


Improving Crawling & Indexing with Noindex, Robots.txt & Rel Attributes
 Shaikat Ray
Shaikat Ray
Published February 17, 2025
This week, we welcome Shaikat Ray to Sitebulb, who walks us through how to improve your page crawling and indexing using noindex, robots.txt and rel attributes.
This guide will show you in simple steps how you can use data from Google Search Console to improve crawling and indexing for your website.
You’ll learn how to use the following SEO elements to your advantage.
- Noindex robots directive: to remove pages from the search results
- Rules on robots.txt: to control crawling
- Rel="canonical" attribute: to consolidate signals to the main version
- Rel="nofollow" attribute: to discourage crawling of unwanted pages
Contents:
- Why you should care
- Finding suitable suspects
- Actions to take
- Choosing the right option
- Measure the results
Why You Should Care
Below is a snapshot from Google Search Central Documentation, where Google recommends hiding unnecessary URLs from the search results to improve crawl rate, discoverability of new content, optimize crawl budget, and reduce waste of server resources.

Source: Google Search Central Blog
Search engines like Google don’t have unlimited resources to crawl and index everything on your website, hence, you need to make your effort to lead them to the important pages, keep them on track as much as possible by implementing these HTML/SEO elements.
- Search engines may spend less time on your website
- New pages may stay undiscovered
- New pages may take more time to be crawled and indexed than usual
- Obsolete pages may provide wrong information
And, these can negatively impact your organic visitors and business outcome depending on the size of your website.
Finding Suitable Suspects
So, how do we find our suspects? The answer is, Google Search Console. We will find out duplicate or canonicalised pages, obsolete pages that are currently being crawled and indexed.
Page Indexing Report
Let’s begin with the page indexing reports in Google Search Console. I will skim-through the pages under these reports to find the suspects for these three elements – noindex, robots.txt rules, rel=nofollow – to be implemented on.
Alternate page with proper canonical tag
This report is the goldmine for our suspects, the crawl-wasters! These pages are canonicalised to their master version to tackle duplication and cannibalisation. Let’s head over to Google Search Console and explore.
