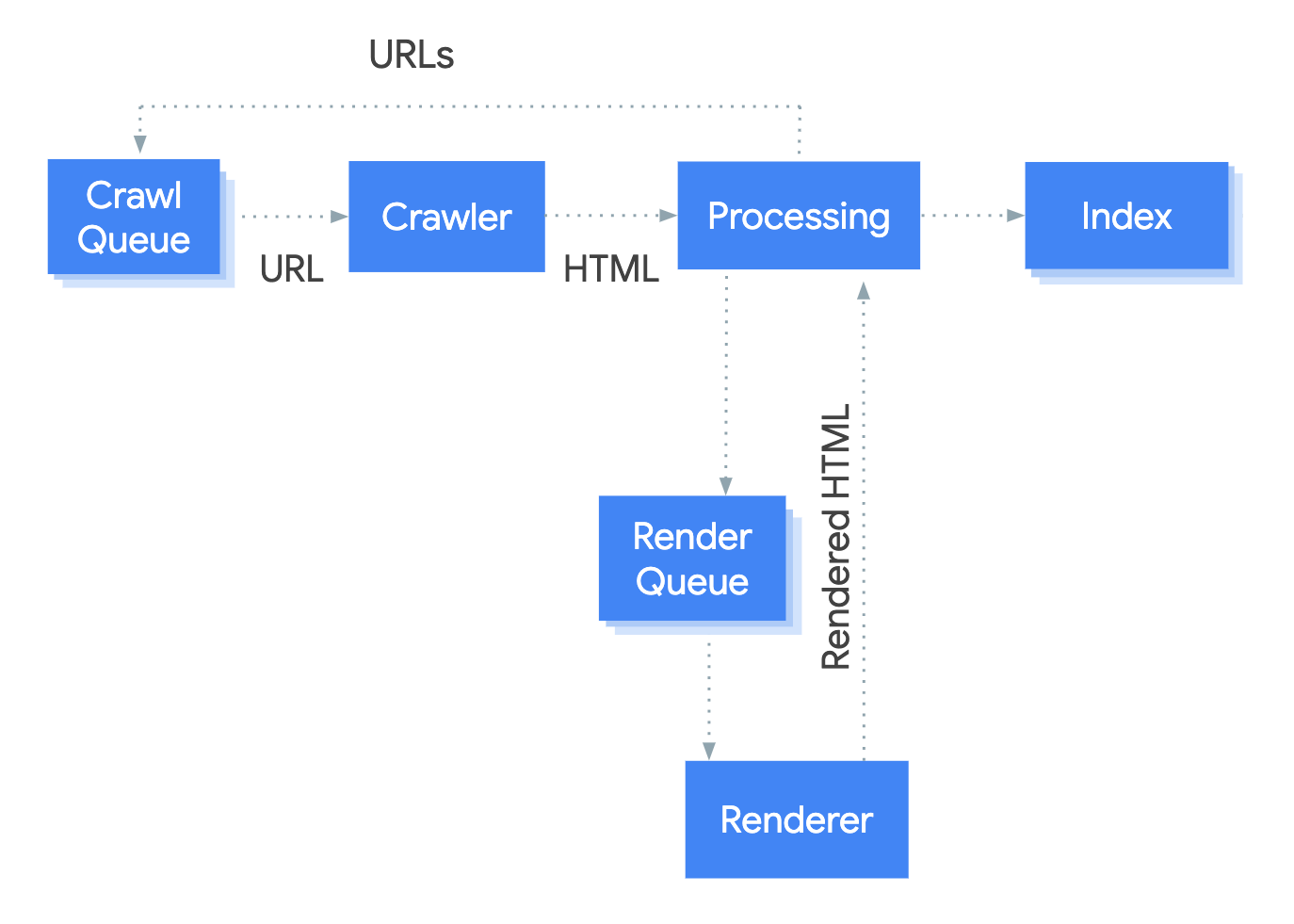
Image credit – Google Search Central.
First wave of indexing: HTML only
- During the first phase, Google discovers URLs from internal sources (e.g. sitemaps and internal links) and external sources (e.g. links from other websites) and puts them in a crawl queue.
- Providing a URL is accessible to Google, the Google crawler requests the page in an HTML format from the server.
- These URLs can then be indexed but will also go into the Render Queue.
- Any newly discovered links from the HTML will go back into the Crawl Queue.
The delay between waves…
- A URL may sit in a render queue from anywhere between a few seconds to days before it is fully rendered.
Second wave of indexing: now with JavaScript rendering!
- If a page is not eligible for indexing because of a NoIndex in the robots meta tag or header, Google will not render the page.
