
Does Google Index JavaScript? Impact of JavaScript Rendering
 Patrick Hathaway
Patrick Hathaway
Updated September 5, 2025
When you’re evaluating a website from a technical SEO perspective, the first question is still the same as it’s always been: what’s actually indexed?
At the most basic level, you need to establish:
Are the pages that should be indexed actually showing up in the index?
Are the pages that shouldn’t be indexed being correctly excluded?
Indexing is tightly bound up with crawling. Googlebot requests a page, parses what it finds, pulls out links for the crawl queue, and keeps going. Simple enough.
But in 2025, that process doesn’t stop at raw HTML. Google now routinely renders pages with headless Chromium before deciding what to index. This extra rendering step means JavaScript can completely change what Google ends up seeing; titles, canonicals, meta tags, links, even the page copy itself.
And it’s not just Google you need to think about. Most LLM crawlers and AI-powered search tools also don’t execute JavaScript; they consume whatever is in your raw HTML. (Learn more about this in our free JavaScript SEO training course.) If your key content only appears post-render, not only might this be slowing down indexing in search engines, but it might also be inaccessible to some LLM crawlers.
So the real question isn’t just “does Google index JavaScript?” The answer is yes, mostly. The better question is: how does JavaScript rendering impact indexing, and when can it break your expectations? That’s what this article will unpack.
Interested in learning about JavaScript SEO? Register for our free on-demand training.Sign up now.
Table of contents
You can jump to a specific area of the guide using the jumplinks below:
What is browser rendering?
In SEO we talk about rendering as shorthand for browser rendering, which is the process of taking code (HTML, CSS, JS) and turning it into the visual page you see on screen.
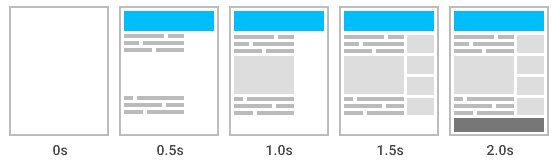
Search engines do the same thing at scale with a headless browser, which runs without a user interface. It executes scripts, builds the DOM, and then hands back the rendered HTML for indexing.
Does Google index JavaScript?
Since Chrome 59 (2017), Chromium has included Headless Chrome, which allowed Googlebot to render web pages at scale; and website crawling tools (like Sitebulb) to mimic the same.
So yes: Google does index JavaScript content. But, as we discussed in our Real-World JavaScript Problems webinar, it’s not that simple. Indexing depends on resource availability, render queue delays, and whether your scripts block or mutate important elements.
As Google’s own docs explain: “Googlebot queues all pages for rendering, unless a robots meta tag or header tells Google not to index the page.”
In practice: noindex = no render. And even when a page is rendered, the indexed content may not look the way you expect.
The evolution of crawling
Back in the day, Googlebot just parsed the HTML it got from the server (what you see when you hit 'View Source'). Straightforward.

But as sites became increasingly JavaScript-heavy, this broke down. Scripts can rewrite titles, inject or remove links, and replace entire content blocks. What’s in the response HTML may look nothing like the final rendered DOM.
That’s why Google now cares far more about the rendered HTML than the raw response when making indexing decisions.
How to view rendered HTML
View Source = raw response HTML (pre-JavaScript).
Inspect → Elements in Chrome = rendered DOM (post-JavaScript).
If you are unsure what a 'DOM' is or are unfamiliar with the phrase, then a bit of additional reading might help:
Core Principles of SEO for JavaScript (a bit old now but still relevant and a really good primer for understanding how it all breaks down)
Whether or not you did the extra reading above, don't be put off by the phrase. Effectively, we can consider this to be the rendered HTML.