Step 1: Click on Pages (Under Indexing)
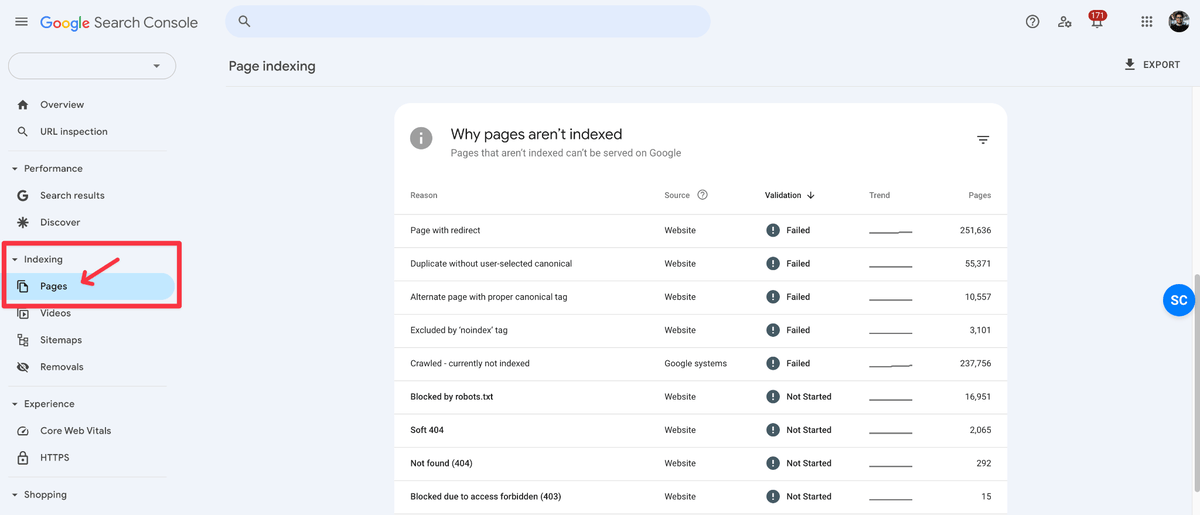
Step 2: Click on “Alternate page with proper canonical tag”
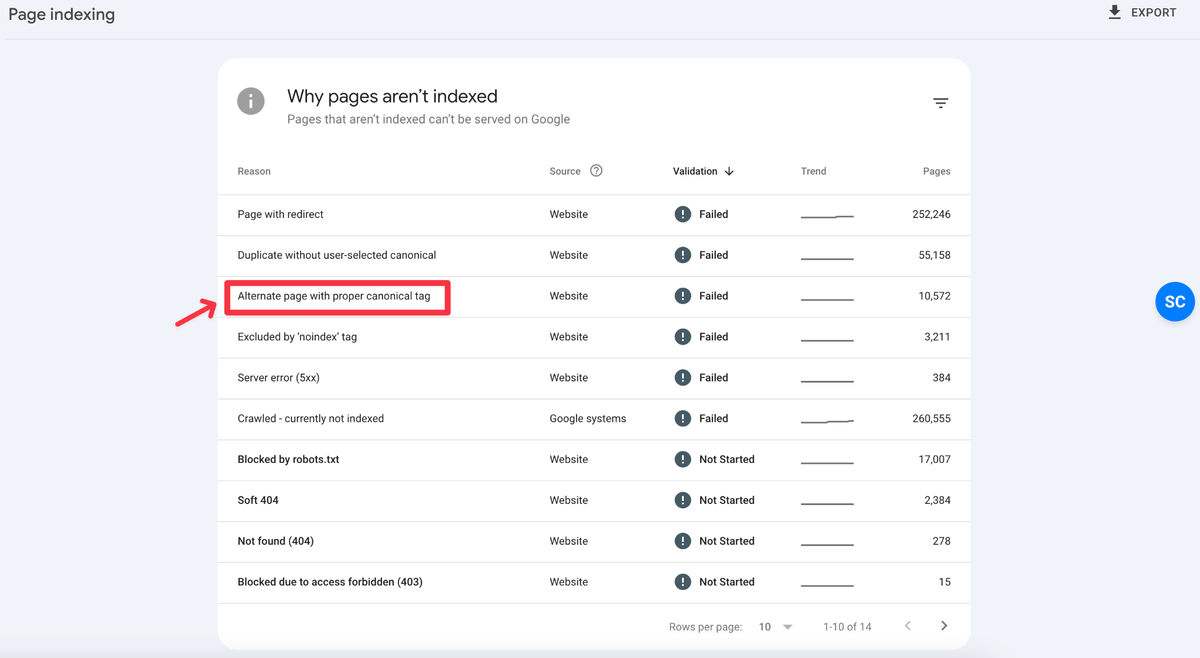
Step 3: Skim Through the URLs to Find Suspects
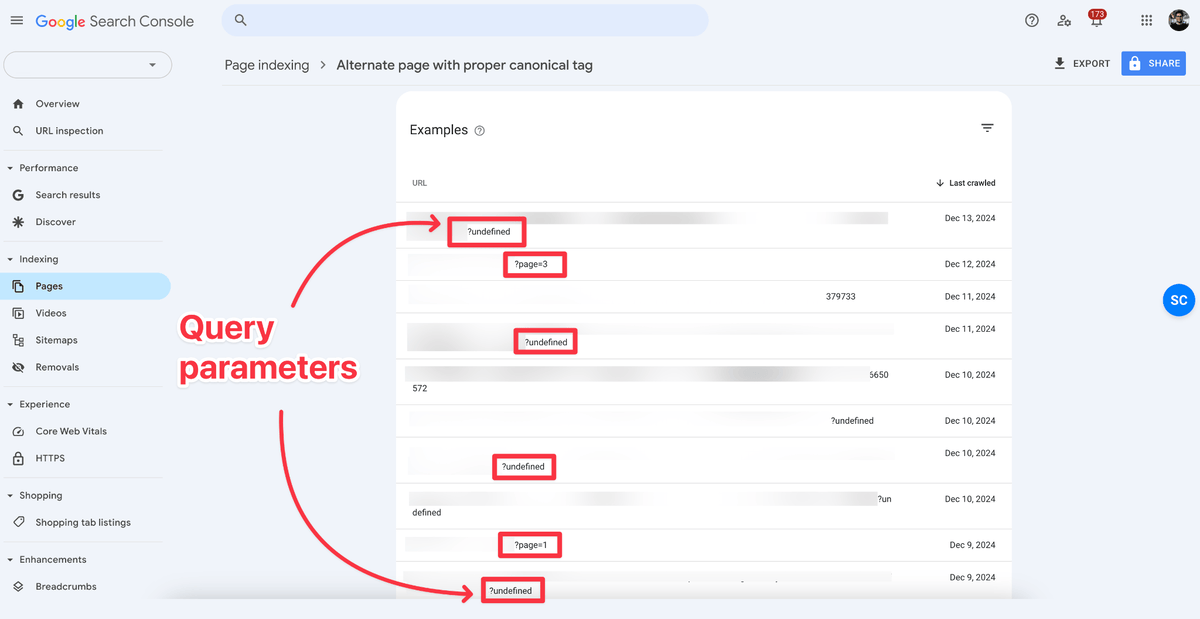
Now, skim through the URLs listed here, and list the query parameters (aka URL parameters) as many as you can. If you’re an ecommerce store, you’ll find URLs for faceted navigation under this report which are your suspects! For example, common parameters you might come across are:
- ?filter (used for applying any filters)
- /search?q= (used for internal search)
- ?sort_by (used for sorting products)
- ?color (used for color variations)
- ?size (used for size variations)
- ?price (used for price ranges)
In my case, I can see multiple query parameters here:
List of Suspects:
- ?undefined
- ?page=1
- ?page=3
Step 4: Add a URL Filter with ? Mark
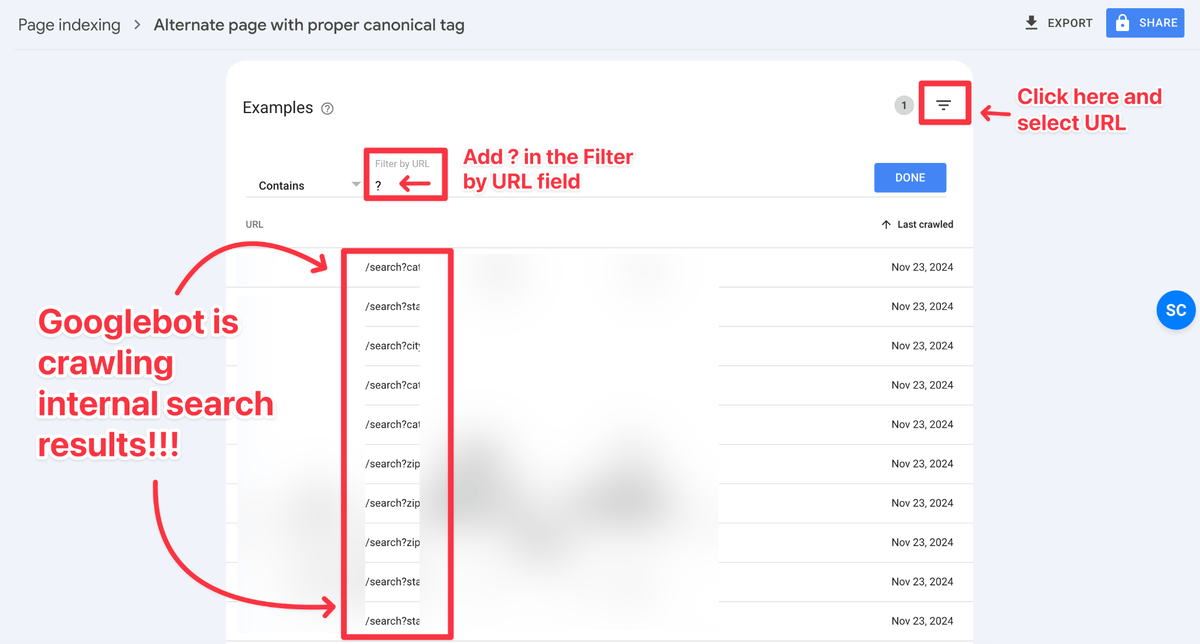
When you apply a URL filter with ? (question) mark you will see URLs containing query parameters and you may even find stronger suspects like sub-folders. In this case, even though there are many query parameters, the /search sub-folder is a stronger suspect!