- For eligible pages, Google will request the URLs to be rendered in Chromium and will execute JavaScript.
- The final rendered page is then also eligible to be indexed.
The outcome
There are various industry studies aiming to identify how long Google takes between the first wave and the second wave of indexing. The results are always different and will be unique to every website.
Ultimately, it is this delay which has given JavaScript a bad reputation in the SEO world. Google’s resource for rendering JavaScript is not infinite. For large JavaScript-heavy websites, this has potential implications on crawl budget as well as creating an inefficient process for Google to understand site architecture. For others, this may cause delays when trying to index updated content.
As a result, general best practice for JavaScript SEO dictates that anything which is considered critical or important to Google’s understanding of a webpage should be available in the raw HTML. More on this later.
Wait – what if a whole site relies on JavaScript?
If you are finding that a site relies 100% on JavaScript to be executed in the browser to be functional – also known as ‘client-side rendering’ - you could be working with a Single Page Application. This article is not going to cover types of rendering or solutions, but a good starting point would be Google’s Rendering on the Web guidance.
The below assumes a form of hybrid rendering functionality – the potential ability to ‘pick and choose’ which elements should be available in the HTML versus which are okay to be rendered via JavaScript.
Internal linking and crawlability: best practice
Before we start considering JavaScript links specifically, we should establish what makes a link discoverable* and crawlable for Google, regardless of when Google discovers a link.
For any link to be crawled, it needs:
- To be contained in a <a> HTML element or ‘anchor element’
- To have an Href attribute
- To be available to search engines without requiring an event trigger or interaction**
- To use an absolute (a full URL) or relative URL (contains the path only)
- Any associated JavaScript files used to generate the link cannot be blocked for search engines in the robots.txt file
Examples of crawlable internal links
An example of an internal link which can crawled:
<a href="https://www.ilovehtml.com"></a>Another good example:
Although there seems to be a bit more going on this example, there is still an href attribute enclosed in a <a> HTML element so Google will be able to crawl this link.
Examples of non-crawlable internal links
Now for a few examples of internal links which cannot be crawled.
Bad example #1
{name:"category",url:"/im-a-url"}Although there is a relative URL, there is no <a> element or href attribute, so this internal link would not be crawlable.
Bad example #2
<a href="JavaScript:goTo('checkout page')">There is an <a> element and href attribute but there is no absolute or relative URL.
Bad example #3
<a onclick="goto('https://example.com')">There is an <a> element and an absolute URL but there is no href attribute.
You get the idea!
*The caveat: Google and non-crawlable links
The big caveat here is that Google may try to request anything it thinks might be a link.
So from a discovery perspective, Google may see an improper link and try to request it anyway. But it won’t consistently request the URL, recognize the internal link itself, understand its anchor text or its surrounding context on the page.
As a result, these internal links don’t provide Google any insight into the site structure or pass on link equity to its destination – in other words, they aren’t valuable or reliable for SEO.
**Watch out for links relying on event triggers or interaction
Search engines can’t interact with web pages in the same way a user can. Google cannot hover or click on the page, so any links which are only rendered after an on-click JavaScript event or any kind of interaction will not be seen by search engines at any point during the rendering process.
This is becoming increasingly common for main navigations. Often this decision is made to improve load times by reducing the size of the rendered DOM for the initial page load. However, choosing to do this will mean the main navigation is not useful for passing link equity and for some sites, linked URLs potentially run the risk of not being discovered.
How can I test to see if a web page has JavaScript links?
Manual check
If a link is not present in the HTML or ‘Source Code’ (ctrl+ u for Windows users), but appears in the rendered DOM or ‘Inspect Element / DevTools’ (ctrl+shift+I for Windows users), this would suggest a link has been created via JavaScript.
Example:
If the internal link /en-gb/im-an-example-product-link can be found in Inspect (below) but you cannot Find (via ctrl+f) it in the Source Code, this suggests the link has likely been rendered via JavaScript.
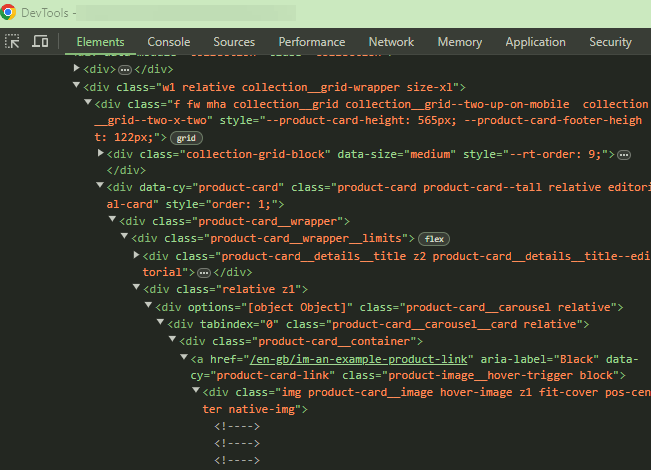
Source code – not found!
