
 Wayne Barker
Wayne Barker
Duplicate content comes in many different guises, and various degrees of malevolence. Some isn't so bad, but other types are just downright nasty and a true enemy of SEO!
In this guide, we're going to look at both external and internal duplicate content issues. We'll look at what duplicate content actually is, what causes is, how to find it on your own website, and then how you can fix it. All with a large side-dish of film metaphors.
Oh, and given how much has changed since I first wrote this guide back in 2021, there's now a section at the end on what duplicate content means for AI search. Because GEO.
Thanks to Liz Bowers from the Women in Tech SEO community who gave me some fresh 2026 thoughts to include.
Table of contents:
We all love films, right? Well, pretty much all of us. And most of us will have seen some classics over the years.
But have you ever come across films put out by production company The Asylum? No?
They have released some absolute gems over the years.
Some of those titles sound kind of familiar, right? That’s because they specialise in rip-offs of popular films. They aren't the only production company that does this - some also create posters and other promotional material intended to dupe the consumer into thinking that they are buying the original article.
My mum even owns a few of them and gets confused every time it happens.
These production companies often end up in trouble, but the ROI must be pretty decent because they keep pushing them out.
“What has this got to do with SEO and auditing?” I hear you cry. Well, it's a bit like some aspects of duplicate content - specifically the external duplicate content that can get you in trouble.
Tenuous, I know.
Let me embrace my interests.
I find clients can quickly grasp the idea of external duplicate content and why it's bad (hence The Asylum reference) but struggle to understand the internal duplicate issues and how that can impact their SEO success.
So let’s get stuck in - with more tenuous links to the world of movies.

What is duplicate content?
It’s pretty much what it sounds like - and if you’re reading this, you probably have a good idea of what duplicate content is. In the spirit of clarity, though…
Duplicate content is when you have a block of content on one webpage that is identical or almost identical to another webpage on the wonderful Internet.
Duplicate content is almost unavoidable. It happens, and it’s natural - but that doesn’t mean you shouldn’t keep an eye on it and mitigate it as much as possible. Google ain’t perfect, you know.
There are two types of duplicate or near-duplicate content that you need to know about.
Internal duplicate content
Internal duplicate content is when you have more than one page on YOUR site that is identical or almost identical to one (or more) other pages on your site.
External duplicate content
External duplicate content (often referred to as cross-domain duplicates) is when you have a page on your site that is duplicated on one (or more) other domains. These sites might belong to you, but in many cases, they don’t.
Why is duplicate content bad for SEO?
While there is no such thing as a duplicate content penalty as far as Google is concerned (see the section below where I definitely lay that myth to rest). For like, forever.
So why is it bad for SEO?
Google don't want lots of similar pages in their search results. So they apply a filter to pages that contain duplicate or near-duplicate content, and return only the page that they deem to be the canonical or 'true' version. But that doesn’t mean Google always gets it right.
In addition, you may find that some of the pages that are essentially duplicate, are ones that you want to appear in the search results - and if Google is filtering those out, you are leaving traffic on the table.
It’s bad for SEO because it can lose you traffic, and in turn, revenue.
“Stardom equals financial success and financial success equals security.”
Steve McQueen
Duplicate content in AI search
Here's one that's changed since this guide was first written.
Traditional search picks a winner and filters the rest. Annoying when it picks the wrong one, but manageable - your page drops down the results, or a syndicated copy outranks the original for a while.
AI search is less forgiving. When an AI system generates an answer, it selects one page to ground that answer in. Your duplicate pages don't appear at all.
There's a full section on what this means in practice at the end of the guide.
Is there such a thing as a duplicate content penalty?
Let's bust this SEO myth right here and now (although it has been busted many times before).
It still keeps coming back like Jason in the Friday the 13th movies.
There's no such thing as a duplicate content penalty when it comes to content on your site.
Let’s go straight over to the lovely fella that is John Mueller for confirmation on this.
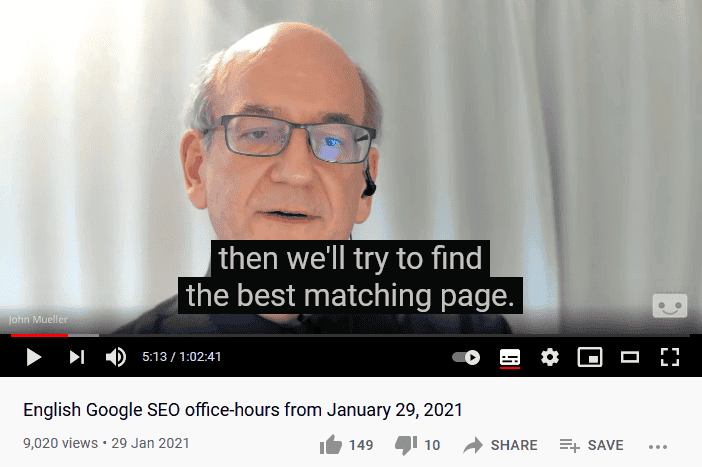
“With that kind of duplicate content [John was referring to duplicate header and footer content] it’s not so much that there’s a negative score associated with it. It’s more that if we find exactly the same information on multiple pages on the web and someone searches specifically for that piece of information, then we’ll try to find the best matching page.
So if you have the same content on multiple pages then we won’t show all of these pages. We’ll try to pick one of them and show that. So it’s not that there’s any negative signal associated with that. In a lot of cases, that’s kind of normal that you have some amount of shared content across some of the pages.”
John Mueller, Google SEO Office Hours, 2021
What about product pages?
“A really common case for example is with ecommerce. If you have a product, and someone else is selling the same product, or within a website maybe you have a footer that you share across all of your pages and sometimes that’s a pretty big footer. Technically that’s duplicate content but we can kind of deal with that. So that shouldn’t be a problem.”
John Mueller, Google SEO Office Hours, 2021
There you go. It shouldn’t be a problem.
So scraping and copying content is fine then?
Stealing is (mainly) a bad thing. Mainly? In reality, nothing is new but there is a massive difference between theft and what Austin Kleon calls “Steal Like an Artist ''.
“Nothing is original. Steal from anywhere that resonates with inspiration or fuels your imagination. Devour old films, new films, music, books, paintings, photographs, poems, dreams, random conversations, architecture, bridges, street signs, trees, clouds, bodies of water, light and shadows. Select only things to steal from that speak directly to your soul. If you do this, your work (and theft) will be authentic. Authenticity is invaluable; originality is nonexistent.”
Jim Jarmush, MovieMaker Magazine, 2004
Scraped content, on the other hand, is just theft, no remixing. Not using other content as a springboard. As such, it doesn't belong in Google's search results.