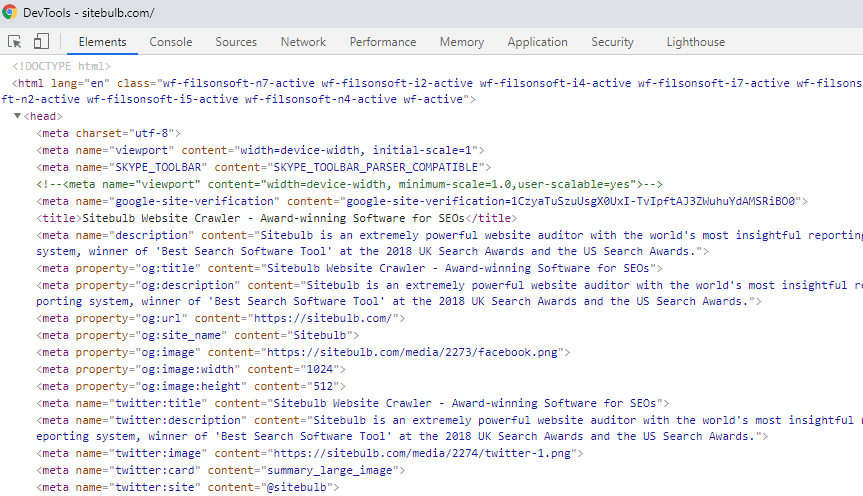
Differences between response and rendered HTML
If you want to know what Google actually sees, use Search Console:
Go to URL Inspection
Click Test live URL
Then View tested page → HTML tab
This shows you the rendered HTML Googlebot processed.
This is a web page that is almost completely dependent on JavaScript. View Source (on the left) basically contains nothing but some scripts. Inspect (on the right) shows 'normal looking' HTML, which is the data that has populated once the scripts have fired.
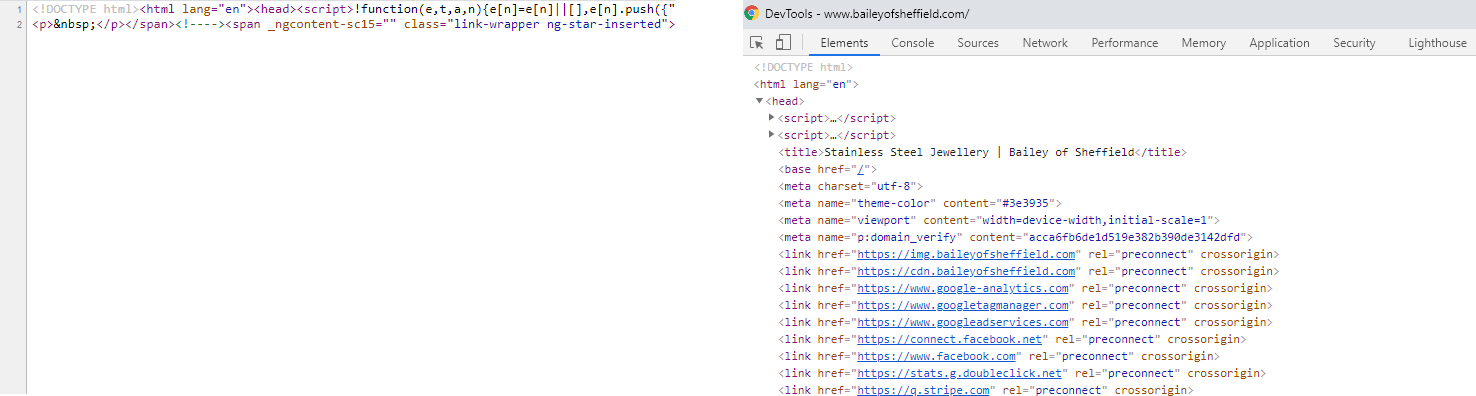
How Googlebot handles rendering
Here’s the workflow simplified:
URL picked from crawl queue.
Robots.txt checked.
HTTP status checked.
Response HTML parsed; robots tags and href links extracted.
In parallel:
Links from response HTML queued.
URL queued for rendering → headless Chromium executes JS → rendered HTML parsed.
Rendered HTML processed, links extracted, content indexed.
