How to Support your Deployment Workstream with a Crawling Strategy
 Katie Cunningham
Katie Cunningham
Published October 29, 2024
This week, we’re grateful to Katie Cunningham for her insights into how SEO can support website deployment via lower environment crawling.
Most websites with a consistent agile deployment schedule work on a unique cadence where they deploy code to a lower environment for Quality Assurance (QA) before pushing the code to production. SEO can proactively support these deployments by QA-ing lower environments to check for issues before things go live. This helps SEO catch when pages break or content changes prior to launch, or larger issues immediately after launch.
Implementing a crawling strategy and process around these deployments can result in better working relationships with technology, improved understanding of technical SEO issues, and proactively capturing issues to limit hot-fixes or negative business impacts. I’ve caught issues such as noindexing all product pages, blocking a full site in the robots file, and 404ing a full section of a site just by having a recurring crawl cadence.
Contents:
- Understanding different environments
- Benefits of adding crawling to your deployment workstream
- Best practices for lower environment crawling
- Monitoring ongoing crawling
Understanding Different Environments
Different environments are essentially different subdomains where code can be run and tested.
The primary distinction lies between what environments are accessible to external versus internal users. By having distinct environments, organizations can ensure the quality and stability of their software before releasing it to the public.
What is a Lower environment?
Lower environments are used for development, testing, and QA. There could be one lower environment or there could be multiple. Work with your technology team to identify what exists and what the domain structure is. Some people refer to do these as staging or sandbox environments but that doesn’t mean the URL structure matches the naming.
Here are a few examples:
Sandbox.example.com
Dev1.example.com
Qa.example.com
What is a Production environment?
Production is the live environment where the domain or system is accessible to end-users.
www.example.com may be the production environment in the example above.
Benefits of adding Crawling to the Deployment Workstream
Websites are living platforms with content and code regularly changing.
Deployments don’t happen in a vacuum and can impact other workstreams. I’ve lost count of the number of times I’ve found issues from code being deployed that changed something unexpected. This has led to pages getting deindexed, losing rankings, and at worst losing revenue and leads, impacting the bottom line.