Here’s what Googler, Andrey Lipattsev said when he tried to differentiate between the different types of duplicate content:
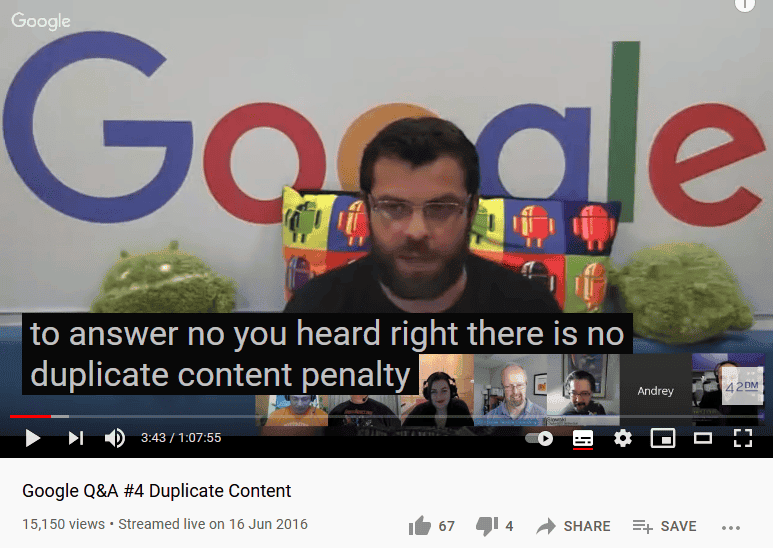
“You heard right there is no duplicate content penalty… I would avoid talking about duplicate content penalties for spam purposes because then it’s not about duplicate content then it’s about generating in a very often in an automated way content that is not so much duplicated as kind of fast and scraped from multiple places and then potentially probably monetized in some way or another…”
Andrey Lipattsev, Google Duplicate Content Q&A, 2016
There. Is. No. Duplicate. Content. Penalty.
What are the causes of duplicate content?
Now there's a question. There’s loads. Let's take a quick trip through some of the most common ones you are likely to encounter when auditing sites. I’ve broken them down into two main sections, firstly what we’d consider to be ‘true’ duplicate content, and then duplicate URLs, which tend to be more of a technical issue.
Duplicate content
True duplicate content is where the same, or similar content appears on multiple pages. Here are some of the most common examples.
Indexable filters
Aaaargh. This one can be tough to unravel and is most common on ecommerce sites.
If you run an ecommerce site - or have ever worked on one - you will understand the importance of filters. They help users navigate categories and view only products of interest.
They are crucial for ecommerce sites.
What's a pain in the arse, though, is when the site doesn’t deal with the fact that filters can create loads of indexable duplicate pages.
What do these kinds of duplicate URLs look like?
https://tomranks.com/category would be your main category page.
But as the user starts to click through, then these sorts of pages can start to appear:
https://tomranks.com/category/?brand=niceguy
And when you add more, it can start to look like this:
https://tomranks.com/category/?brand=nice?seo=no?prduct=3423424
It's easy to see how this can grow exponentially, and you can end with more indexable pages that you know what to do with.
Further reading:
Indexable search pages
This is another form of duplicate content that I come across regularly. This kind of duplicate content is created when you have a search function that creates a new page and serves it as a 200 status code.
It usually looks a bit like this:
https://markupwahlberg.com/?search=onedecentfilm
The issue here is that most search result pages are very similar, and the volume of searches (and therefore pages) is potentially infinite!
Boilerplate content
Boilerplate content refers to the content that appears on most - if not all - of the pages on your site. Most commonly, this is the content in your header and footer.
Here's a couple of examples. If you run a blog then you’re going to have the same bio for writers across many pages.
And pretty much every site on the Internet has duplicate content across every page of the site because navigation content sits on many pages.


As mentioned earlier in this guide, you can almost definitely assume that Google can deal with this content and understand that it’s necessary for a good user experience.
My advice - don't worry about this kind of duplicate content.
Product description content
Duplication on product pages is very common. For years most ecommerce sites have used the product descriptions that the manufacturer provides.
There are a few reasons for this:
It's easier
Sites often have hundreds if not thousands of products, and it's a hell of a task to write unique content for them
They don't know how to prioritise which products they should write unique copy for
Sometimes competition is so tough there is little ROI to justify it
Whether it’s worth dealing with this kind of duplicate content is more nuanced than a simple yes or no. It depends on your vertical, what the competition is up to, the budget you have and what else you need to do on the site that might deliver a better ROI.
Let's go back to what our old John Mueller said a few years back:
"We would probably see this as duplicate content but we would not demote a website because of duplicate content. So from a practical point of view, what would happen is if someone is searching for a piece of text that is within this duplicated description on your pages, then we would recognize that this piece of text is found on a bunch of pages on your website and we would try to just pick maybe one or two pages from your website to show."
John Mueller, Google Search Central SEO Office Hours, 2021
Spun content
Spun content? Are people still doing this? The answer is one whopping Steve Austin "hell yeah!".
Does it work? Not so much. Google is much smarter than that nowadays.
By and large ;)
If you've never come across spun content, it's taking content that exists and running it through some software to add synonyms and swap the text up. Not that I ever did that. I still see it being used on product descriptions to this day — although not as much, as the content doesn't surface often on Google.
What does Google have to say on the matter?
"artificially rewriting content often kind of goes into the area of spinning the content where you're just kind of making the content look unique, but actually you're not really writing something unique up. Then that often leads to just lower quality content on these pages. So artificially re-writing things like swapping in synonyms and trying to make it look unique is probably more counterproductive than it actually helps your website."
John Mueller, Google SEO Office Hours, 2015
The same logic applies to AI-generated content at scale. It's a different tool doing a similar thing. Run hundreds of pages through the same prompt without adding anything meaningful and you end up with content that's technically unique but structurally identical — same patterns, same phrasing, same shape. Google's scaled content abuse policy covers exactly this: content generated in volume where the primary purpose is ranking rather than helping users, regardless of how it was produced. That's spun content with a shinier toolset.
The fix is the same as it's always been. Add something the source material doesn't have. Make the page say something worth reading. The method matters less than whether the output is genuinely different.
Placeholder pages
Placeholder pages are typically pages added to a domain before the site goes live—often used to capture email information before a product launch, or at least garner some interest in a product or site.
Over the years, I have seen a few of these where they live on one URL but never get removed and often, they contain a lot of duplicate content.