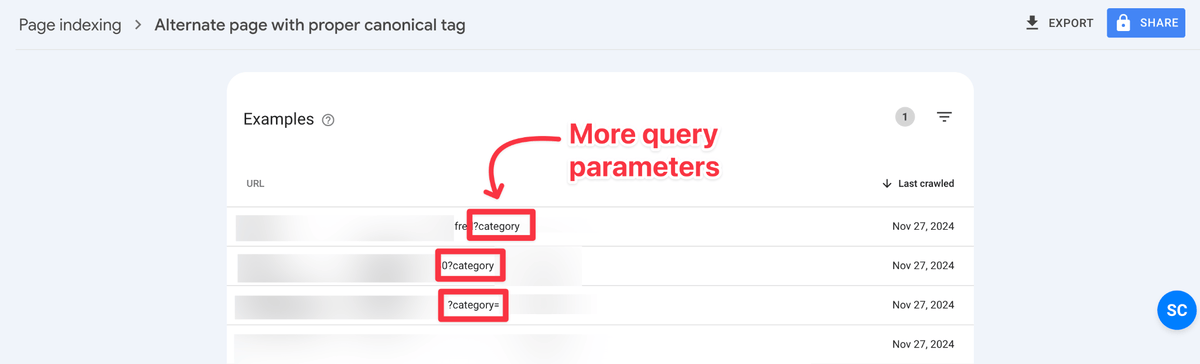
List of Suspects:
- /search
- ?category
You can repeat this suspect hunting process with the other reports in Google Search Console to find more query parameters and folders. While listing suspects from these reports, make sure those are canonicalised pages, you don’t want to include any master pages.
For example:
- Duplicate without user-selected canonical
- Discovered Currently Not Indexed
- Excluded by ‘noindex’ tag
- Indexed, though blocked by robots.txt
Performance Report