Use a crawler
You can also use a website link crawler to identify JavaScript links. These have the added benefit of grouping together elements into tables and visualizations, so you don’t have to manually compare the two versions.
If you’re already using Sitebulb and want to check for JavaScript links in a project, you can follow Sitebulb’s guidance for finding JavaScript links.
You can also use Sitebulb’s Single Page Analysis tool to flag for JavaScript links at the page level.
Start by selecting Single Page Analysis in the top ribbon and entering the URL you want to check.
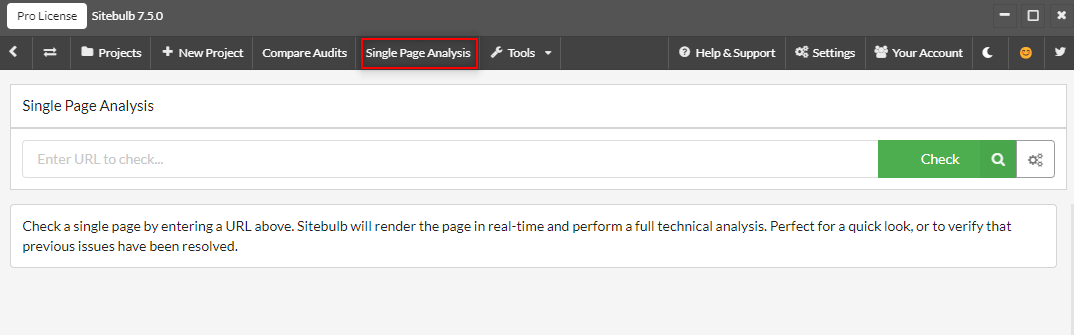
You can then see a summary of Internal Links in two different views. The first, is in the tab Response vs Rendered > Links
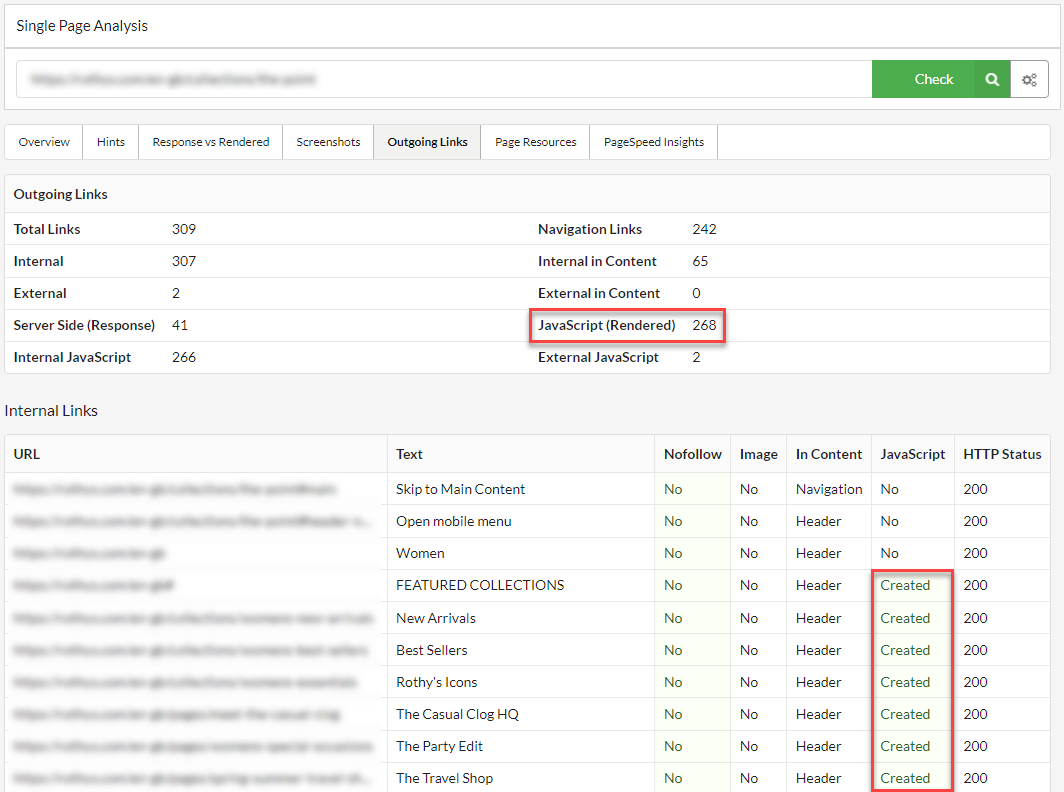
This compares the raw HTTP Response (left-hand side) against the rendered DOM (right-hand side), the latter showing which links have been rendered in JavaScript.