It might look something like this:
https://johnwayneyb77/launch
The site goes live, and the content on that URL is very similar to that of the finished home page, but the launch page gets forgotten and is left indexable. You’re going to have even more issues if the product launch went well and bagged a load of links from the press cos your product is that flippin amazing.
PPC landing pages
SEO and PPC are different. We know that, right?
Sometimes the pages that exist on a site you are working on are great for SEO but, erm, not always that great for PPC. At Boom, we often create specific landing pages for the PPC team so that we can get the kind of content on there that aids their conversions.
I might not be a PPCer (I tried 10 years ago, and I just ended up in a pit of despair, it just wasn’t my bag), but I’m well aware that the guys often need something different for their traffic to land on.
But...
That often means the content is duplicate or near-duplicate. Always be aware of what other teams are working on and whether they have pages built that can prove troublesome for your SEO.
Content targeted at different countries/dialects
Ah, the classic. You’ve got a website. You’re based in the UK, but you sell around the world. To the US, to Europe (although that’s a little more difficult nowadays) and a whole bunch of other places.
This isn’t the time to talk about International SEO or why it seems so difficult to not only explain how hreflang works, but to get it properly implemented - I’m sure we’ll cover that at a later date.
For now I’ll just say that if it isn’t implemented correctly you could find yourself with some duplicate content issues. While the content *should* be different (yeah, I’ve seen UK content on loads of international pages that hasn’t been translated and it never fails to boil my blood), you do see duplicate Title Tags, Meta Descriptions and product descriptions. All. The. Time.
Content syndication
If you haven’t heard of content syndication before it’s simply working with influencers, other digital publishers and content distribution partners to achieve a greater reach for your content or your products and services.
While getting the extra attention can be good for your brand or business it does come at a price.
Yeah, you’ve guessed - duplicate content.
Often the other sites you work with publish your content. Word for word. Even if you had the content on your site before it was syndicated you could still have issues. Often a lot of these sites are trusted more by Google, and their content can end up getting indexed instead of yours. Grr.
https://arnoldshwarzenggerisatwin.com/amazingballscontent is the content that you created on your site.
But you syndicated it to other sites...
https://dannydevitoisatwin.com/amazingballscontent
And..
https://eddiemurphyisatwinortriplet.com/amazingballscontent
Duplicate URLs
Duplicate URLs are the unintentional presence of the exact same page appearing for multiple URLs. Let’s dig into some examples.
Non-www vs www and http vs https
You’d think that most people would have this one sorted by now, but I still come across it quite regularly. Often due to redirects not being configured correctly.
While Google and other search engines can usually figure this out, it’s a quick fix, so you might as well get it addressed.
It's when you have both the www version of your site and the non-www version of your site live and accessible to search engines..
Like this:
https://spamelaanderson.com
AND
https://www.spamelaanderson.com
The same applies to your secure and non-secure versions of the URLs:
http://spamelaanderson.com
AND
https://spamelaanderson.com
See also:
https://spamelaanderson.com
AND
https://www.spamelaanderson.com
Further reading:
Parameters and URL variations
Duplicate content can also be created accidentally with URL variations. This includes (but isn’t limited to) click tracking, analytics code, session IDs and print-friendly version of pages. While Google is pretty good at sorting this you still need to find and potentially fix this kind of duplication.
Here are a couple of examples filled with super hilarious film puns.
Session IDs
https://alttagpacino/serp-ico?SessID=243432
Is the same as:
https://alttagpacino/serp-ico
Print-friendly versions of pages
https://glennclosetag/print/cookiesfortune
Is the same as:
https://glennclosetag/cookiesfortune
Further reading:
CRM quirks
I covered CRM quirks in a recent post on Sitebulb, so there isn’t too much point going into depth here. But some CMSs do create duplicate content issues out of the box. Handy, huh?
One of the most talked-about is Shopify.
“It’s very important to note that while Shopify creates duplicate content, it does take some steps to consolidate. In the examples below, Shopify does make correct use of the canonical tag to reference what the ranking page should be. This helps Google consolidate these duplicate URLs into one.
However, it’s best practice to not rely on canonical tags, as they are hints as opposed to directives. Where possible, try to eliminate duplicate content completely.”
Chris Long, How To Fix Shopify Duplicate Content
Further reading:
Inconsistent internal linking
We’re all human. We all make mistakes. One common human error = duplicate issue is when we are creating internal links. You have to make sure that anyone on the site is consistent when they are linking, and they are linking to the pages that you want to be indexed and rank. That they’re not accidentally creating duplicates.
And it's not just humans. The tools we use can cause these issues as well. Some CMSs have quirks (as I’ve covered on Sitebulb before). Make sure the tech you use doesn't cause these kinds of duplicate content issues.
What do I mean by this? Let's take a look at some examples.
The page you want to rank is:
https://sigourneydreamweaver.com/alien
Potential issues with internal linking that could lead to duplicate content if it’s linked like this:
https://sigourneydreamweaver.com/Alien
https://sigourneydreamweaver.com/ALIEN
https://sigourneydreamweaver.com/alien/
“That’s It, Man. Game Over, Man. Game Over!”
Private Hudson
Further reading:
Multiple index pages
Sometimes your server might be misconfigured and this can lead to multiple versions of any given page. Keep an eye out for these little rogues when you are auditing sites. They are usually pretty easy to spot once you have crawled your site - they look like this:
https://charliechaplink.com/index.php
https://charliechaplink.com/index.asp
https://charliechaplink.com/index.html
https://charliechaplink.com/idex.aspx
How to identify duplicate content on your website
Now you know most of the ways that duplicate content can appear on your site you’re going to want to know how to find it all, right?
Don’t worry; Uncle Wayne has your back. Let’s take a quick tour through some of the tools to help you identify all the places you might find duplicate content.
Google Search Console
Worth starting here because it's free, it's already in your workflow, and it surfaces duplicate and canonicalisation issues directly from Google's perspective.
The Indexing report (previously Coverage) shows pages Google has excluded from the index - including ones it's identified as duplicates of another URL and ones where it's overridden or ignored your canonical. If Google has quietly decided a different URL is the canonical version of your page, this is where you'll find out. The Pages report also flags "Duplicate without user-selected canonical" and "Duplicate, Google chose different canonical than user" - two categories that tell you exactly how much Google disagrees with your canonical implementation.
It won't give you a full site-wide picture the way a crawler will, but for a quick health check before pulling out the bigger tools, it's the sensible first stop.