Next, we will find suspects using the performance report. The common suspects are query parameters, duplicate pages, folders that you don’t want to show in search results.
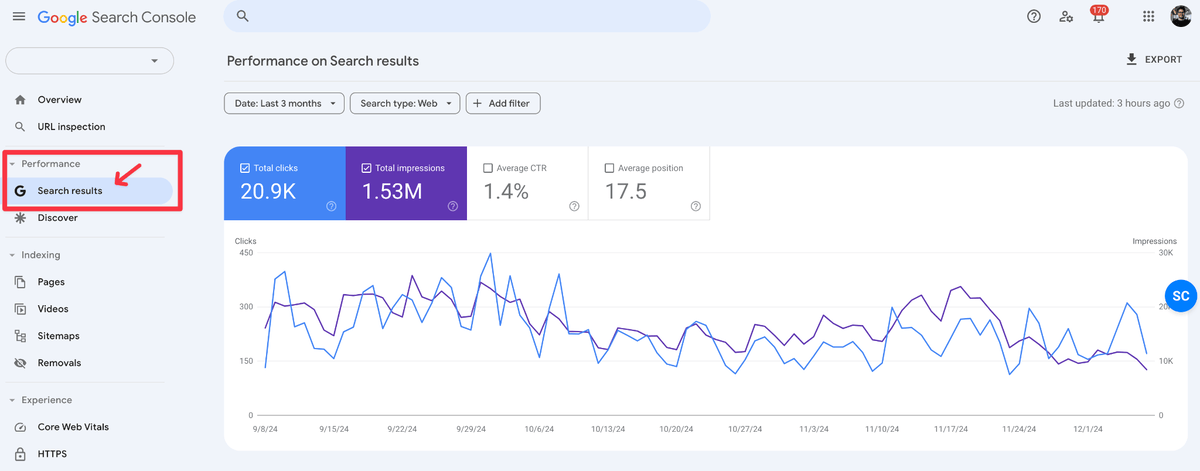
Step 1: Head over to the Performance Report
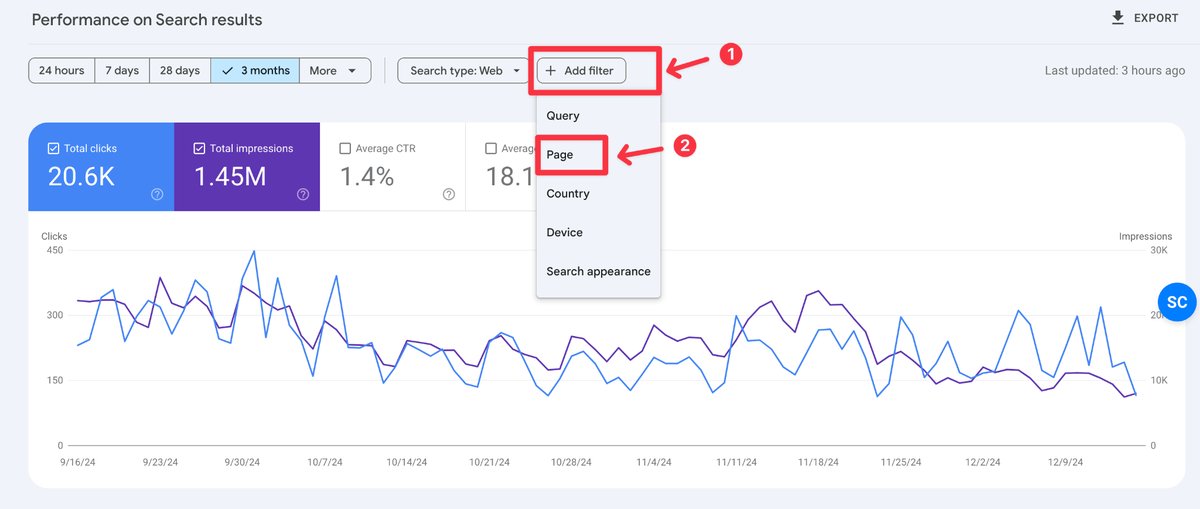
Step 2: Click on Add filter and Select Page
Step 3: Add ? Mark in the URLs Containing Field
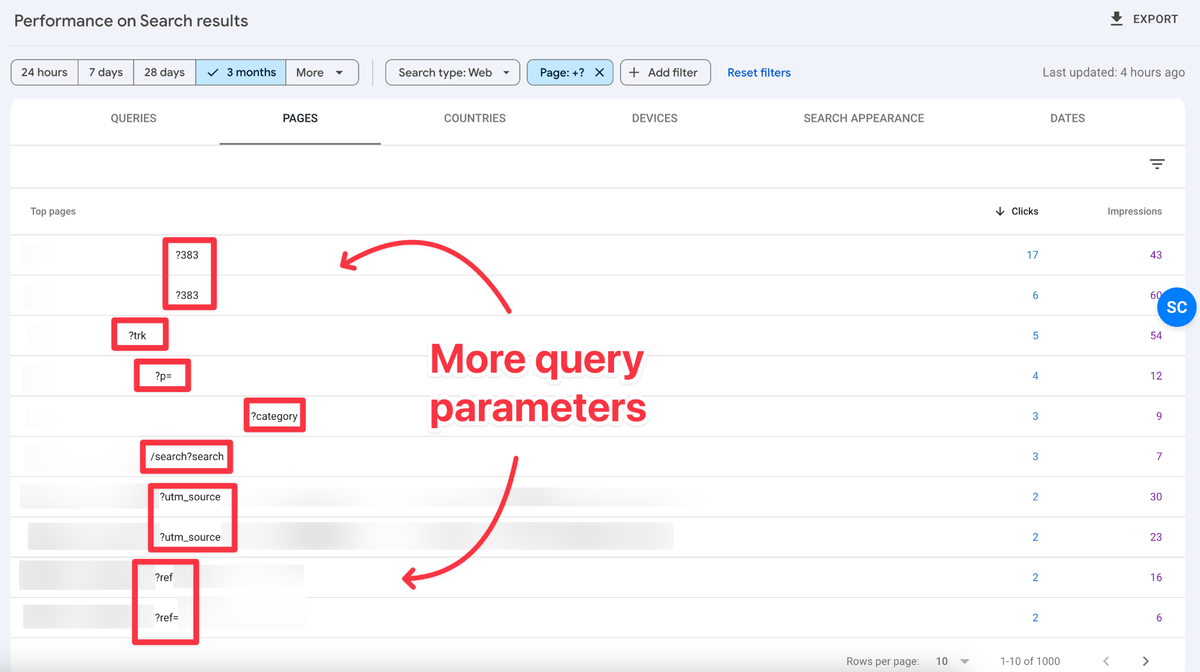
Visit the pages, check out their canonical URL, if these are canonicalised to their respective master version, that means these are your suspects.