It’s our jobs as SEOs to set up workflows so that we can proactively catch these issues before they become larger problems. A big part of that is learning to work with the development teams and working our reviews into their current processes.
Best Practice Process for Lower Environment Crawling
1. Set up a process with the team
First, work with your technology team or partners to get documentation about the deployment schedule and any environments you need to understand. Ask to be included in any documentation and to get an understanding of what the current QA process is so that you can be a value add to the process.
Some sites work on a specific timely cadence (i.e. every other Wednesday) and for others it is based on when requirements are met to warrant a deployment.
Clearly document what it looks like for a lower environment to be ready to stage and how to be part of the communication for when it’s ready to be reviewed.
2. Set up a staging crawl
Once you have your information and can map out what the cadence could look like, you will then need to set up a crawl for your lower environment and one for your production environment. If you have a very large site, requiring an enterprise-level crawler, you may need to set up separate projects in case you have to QA different areas, such as subdomains or certain folders that have different requirements.
Some questions to ask:
- Do you want to crawl all pages or just a certain folder or subdomain?
- Does your lower environment have all pages you would expect on the production environment?
- Does your lower environment have an XML sitemap, or will there be pages missing because one doesn’t exist?
Set up a test crawl for both projects and play with the settings to finalize what you want to see from the crawls. You may need to set up a specific configuration for your staging environment so that it can bypass authentication or ignore robots.txt.
How to Set up a Staging Crawl in Sitebulb
- Set up a new project for the right lower environment
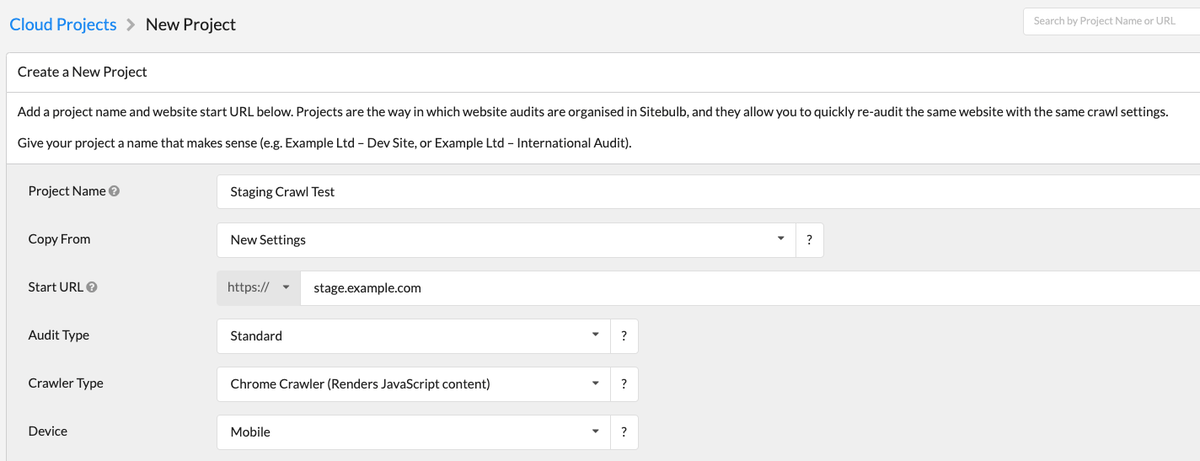
Tip: You can copy project settings from another crawl if you already have some requirements from your production crawl that you want to replicate or start with new settings.
- Under Robots Directives, select that this is a staging site so it will ignore the robots.txt file. If you also have noindex or nofollow you should uncheck the “Respect all Robots Directives” so it ignores those and can crawl nofollow links.
- Set up authentication if needed – follow this article to learn how to set up that properly, so Sitebulb can bypass your authentication requirement.