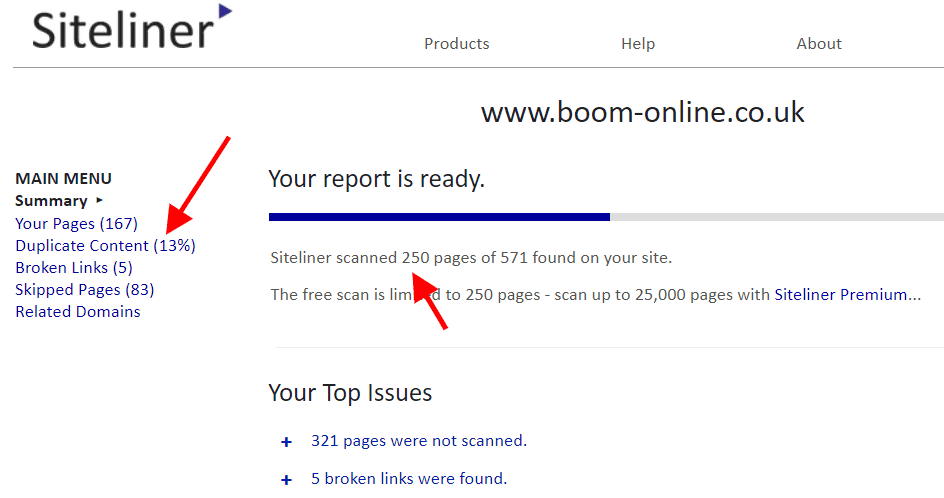
Siteliner
If you’re just getting to grips with finding and fixing duplicate content issues, then Siteliner is a great place to start. Made by the same people that made Copyscape (more on that below), it’s a free site checker and covers duplicate content.
It will only report on 250 pages, but what did you expect for free?
Copyscape
Ah, Good ‘ol faithful. Copyscape has been around for years and is a cheap way of finding duplicate content both on your site and other sites that may have scraped your content. There’s a free version, but the paid version (via credits) is so cheap you might as well get yourself on the premium version.
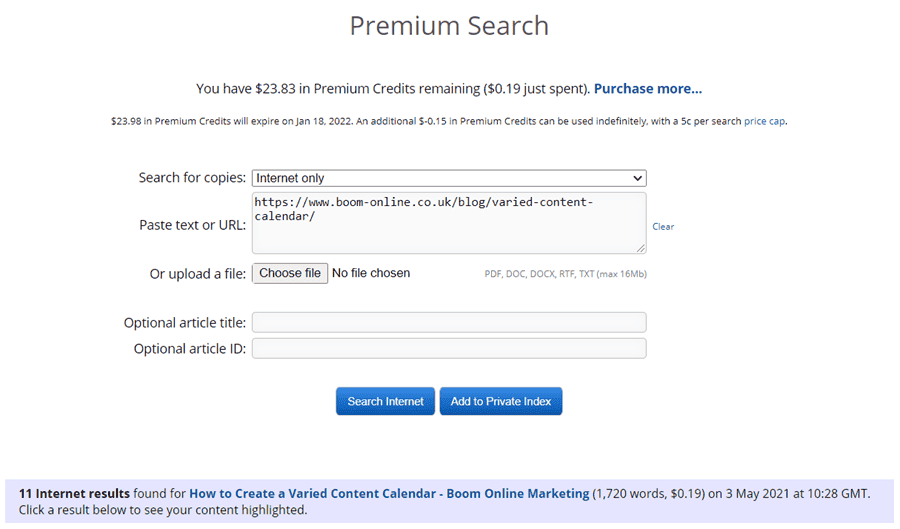
Sitebulb
It would be amiss if I don't mention Sitebulb within here for a couple of reasons.
They pay me a million dollars every time I mention them somewhere
It’s flippin good for identifying duplicate content and is genuinely the tool that I use
Patrick has some shit on me that I don’t want the world seeing
Want to find out how to use Sitebulb for finding duplicate content? Of course you do. Click that anchor text heavy link to get the goodies.
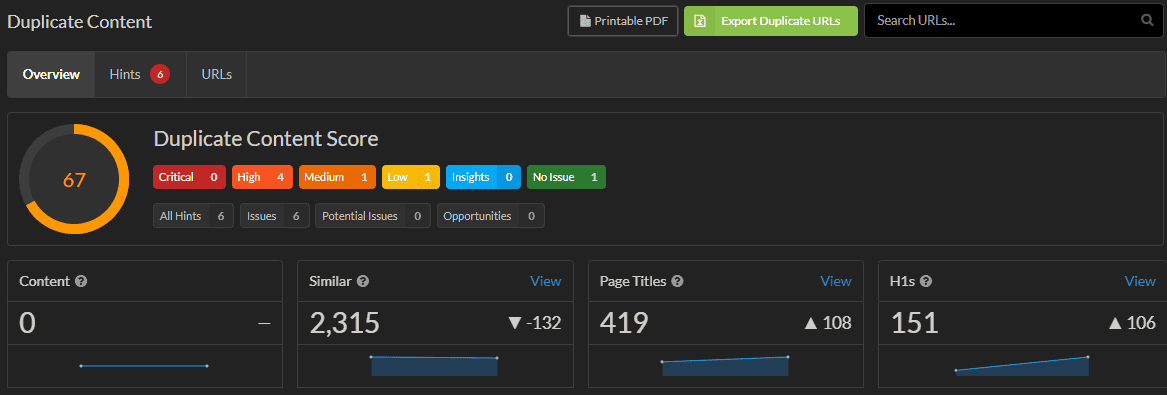
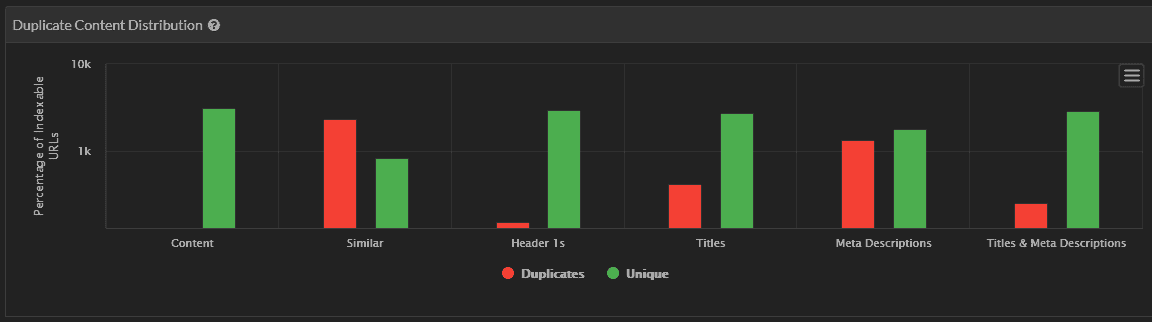
Screaming Frog
Like Frogs more than Bulbs? That's okay with us. We like the guys over at Screaming Frog, and we know that many of you guys will have been using the old Frog for many years (but give us a spin if you want with our super free trial), and it can help you identify that pesky duplicate content.