Also, ask yourself, should these pages be shown in the search results? If the answer is No, that means you have more suspects to be listed.
List of Suspects:
- ?ref=
- ?trk
Crawl Stats
Finally, to make the final check, you will need to skim through pages in the Crawl Stats report in Google Search Console.
Step 1: Head over to Settings > Crawl Stats > Open Report
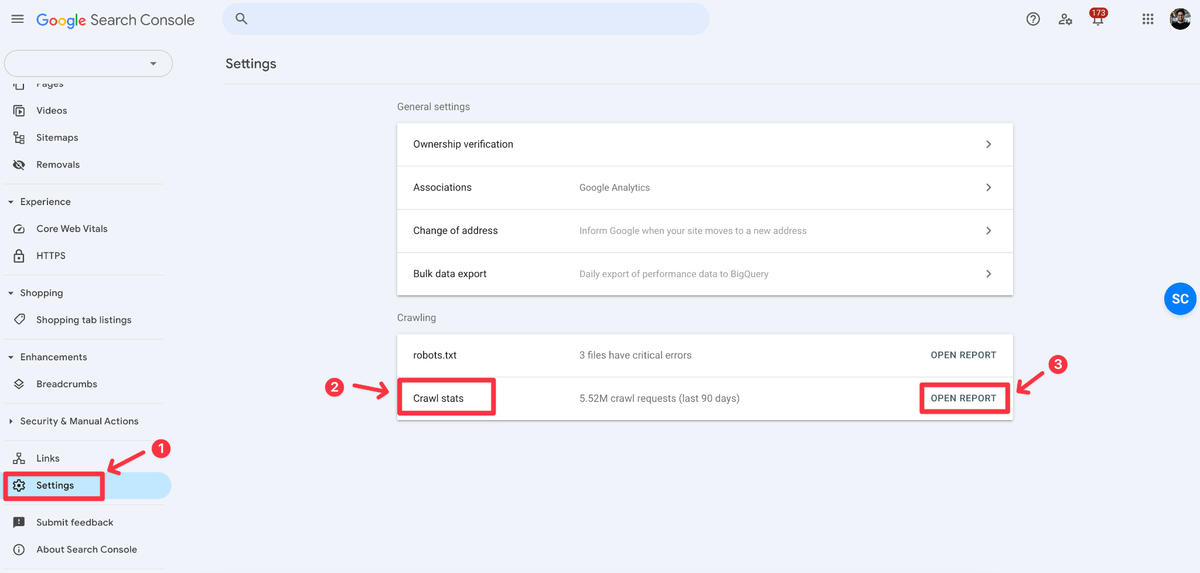
Step 2: Click on HTML (by File type)
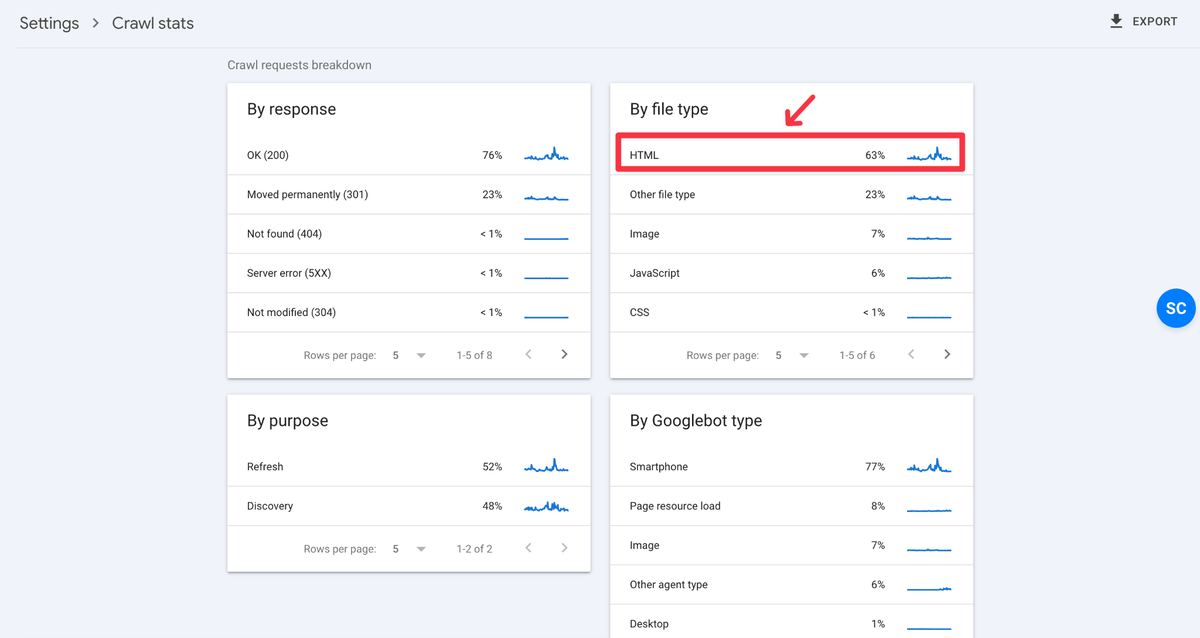
Step 3: Scan Through Pages and Add URL Filter with ? Mark
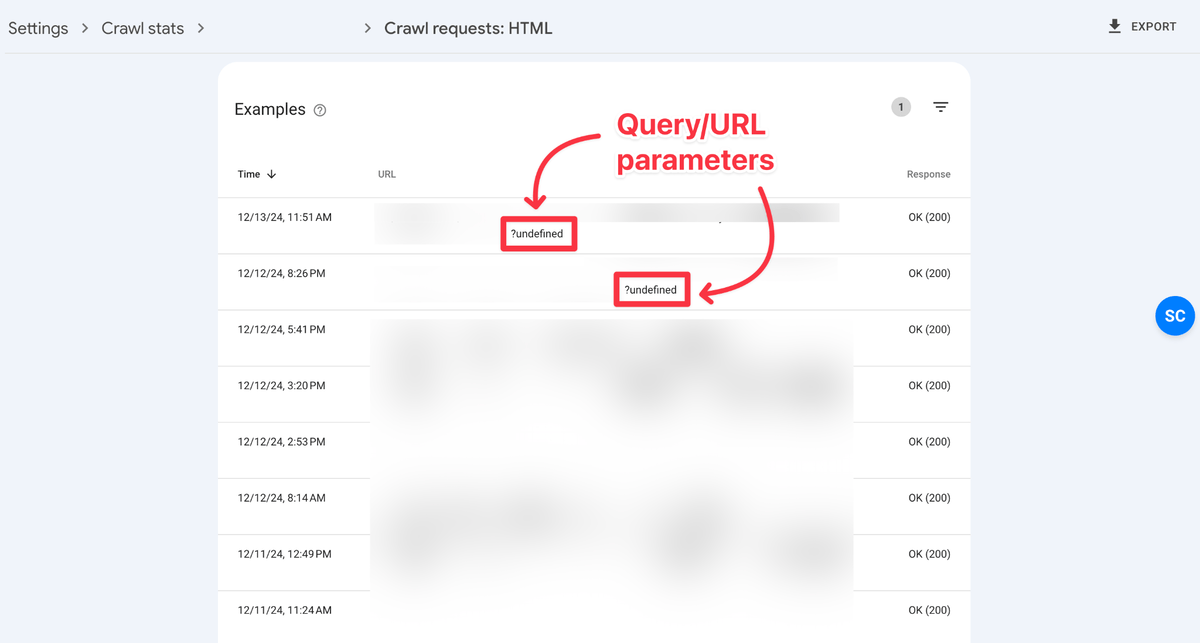
Scan out these pages to find candidates for these elements (noindex, robots.txt rules, rel=canonical, rel=nofollow) to be implemented on.
Actions to Take
Now, as you have the final list of suspects, it’s time to take action! We will use robots.txt rules, noindex robots directive, rel=canonical, and rel=nofollow link attribute to improve crawling and indexing by reducing crawl waste and deindexing obsolete pages.
Robots.txt Rules
Here’s the final list of suspects.
- ?undefined
- ?page=1
- ?page=3
- /search
- ?ref=
- ?trk
You’ll need to group them by pattern, that way you can target more with less rules on robots.txt file. For example, the final suspect list can be turned into this:
- ?undefined
- ?page=
- /search
- ?ref
- ?trk
Now, this will be our new robots.txt rules:
User-agent: *
Disallow: /*?undefined
Disallow: /*?page
Disallow: /search
Disallow: /*?ref
Disallow: /*?trk
If you’re an ecommerce store, you should block your faceted navigation URLs to reduce crawl-waste, save server resources, and improve discoverability of the important pages on the website.

