
 Patrick Hathaway
Patrick Hathaway
We need to talk to you about speed.
We get it; the world is getting faster.
But faster isn't always better. In fact, sometimes, faster can be significantly worse.
Contents:
- What is crawl rate?
- What is Crawler Denial of Service?
- Why is CDoS bad?
- Crawling responsibly - with speed limits
- Crawling responsibly - but faster
- What Google says about it all
What is crawl rate?
Crawl rate is the number of requests a search engine crawler makes to a website in a day. Google says of its own crawl rate:
"Google has sophisticated algorithms to determine the optimal crawl rate for a site. Our goal is to crawl as many pages from your site as we can on each visit without overwhelming your server's bandwidth."
What is Crawler Denial of Service (CDoS)?
Desktop crawlers are notoriously bad for accidentally pulling a website down. Anyone who crawls sites regularly has probably done this a few times in their career.
The main reason this happens is because a user tries to crawl the site too quickly, using too many threads.
In essence, running 'too many' threads on a website is the root cause of Crawler Denial of Service (CDoS) - when the server is unable to handle the load and it falls over (not literally).
What are 'threads'?
You may not be aware what a thread is or what it does. Within software, a thread is simply a component of a process, which is given instructions by a scheduler.
In the case of a crawler, threads are used for tasks such as 'downloading the HTML from a web page'.
In terms of how they affect server load, you could consider threads to be the equivalent of users on your website. So say you configure your crawler to use 10 threads, this would be equivalent to 10 users on your site at once (browsing incredibly quickly!).
Without a speed limit, these 10 threads will zoom through your site as fast as they can, perhaps as fast as 50 URLs per second.
For a lot of websites, this is too fast, and has the potential to overload the server.
Why do servers get overloaded?
The short answer is that they simply can't handle the number of requests that are being thrown at them. It's like that time when one of your employees thought it would be 'cool' to publish the memo you sent round telling staff members to stop bringing their vibrators to work, and it went on the front page of Reddit, and hundreds of people visited your website at once so it crashed.
Users and crawler threads are not exactly comparable - since servers will handle users differently in terms of caching, cookies and load balancing - but the premise remains the same, with a massive influx of usage there is simply not enough bandwidth to cope with the volume.
This is pretty similar to what happens with a CDoS. Each thread is pinging the server several times a second: 'give me this page', 'give me that page', and the server is dutifully trying to respond to each request by sending back the data. If the requests are too frequent, it will eventually become too much for the server to handle.
In your crawler software, you might see this as pages timing out (i.e. the crawler had to wait too long and gave up) or server errors (5XX).
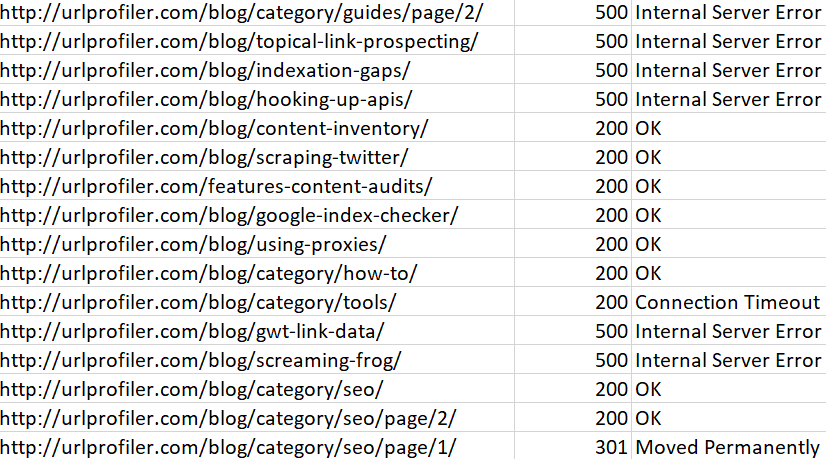
Some servers will have systems in place to try and mitigate these sort of problems, such as returning a HTTP status of 403 (forbidden) or 429 (too many requests), which is the server equivalent of saying 'kindly fuck off now.'
Why is CDoS bad?
Hopefully the main negatives are obvious; businesses that depend on their website could lose out of valuable traffic or sales if you keep pulling it down.
But pulling a website down is only the extreme end of the scale. If crawling activity is slowing your server down, then it is slowing it down for your site visitors too. And we've all read the studies about page speed affecting conversion rates.
Beyond the business reasons, it doesn't make sense from an audit standpoint either, since crawling too fast can lead to inaccurate data.
This is simply a corollary of the above. If a server gets overloaded, of if the server starts telling you to go away, the data you get back in your audit will be inaccurate or incomplete - due to all the timeouts and server errors.
Crawling too fast is rude, potentially damaging, and can ruin your crawl data. Here at Sitebulb, we do not recommend it.
Crawling responsibly - using speed limits
Most crawlers allow you to set a limit to the number of URLs the crawler will crawl per second, and you can often also adjust the number of threads used. For example, Sitebulb's default speed setting is to use 4 threads, at a maximum of 5 URLs/second.