If you want to check out how to do it, you can click this non-anchor text link here (even I’m not that nice).
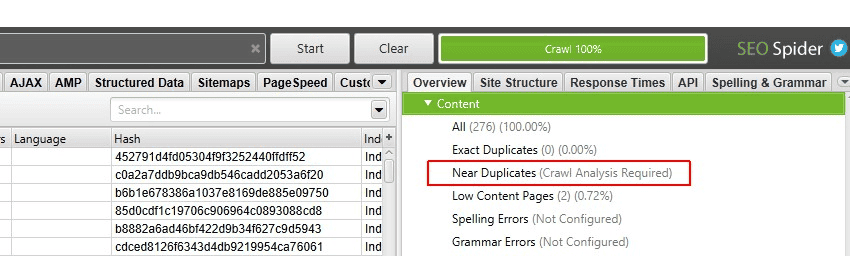
Botify
When working on ecommerce sites, the guys at Boom will use Botify and Sitebulb to check for duplicate content. While it’s a little pricey nowadays it has some excellent functionality for surfacing what you need.
Example site with little duplication:
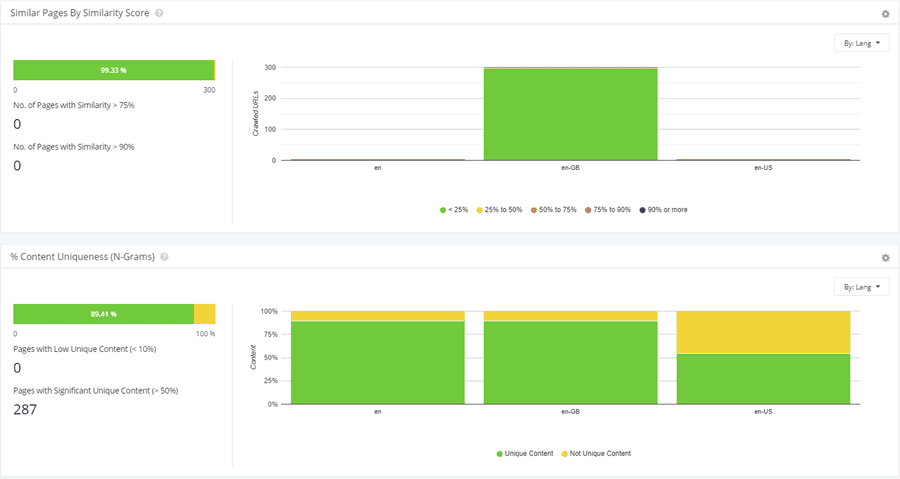
Example site that needs more investigation:
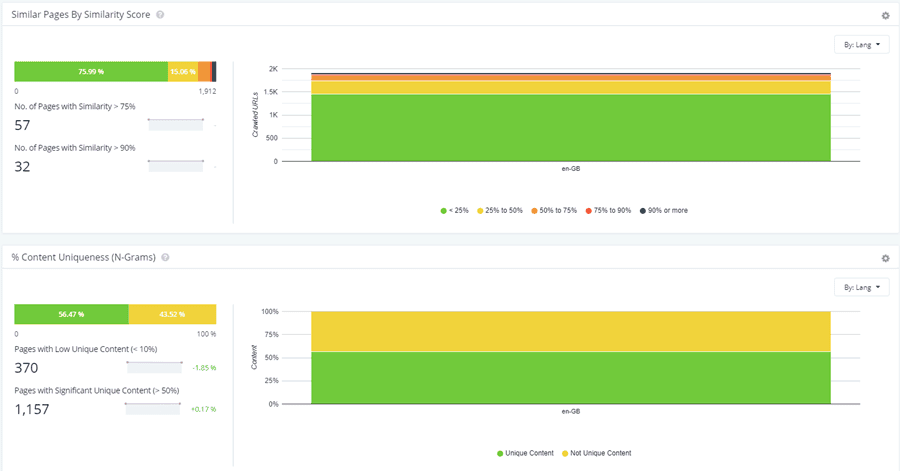
Tools are good, but the tool does not maketh the man (I think it was Marlon Brando that said that - or Barry Adams, I can’t remember), so never forget that you have Google at your fingertips.
They have plenty of pages of the Internet in their index, I believe. Sure I heard that somewhere.
If you need to do some spot checks before setting the tools into action, then you can always take a snippet from your site and add quotes around it to find out what Google serves up.
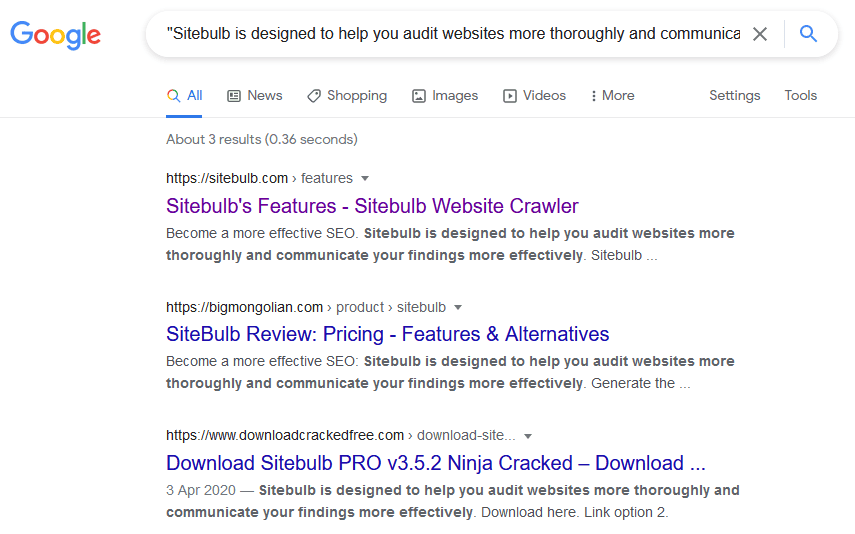
Simple.
How to deal with duplicate content

“SEO/AI Search success isn't measured by how many pages you index, but by how many questions you definitively answer. Consolidating thin or related content isn't 'losing' pages; it’s concentrating your authority into a single, unbreakable source of truth.”
Wow - you’ve made it this far? I’m touched.
Now you know what duplicate content is, what causes it, and how to find duplicate content issues, I bet you want to know how to fix it?