Source: Google Search Central Documentation
WARNING!
Before you add the Disallow rules, be ABSOLUTELY sure you’re not accidentally blocking any important pages on the website. You can use https://www.realrobotstxt.com/ to parse the rules and verify whether your important folders are getting blocked.
Noindex Tag
While hunting for suspects you might come across obsolete pages or duplicate pages that you don’t want to show in search results anymore, noindex robots directive is your best friend!
You can add the noindex tag on the pages that are no longer relevant or obsolete for your business. You can do this by robots meta tag or x-robots-tag HTTP header.
Important note: if you want pages to be removed from the index, you need to apply the noindex first, let Google remove them, then disallow them. If you disallow first, you block crawling, and Google never sees the noindex.
Robots Meta Tag
You can add the noindex directive in the robots meta tag inside the <head> section of each page like this: <meta name=”robots” content=”noindex, nofollow”>.
X-Robots-Tag
If you want to do this at scale by using pattern match, X-Robots-Tag is the best option. You can set this condition using the server configuration file (.htaccess on Apache server for example) or services like CloudFlare.
Rel=canonical Attribute
You can add rel=canonical link attribute on the duplicate/variation pages pointing to their main version to consolidate the signals to the main version and eliminate duplication issues.
You can start with “Duplicate without user-selected canonical” report in Google Search Console where you’ll find pages without any canonical URL.
Rel=nofollow Attribute
You can also use rel=nofollow link attribute on these URLs that will discourage search engine crawlers to crawl these pages.
However, you must be consistent with the rel=nofollow attribute to make it work perfectly. If you miss the rel=nofollow tag for some pages or if the pages were found on other websites without the rel=nofollow link attribute and search engines will crawl them.

Source: Google Search Central Blog
Choosing the Right Option
Now as you have your list of suspects, how do you choose which is the right option to implement for them? Well, you can use the following decision tree to do so.
- Use the noindex robots directive if you want to remove pages from the search results.
- Use rel=nofollow link attribute if you want to discourage search engine crawlers from crawling.
- Use rel=canonical link attribute pointing to the master version if you want search engines to prioritise the master page only.
- Use robots.txt rules if you completely want to keep search engine crawlers away from crawling them.
Here are some scenarios:
- Use noindex directive for obsolete pages, or pages you want to remove from search results.
- Use rel=nofollow attribute for all kinds of query parameters (assume those are canonicalised and non indexable).
- Use rel=canonical pointing to the master version for duplicate pages.
- Use robots.txt rules for query parameters used for faceted navigation, internal search results, and canonicalised folders.
Measure the Results
Alright, now that you have implemented these elements on your website, you might have the questions - how do I measure the results? The answer is Google Search Console.
After a few weeks of the implementation, check your indexing coverage report, number of (important) indexed pages, crawl stats in Google Search Console. Hopefully, you’ll see Googlebot is now spending its resources on the important pages on your website.
This will result in more frequent crawling, refreshing, and improved discoverability of the new pages, and that’s what we all want!
Final Words
So, there you have it. Based on the size of the site, the impact of this implementation will differ. Medium to large sites will benefit from it immensely. Happy crawling, and indexing!
You might also like:

Shaikat Ray is an SEO professional specializing in technical SEO. He is the founder of Self Canonical, a technical SEO consultancy working with businesses of all sizes, from local and small businesses to e-commerce companies and enterprises. Shaikat loves digging deep into robots.txt rules, robots meta tags, HTTP headers, JSON-LD structured data, hreflang attributes, and crawl logs to uncover opportunities that can lead to better SEO performance.
Related Articles
 Agency Technical SEO in 2026: AMA with Tory Gray & Patrick Hathaway
Agency Technical SEO in 2026: AMA with Tory Gray & Patrick Hathaway

 JavaScript SEO AMA with Sam Torres: 13 Questions & Answers
JavaScript SEO AMA with Sam Torres: 13 Questions & Answers


 These WordPress Website Mistakes Could Hurt Your Brand’s Credibility
These WordPress Website Mistakes Could Hurt Your Brand’s Credibility

 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.