- Set up any other customization you need, such as user agent, crawl speeds, crawl limits, URL inclusions/exclusions, and audit data and sources.
- Schedule the crawl to run or let it start now so that you can see if your settings work.
- Analyze and adjust the crawl until it fits the requirements you expect.
If your site is big and you need help figuring out some crawling settings, then check out this helpful article on how to crawl a large site.
3. Document your crawls for future reference
Take all your inputs and create documentation about what you would expect to see on the different environment crawls.
You may have variation between the staging and production environment due to differences in how the crawler can find pages between crawling, analytics, GSC and XML sitemaps. It’s less about 1:1 matching production to staging crawl and more about crawling each regularly to monitor and check for differences during ongoing deployments.
Example Documentation
|
Project |
Inclusions |
Est. Size of Crawl |
Limit in Tool |
Schedule |
|---|---|---|---|---|
|
Production Crawl |
All HTML internal links only XML Sitemap GSC integration |
18,000 |
20,000 |
Weekly on Thursday at 1am |
|
Staging Crawl |
All HTML internal links only No XML Sitemap |
12,000 |
20,000 |
Biweekly, adjust as needed based on deployment email |
For example, I know that for my main site can’t get all of a subfolder crawled because of some limits with parameter URLs and we don’t have an XML sitemap to provide all staging URLS to check. But in the production environment, we do have an XML sitemap that can be fully crawled, so it finds more pages to report.
Sitebulb has recurring schedules that you can set up for each project but if your deployment isn’t on a set timeframe you can always go in and adjust dates to be flexible. For example, I get an email when the lower environment is ready for review and that is my trigger to ensure our crawl gets scheduled to align with the dates. But deployment is generally on the same day, so I tend not to have to adjust that unless a holiday or something changes the date.
Once you have your expected outcomes you can set up regular checks to ensure you are monitoring the data over time.
Monitoring Ongoing Crawling
Recurring crawls mean nothing unless you are monitoring them. Creating a process to analyze the data on a regular basis and understand how to act on that data is critical to ensure you are finding issues and solving them.
4. Establish a checklist to complete after each stage of deployment
Now that you have recurring crawls that align to your deployment cadence you need to be checking the data and monitoring for things to escalate.
Creating a full checklist can ensure every item is reviewed and checked off with documentation in case it needs to be referenced in the future.
My team likes to use the crawl comparison tool to compare previous crawls to new ones to see where changes have occurred, then dive into the project to check for top Hints.
We also have key page templates documented with examples to go through a checklist to look for things such as metadata, canonical, robots, and page content to ensure we are looking at these pages from a user’s perspective.
5. Have an escalation plan
Working on a website means not everything goes right and you need to know who to contact when things go wrong. Have documentation of who to alert in your technology team about issues and know what type of communication they prefer.
It also helps to have a level of importance for the issue. I like using a stoplight mentality to help understand how important the issue is. Ideally these get caught in a lower environment but sometimes things do make it to production and when that happens you might be requesting a hot-fix.
Hot-fixes are pushes to production with code that is outside of the regular sprints. These are expensive and take resources to not just fix the problem but go through all the needed QA again. Development teams tend not to want to do these unless it’s business critical, and requesting these when it’s not needed could hurt relationships.
RED FLAGS (Urgent & Business Critical)
Immediately alert your development team and see if a hot-fix should occur. Hot-fixes do require a lot of development resources, so be certain you need one before requesting one.
Examples:
- Made key pages non-indexable through robots or canonical tags
- Blocking pages from bots
- Stopped key pages from rendering
- Broken internal links or navigation to key pages
- Loss of critical site functionality
- Changed URL structure without redirects (needs immediate redirect plan)
YELLOW FLAGS (Important, Not Immediately Business Critical)
Work with your development team to get these tickets in and prioritized. Be prepared with the potential impact to get these into the front of the development backlog. Identify if you can short term do anything manually in your CMS before a development fix gets in.
Examples:
- Removed meta data or key page content
- Broken internal links or navigation to lower priority pages
- Slower page load time on key pages
- Missing canonical tags
- Structured data errors to Schema that provide rich results
GREEN FLAGS (Should Be Fixed, Not Urgent)
Work with your development team to get these tickets in and prioritized, knowing it might take a while to get into the queue. Identify if you can short term do anything manually in your CMS before a development fix gets in.
Examples:
- Minor changes to heading and meta data on less critical pages
- Slower page load time on less critical pages
- Linking to a redirect URL
- Broken imagery or missing alt text
Note: The severity of an issue depends on the specific website and its goals. A broken link to your top category page is more critical than a broken link on an old blog post. Take this list as a starting point and adjust to your needs.
Conclusion
By integrating lower environment crawling into your deployment workflow, you can proactively identify and address issues before they impact your live site. This not only strengthens collaboration with developers but also minimizes negative SEO consequences and business disruptions.
Now that you have a plan in place to monitor both lower and production environments, a checklist to review the data, and an escalation plan, you can work closer with your technology team to improve your working relationship and shift from being reactive to proactive for your site.
You might also like:

Sitebulb is a proud partner of Women in Tech SEO! This author is part of the WTS community. Discover all our Women in Tech SEO articles.

Katie is an Organic Search Director at VML, an international advertising agency. She has over a decade of experience leading data-driven and audience focused SEO strategies for enterprise organizations. She is passionate about data analysis, technical SEO, and SEO training and mentorship. In her spare time she’s playing with her toddler and working on a her latest recipe.
Related Articles
 Silo-Busting: Integrating SEO into Dev and Design Workflows
Silo-Busting: Integrating SEO into Dev and Design Workflows

 SEO & UX: Organic Growth via “The Retention Ladder”
SEO & UX: Organic Growth via “The Retention Ladder”

 AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean
AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean

 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.