Hold your horses a bit there, John Wayne. Before we get to the technical implementation fixes, we need to look at how you deal with it - that’s what leads you to apply the right technical fix.
It's also worth noting that sometimes you might be best just doing nothing. That makes life easy right?
Maybe you have a small site with only a few issues and Google has already figured out your duplicate content issues.That’s all cool, you don’t have to fix something that Google has figured out for itself. That said, it's always worth keeping an eye on issues you did find. Google can be forgetful.
Being able to just leave the issues is not really something I would recommend though. Let’s look at the main options available to you.
You’ve got to have a trilogy, right?
Here are the 3 main areas you need to think about when you’re deciding how you will deal with the duplicate content issues you’ve found.
Consolidate
Sometimes the best option you have is to consolidate your content. You take the existing pages with duplicate content issues and place them on a single URL (and redirect the others to that page with a 301 redirect).
Consolidation is often a good choice if the URLs have external links. You’ll consolidate the ranking signals towards one page.
Here are a couple of examples of when that could be the best course of action.
Exact duplicate pages - this might be something like the non-www vs www and http vs https mentioned earlier in the article.
Semantically similar pages - one of the most common types of semantically similar pages either come from the old days of “one keyword - one page”. If the content is fairly old, there’s a chance that some SEO just did a find and replace on some of the words and the rest of the content is pretty much duplicate. Again if the pages are old, then they could have links pointing at them. Just make sure you figure which is the best version to keep.
Consolidation can work in a slightly different way as well. Using canonicals (which we will touch on shortly) you can consolidate signals for Google rather than consolidating the actual content.
Here's a couple of examples for when this type of consolidation might be the best course of action.
PPC landing pages - whilst these can easily be set to index you could also consolidate signals to tell Google that the content on these pages is very similar to what’s on the main landing page.
Parameter URLS - as you’ll know from earlier in the guide these pages can be troublesome. Consolidation of signals is a simple way to make sure Google knows that they are duplicate content and you wish them to be treated as such.
Filter pages - products on a site can and do get external links, so signal consolidation is often the best way to duplicate content that is caused by the filters that are necessary for users on an ecommerce site.
Remove
Other times you might want to remove a page completely. You want it gone. It offers no value to users or search engines. Get those bad boys out of there.
When should you just ditch the page entirely? Here are a couple of examples for you.
Scraped content - I don’t know if you’ve heard this, but some SEOs like to do some dodgy shit. Especially in the earlier days before we will become the beacons of the marketing industry that we now are. If you have content on your site that was scraped from other sites, then get rid of it. Google knows what you’ve done. It’s time to clean up and kill those pages.
Expired products - okay, this one is a bit of an outlier, but it’s always good to have real-life examples. We had a client with several thousand expired products that were never coming back.
There are many ways to deal with expired products. This is just one.
Most of the pages on this client’s site still got impressions and traffic, so we had email capture forms on them. The issue was it was making their backend slow for their sales guys.
Not good.
Many were near-duplicates. So after pulling all the data, we redirected some, but where we had some that were getting next to no impressions AND we had nowhere to redirect them to, we just killed them off with a 410 ‘Gone’ response. Everything turned out swell.
Make unique
Finally, we have the option of making these duplicate pages unique. If the pages have a genuine reason to exist (i.e. they have search volume and are useful to the user), then you’re going to need to roll up your sleeves and apply some elbow grease.
Actually important location pages - if you have multiple offices or brick and mortar stores, then you likely have contact pages for each of them. There’s also a good chance that they are near-duplicates and could appear in the search results if they had unique content on them. I’d recommend making them unique in the following ways.
Unique title tags
Uniques meta descriptions
Directions to the location - including mentioning local landmark entities
Unique copy
Details about the team and services unique to that location
Product variations that have search volumes - there is never going to be a time that you want all variations of a product page indexed - and filters that are indexable create loads of unique content that is pointless.
But that doesn’t mean you don't want *some* of them indexed.
Want an example?
Happy to oblige.
Boom works with a company that sells white goods. Their old site had filters on it that created unique pages - literally hundreds of thousands of them. Duplicate content coming out of our ears. But some of the filters would result in pages that had a decent amount of search volume around them. So when we rebuilt their site in WordPress, we also built a plugin that allowed us to control filter pages fully.
As standard, filter pages canonicalised back to their parent page. But when we specify that a page should be unique, it creates a valid URL (unlike normal WordPress).
From there, we can create:
A unique title tag
A unique meta description
A unique H1 heading
Unique content that sits above and/or below the products
Technical fixes for duplicate content issues
Now you’ve spent some time digging into what issues you have and how you might like to go about fixing those issues, you’ll need to know HOW you make those fixes happen.
Here’s a quick overview of some of the technical implementations that can be carried out to make your duplicate content nightmares disappear.
Canonicalisation
The canonical tag - sometimes also referred to as rel canonical - was introduced in February 2009, incidentally around the time I got into SEO properly. As a newbie, it took me some time to get my head around. In reality, it's a fairly simple concept.
The canonical tag is a way of letting search engines know which page you would like it to treat as the master copy of any given page.
There are two types of canonical; let’s take a quick look at them.
Canonicalisation on your site
You can use the canonical tag on your own site to let Google know that creating pages are exact or near duplicates of a stronger, more important page. You're essentially saying, “Hey Google, I know this page is very similar to another page, and it's the other page that I want you to index and rank, please move along”.
Cross-domain canonicalisation
The second type of canonical is the cross-domain canonical. This is used when the same content is published across more than one domain. It's used to let Google know which content is the one that you would like to be indexed and ranked.
Redirects
I’ve covered redirects quite a bit in a recent guide to redirects so head over there if you want to read more.
Meta robots noindex
Unlike rel=canonical, noindex is a directive rather than a suggestion. Google can ignore canonicals if they think you have implemented them incorrectly or by mistake. When it comes to noindex Google will do precisely what you tell it. So use with caution.
It’s also a good idea not to jump between index and noindex because that can confuse Google.
“In general, I think this fluctuation between indexed and non-indexed is something that can throw us off a little bit.
Because if we see a page that is noindexed for a longer period of time we will assume that this is kind of like a 404 page and we don’t have to crawl it that frequently.
So that’s something where probably what is happening there is that we see these pages as noindex and we decide not to crawl them as frequently anymore, regardless of what you submit in the site map file.
So that’s something where… fluctuating with the noindex meta is counterproductive here, if you really want those pages to be indexed every now and then.”
John Mueller, Google Shares How Noindex Meta Tag Can Cause Issues
Quick tip. Never mix Noindex and Rel=Canonical on the same page. This is sending Google mixed signals. Mixed signals are never good. Never cross the streams. Don’t believe me? Let’s check in with John.