Note: If a link requires interaction or an event trigger to render, Sitebulb will act in the same way as Google and not see or report on the JavaScript link in the rendered DOM.
You can also see a summary of Server-Side (HTML) versus the Rendered DOM in Outgoing Links. The explorer table below will also allow you to see more information about the internal link, including where the link was found in the DOM (In Content).
Considerations for JavaScript links
Before raising the alarm with developer teams to change links rendered in JavaScript – it is important to consider their priority level in line with other SEO items in your roadmap as well as the potential impact of the change. Not all internal links have the same ‘value’.
If everything is a high priority, nothing is!
For example, advocating to change a JavaScript link module that only links to Non-Indexable pages will likely not result in a benefit for organic performance.
For developers with lots of competing requests, pushing for this change without being able to explain a performance benefit, may actually damage the relationship between SEO and developers in the long term.
When you’re trying to decide whether an internal link or module should be available in the raw HTML rather than rendered by JavaScript, there are a couple of different questions to help contextualize its role in the site structure and also determine where they should fit in your SEO roadmap, if at all.
1. How important is discovery?
If the internal link or module is one of few ways for Google to discover an important page, these link(s) may be of critical importance to have available in the raw HTML.
Examples:
- A news website that needs its new pages discovered and indexed daily
- A large ecommerce website that frequently updates its Product Listing Pages with new products
However, for others, providing that there is no event trigger or interaction requirement blocking page discovery completely, a delay in indexing in new pages won’t lead to lost revenue or a significant drop in KPIs.
2. How important is link equity?
Internal links can be leveraged as a powerful ranking factor. If JavaScript is required to render particular internal links, this means Google will have a harder time understanding the relationships between source and destination pages.
Every time Google discovers new links, this will alter how Google understands a site’s structure and determines the relative importance of pages within the site architecture. You may also hear this referred to as hindering or diluting the flow of link equity.
Examples of links that would benefit from being in the HTML:
- Internal links in a faceted navigation
- Main navigation links pointing to key category pages
- Links from Product Listing Pages to product pages
- Pagination links
- Breadcrumbs
On the other hand, some destination pages simply don’t need link equity to boost performance, so having these links in the raw HTML may be a lower priority – or not something that needs to be changed at all.
This will often be the case for pages that are already indexed and only need to rank for particular branded terms.
Examples:
- Links from product pages to a brand delivery information page
- A link to Non-indexable ‘my account’ pages in Headers and Footers
- Links to personalized or members-only pages
And lastly, a call out for migrations
In a migration without rendering changes, we typically expect ranking turbulence, as Google will need some time to understand any template changes and potentially a new site structure.
But changing important internal links from being available in the HTML to relying on client-side rendering will make any potential recovery even slower, due to compounding delays between the first and second wave of indexing.
Therefore advocating for key internal link modules or components to remain rendered server-side should be a top priority for any migration strategy.
In summary
JavaScript SEO and internal linking doesn’t have to be daunting. Identifying critical internal links needed to drive organic performance and understanding how Google renders JavaScript – and its limitations – can empower SEOs to advocate for potential changes and determine their priority within wider SEO roadmaps.
You might also like:

Sitebulb is a proud partner of Women in Tech SEO! This author is part of the WTS community. Discover all our Women in Tech SEO articles.

Ashleigh is a Senior SEO Consultant at Builtvisible with 7+ years of experience in SEO. With experience in both agency and in-house SEO, she is primarily focused on enterprise SEO and technical SEO for Ecommerce. Outside of work, you can find her planning her next travel adventure or telling anyone who will listen that she used to work at Disney World.
Related Articles
 Technical SEO Considerations for Local Businesses and Local Rankings
Technical SEO Considerations for Local Businesses and Local Rankings

 Technical SEO for Healthcare: Boosting Visibility, Compliance & Trust
Technical SEO for Healthcare: Boosting Visibility, Compliance & Trust

 How to Optimize Your Crawl Budget: Insights From Top Technical SEO Experts
How to Optimize Your Crawl Budget: Insights From Top Technical SEO Experts

 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.