This limits the chances of accidental CDoS, by effectively throttling the crawler if the server can't handle it. Let me explain...
How TTFB affects crawl speed
Time to first byte (TTFB) is one of those site speed metrics you hear about all the time. Again, you may not know exactly what it is or how it affects crawl speed.
Consider a crawler requesting to download a URL:
- The crawler requests a URL by making a HTTP request.
- The server receives the request, renders the content and generates the response.
- The server sends the response back to the crawler.
- The crawler receives the response.
TTFB is the time taken from the beginning of #1 to the beginning of #4 (literally, when the first byte of content is received).
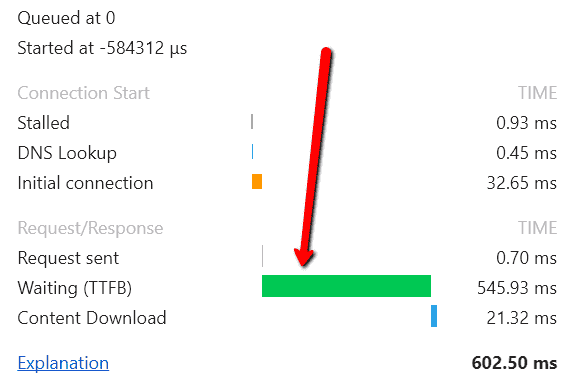
If we look at #2, since the content needs to be rendered, this implies that pages with more content have a longer TTFB. As an example, page resource URLs such as images will typically have 10X faster TTFB than HTML pages.
Since #3 regards data transfer, TTFB is also affected by the connection speed and available bandwidth, both for the server sending, and the user receiving.
In short, if your pages are heavy, or the server takes a long time to send the data, TTFB will be higher.
Now, if we return to our speed setting of URLs/second, it should be clearer how TTFB fits into the equation (since TTFB is effectively measuring 'download time'). Say we have the default settings of 5 URLs/second as the maximum speed, with 4 threads available for crawling.
If the TTFB is roughly 500ms per URL (= 0.5 seconds), this means each thread could theoretically download 2 URLs per second, so all 4 threads could do 8 URLs/second at a maximum. Since the 5 URLs/second limit would kick in, it wouldn't actually do this, but it could, on that particular website.
Say, however, that the TTFB was actually more like 3 seconds. This means that the 4 threads could only crawl 4/3 = 1.33 URLs/second!
TTFB of 3 seconds is slow. Per our definition above, this means that either the pages are very heavy or the server is not up to much. Either way, throwing more threads at it is unlikely to be a good course of action.
In circumstances like this, our advice is twofold:
- Crawl the site slowly. By sticking to something like a 5 URL/s limit you are automatically throttling based on TTFB, view this as a positive.
- Encourage the site owner to improve site speed!
Crawling responsibly - but faster!
No matter how many times we say 'slower is better', we know the stock answer is always 'yeah but I want to go faster'.
Without wanting to compare crawling a website to underage sex; "if you're going to do it anyway, at least do it responsibly!"
In Sitebulb we give users the option to increase speeds up to 25 URLs/second, and even control the threads with no rate limit. Suffice it to say we advise caution when doing this.
We suggest you consider the following:
- Think about when you're going to crawl the site. Crawling an ecommerce site at lunch time is probably not a good idea. Look at Google Analytics to check when the site is at its quietest.
- The server must be able to handle the through put as well. Do you know the spec of the machine? Is it in a shared hosting environment?
- Can the CMS and database handle a barrage of requests?
- Is the HTML clean, not bloated and broken?
- Check in on the crawl at various points. Has the TTFB increased dramatically? If so you may need to pause the audit and slow it down.
Finally - what do Google say about it?
Google is a company literally built on crawling, and they sure as shit care about getting things done fast. It's fair to assume they know a thing or two about it.
In their own words (emphasis mine):
"Our goal is to crawl as many pages from your site as we can on each visit without overwhelming your server's bandwidth."
Whether you stay 'slow and safe' or try to push the boundaries of what you can get away with, we urge you to take a little time to make sure you're crawling responsibly.
You might also like:

Patrick spends most of his time trying to keep the documentation up to speed with Gareth's non-stop development. When he's not doing that, he can usually be found abusing Sitebulb customers in his beloved release notes.
Related Articles
 AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean
AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean


 What AI Agents See: The Accessibility Tree Is an SEO Surface
What AI Agents See: The Accessibility Tree Is an SEO Surface
 The Brand-First Technical Audit: Why Your Entity Health Is a Technical SEO Problem
The Brand-First Technical Audit: Why Your Entity Health Is a Technical SEO Problem

 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.