“This is also where the guide that you shouldn't mix noindex & rel=canonical comes from: they're very contradictory pieces of information for us. We'll generally pick the rel=canonical and use that over the noindex, but any time you rely on interpretation by a computer script, you reduce the weight of your input :) (and SEO is to a large part all about telling computer scripts your preferences).”
John Mueller, Reddit r/TechSEO, 2018
“Egon: Don’t cross the streams.
Peter: Why?
Egon: It would be bad.
Peter: I’m fuzzy on the whole good/bad thing. What do you mean “bad”?
Egon: Try to imagine all life as you know it stopping instantaneously and every molecule in your body exploding at the speed of light.
Raymond: Total protonic reversal.
Peter: That’s bad. Okay. Alright, important safety tip, thanks Egon.”
Ghostbusters

Best practices to avoid duplicate content
Consistency
As with many things in life, consistency is critical. Especially when you are working on decent-sized websites.
Create workflows and guidelines for anyone working on the site and make sure they stick to them. Processes and guidance should be provided for the following (at the least).
Adding unique Title Tags and how to optimise
Creating unique Meta Descriptions and how to optimise
Creating unique H1 tags and how to optimise
Which versions of pages to link to (think trailing slash and no-trailing)
Self-referencing canonicals to safeguard against scrapers
Beyond other technical reasons, a quick way of combating lazy scrapers that copy your content is to include a self-referencing canonical on every page of your site. While Google is pretty good at figuring this kind of stuff out, it’s an easy thing to implement on most sites, so you might as well include it. This will tell Google that you are the original source of the content.
While it’s site specific, it's worth noting that your own site can benefit from self-referencing canonicals as well.
Many of your URLs might have Session ID’s or tracking parameters added to them. These are going to have the same content as the source URL. By using self-referencing canonicals on this kind of duplicate content you’re immediately giving Google the hint that you know they are duplicate.
Here’s what it would look like:
https://jonathanpryceperlink.com?grrtrackingmakeduplicate
By having a self-referencing canonical on there Google would see the following as the original URL:
https://jonathanpryceperlink.com
Unique product content
But, but Wayne, so many. Yeah, I get your pain. E-commerce sites often have thousands of products. Who has time to write all that content? Who has the budget to get an in-house copywriter? Some do but not all by a long shot.
There are some ways around this.
Take your top products and rewrite the descriptions with conversion in mind and see what happens. Track the changes in Google Search Console and see how it pans out. You don't have to do all of them in one go.
How do you decide which ones to work on? Take ones that already perform okay, make sure they are products that you have a good mark up and also bring search volume into the equation. Bang all that into Excel or Google sheets and play with data.
What about AI? Well, it's moved on a bit since I first wrote this.
Using AI to generate product descriptions at scale is pretty standard practice now. The question isn't really "should we try this?" any more — it's "how do we do it without making the problem worse?"
Because that's the trap. AI tools produce content that follows similar patterns and reaches for similar phrasing. Run a few hundred product descriptions through the same prompt and you can end up with pages that are technically unique but feel — and read — like near-duplicates.
Google noticed. The September 2025 spam update went specifically after this kind of industrially processed content: cookie-cutter location pages, templated product copy, anything that looks like it was generated rather than written.
The fix isn't to stop using AI. It's to treat the output as a first draft. Add specific details the manufacturer's description doesn't include. Make the final copy say something the tool couldn't have generated without your input. Start with your best-selling products and work outward from there.
As for which tools to use — I'm not going to recommend specific ones here because that list would be out of date before you finished reading it.

“Any sufficiently advanced technology is indistinguishable from magic.”
Arthur C. Clarke, Clarke's three laws
Right, you’re there now. You know what duplicate issues can arise on a site and how you might go about fixing them. Now you just need to get them fixed.
There are only two hurdles in your way now.
Convincing the client and getting the developers to implement the fixes.
Communicating your duplicate content issues
As you might know from my other Sitebulb posts, I’m keen on actually getting shit implemented. An audit is worth nothing if things don't get implemented. The audit is the easier bit. SEOs know their stuff. But they don't necessarily know how to communicate that to clients. They don't know how to convince developers to implement the fixes even when sign off has come from the client.
So let’s have a look at how you can make this happen. Clients and developers are very different beasts.
How to communicate duplicate content issues to clients
Keep it simple stupid (KISS)
Yeah, they were a fun band, but that’s not what I’m talking about here, so put your long tongue and theatrical makeup away.
KISS is an acronym for keep it simple stupid and was popularised by the US Navy in 1960. It’s primarily referenced when it comes to design work but applies to getting buy-in from clients too.
Clients are busy; clients often don't often know that much about SEO. So don't spend ages talking through all the technical details. You need to get your point across quickly; digging too deep into data will cause the client to lose interest and move on to what their next meeting is about or what big decision they have to make that day.
Less is more.
Show how it can fit into wider company goals
That’s what the client cares about. “How is this going to help my business goals?” A spreadsheet and talking about pagination, URL parameters and the history of scaping will not get your recommendations signed off. Before presenting, you need to know what those goals are. When you know them, you can tailor your recommendations.
It’s not the same every time, trust me.
Know what floats their boat
You will likely be trying to get signoff on fixing duplicate content early in a relationship with a client. At Boom, the audit is one of the first things that we undertake. Whatever strategies and tactics come later are based on having a solid foundation.
This means you aren’t going to know them that well. So take the time to find out. Talk to others that have dealt with them. If you have access to other people on the team, quiz them (gently) to find out what helps get sign-off over the line.
Do they like data? Analogies? How do they like things presenting to them?
Knowing this stuff can increase the odds of getting them to give the big thumbs up to your recommendations.
How to communicate duplicate content issues to developers
Learn dev lingo
Do you know what scrum means? Do you know what it means to work agile? Do you know what story pointing is?
If not, then it’s a good time for you to start learning. Development teams have a completely different way of working to marketing teams. They protect their time. Work happens in sprints. When you know how the team you’re going to be working with actually, er, works, then you can see how your recommendations will fit in.
Being able to adjust how you work helps to get recommendations implemented, it helps them get implemented in the way you want, and it sure gets them implemented quicker.
Separate the issues
There is no one-size-fits-all solution to fixing duplicate content issues. You’ve probably figured out that for yourself if you’ve read the rest of this article. But a development team might not be aware of that. So not only do you have to explain why it’s important, but you need to break it down for them.
I don't mean that in a condescending “this goes here” and “if you press this button then magic happens” way. I’m talking about taking each fix and explaining why it might need to be done this way. Developers like to find elegant solutions to problems. But sometimes you need to fix different problems in different ways.
Understand their tech stack
I’ve kind of covered this in my post about the difference and quirks of different CMSs. If you want to get your recommendations implemented, then take the time to find out what they are using. Some CMSs just don't have the capability to deploy certain fixes. Some CMSs are limited in what the development team can do.
If you know those limitations upfront you can make sure that you’re not asking for the impossible to happen.
Understand the Anderson-Alderson scale
The whatty-what?
This comes from a post by Mike King (also known as ipullrank) on Search Engine Land way back in 2017. It demonstrates an uncanny way to understand how to get developers to implement SEO recommendations - and has pop culture references to boot. Perfick.

Erm, “what?” I hear you cry.
Let’s break it down.
In the article (which Search Engine Land has now redirected to their generic What is SEO guide, so you'll just have to trust me), Mike discusses two fictional characters, Thomas Anderson from the film The Matrix and Elliot Alderson from the TV show Mr Robot.
As Mike points out in the article Thomas Anderson is a bit of a renegade, a maverick employee.
“You have a problem, Mr Anderson. You think that you’re special. You believe that somehow the rules do not apply to you.”
Thomas Anderson’s boss, The Matrix
Mike puts it more eloquently than I ever could, and I don't want to paraphrase.
“Anderson developers are the type of employees who live on their own terms and only do things when they feel like it. They’re the mavericks that will argue with you on the merits of code style guides, why they left meta tags out of their custom-built CMS entirely, and why they will never implement AMP — meanwhile, not a single line of their code validates against the specifications they hold dear.
They’re also the developers who roll their eyes to your recommendations or talk about how they know all of the “SEO optimizations” you’re presenting, they just haven’t had the time to do them. Sure thing, Mr. Anderssssson.”
Mike King, How to get developers to implement SEO recommendations
On the other hand, you have the Alderson side of the scale, based on the character that Rami Malek played in Mr Robot. To quote Mike again.
“Alderson is the type of person who will come into the office at 2:00 a.m. to fix things when they break, even going as far as to hop on the company jet that same night to dig into the network’s latest meltdown.
Alderson-type developers are itching to implement your recommendations right away. That’s not because they necessarily care about ranking, but because they care about being good at what they do.
This developer type is attentive and will call you out on your b.s. if you don’t know what you’re talking about. So don’t come in with recommendations about asynchronous JavaScript without understanding how it works.”
Mike King, How to get developers to implement SEO recommendations
It truly is a lost gem in the world of SEO articles, but it boils down to this. If you want to get your recommendations implemented by the developers with the least amount of fuss you need to know what kind of a developer they are. You need to understand how they work.
The more time you spend learning about them and their processes, the more you can tailor your recommendations to them - and importantly - get them actioned.
What's changed for AI search
So far, everything in this guide applies to traditional search. Google crawls, clusters, picks a winner. You can influence that with canonicals and redirects.
Job done.
AI search changes the stakes. Not the rules exactly. Just the stakes.
When an AI system generates an answer - Bing Copilot, ChatGPT, Google's AI Overviews, take your pick - it doesn't pull from a ranked list. It picks one page to ground its answer in. That's a different decision to ranking.
Microsoft's Bing team explained exactly how this works in December 2025: LLMs group near-duplicate URLs into a cluster, then choose one page to represent the whole set. One page becomes the source. The others don't appear at position 4 or 7.
They don't appear at all. They're on the proverbial cutting room floor.
That's what's happening to your duplicate pages in AI search. And unlike traditional ranking, there's no position 4 to fall back on.
The syndication problem
You get coverage. Someone republishes your article in full. Lovely. Except now there are two identical versions of that content out there, and the AI has to pick one.
If the syndicated copy has more recent backlinks, or has been sitting on a higher-authority domain, the AI might reach for that version instead. Your brand doesn't get the attribution.
Theirs does.
The fix is simple, but you have to ask for it. Get syndication partners to add a canonical tag pointing back to your original URL. Where you can, syndicate excerpts rather than full articles. It's not a big ask. But it's the kind of thing nobody thinks to do until it's already a problem.
Campaign pages and localisation
Here's one I see all the time. Campaign pages that are 90% identical with slightly different headlines. Regional variants where the only real difference is the phone number. They exist for good reasons. But when near-identical pages are targeting the same query intent, the AI can only pick one. You're splitting your own signals for no gain.
Localisation is the same deal. Regional pages are fine - but if the UK and US versions are basically the same article with spelling swapped out, that's not meaningful differentiation. The AI can't tell them apart for the purposes of answering a query. And if it can't tell them apart, it'll just pick one. Probably not the one you want.
What Google says
Google's official position is that standard duplicate content guidance still applies. No additional requirements for AI Overviews specifically. However, Microsoft has published more detail on how their systems work - which is why this section leans on Bing's guidance. That doesn't mean Google works differently. It means they've said less about it.
The bottom line
Nothing in this section changes what's already covered in this guide. Canonicals, redirects, not letting near-identical pages pile up - that's still the playbook. What AI search adds is a sharper reason to care. A duplicate content issue that might have cost you a ranking position can now cost you a citation. And if that citation is in an AI-generated answer that half your potential audience reads without ever clicking through, that's a different kind of visibility loss.
Fix the basics. You know how. You've just read 8,000 words about it.
Wrapping Up
There you go, Moz fans Sitebulb readers; that’s what I believe to be a reasonably comprehensive guide to duplicate content and how to deal with it. But what have we learnt along our journey, Frodo?
Wayne can weave pop culture and films into pretty much everything he writes - even if it feels forced sometimes
Duplicate content issues and fixing them is very nuanced - take the time to decide the best course of action
Duplicate content fix recommendations dont mean shit unless you can get them implemented
This whole thing could have been a 3 tweet thread, couldn’t it?
Until next time...
"Why don't we just wait here for a little while... see what happens..."
MacReady - The Thing
You might also like:

Unrepentant long-time SEO, consultant at Boom Online Marketing, and guest writer for Sitebulb.
Similarly sweary as Patrick, but does a much better job of hiding it (usually).
Related Articles
 The Role of Informational Content in the Age of LLMs
The Role of Informational Content in the Age of LLMs


 Beyond Cosine Similarity: Testing Advanced Algorithms for SEO Content Analysis
Beyond Cosine Similarity: Testing Advanced Algorithms for SEO Content Analysis

 How to Stay Relevant in a World of AI Overviews & Query-Fans
How to Stay Relevant in a World of AI Overviews & Query-Fans

 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.