In graphical format, this looks like:
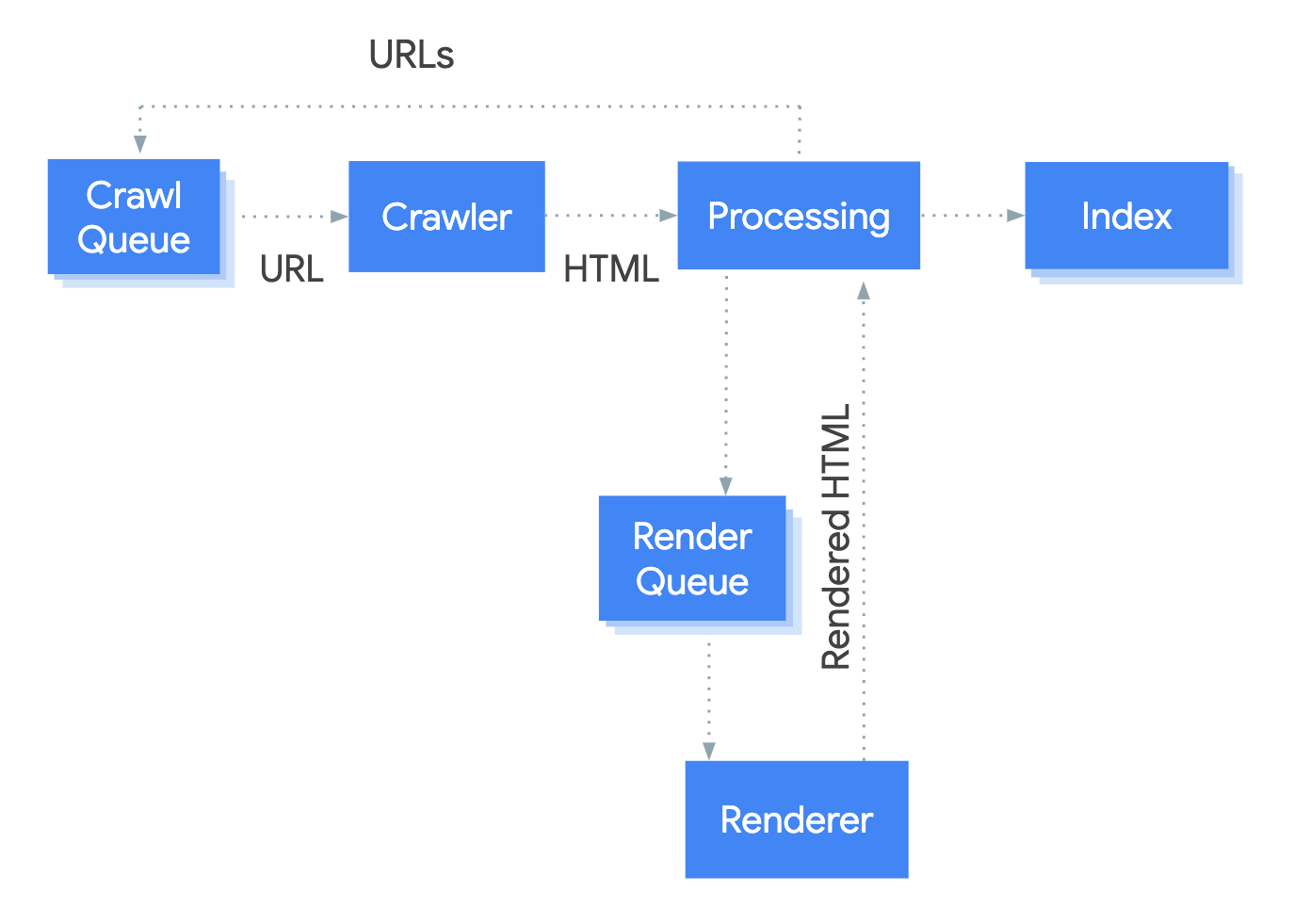
Stage 5 is the most complex to get your head around, because things are happening in parallel. It is also necessarily more complicated, because Google is making decisions on which pages to render based on the result of the meta robots check.
Specifically, from their documentation Understand the JavaScript SEO basics:
"Googlebot queues all pages for rendering, unless a robots meta tag or header tells Googlebot not to index the page."
Bottom line? Stage 5 depends on Google’s render queue. Rendering is expensive, so delays happen. That’s why what you see indexed isn’t always up-to-date with your latest JS changes .
Why is using a Chromium based crawler important?
Because rendering is slower and resource-heavy, it is often an optional setting on many SEO crawlers, with some even charging extra for rendering. But understanding whether your website renders content with JavaScript and using the correct crawling settings is fundamental to accurate auditing.
If you only ever crawl response HTML, you risk missing:
Titles rewritten in JS
Canonicals changed post-load
Meta robots flipped from index to noindex
Links injected or removed
To render JavaScript when crawling with Sitebulb, simply choose the 'Chrome Crawler' in the audit setup process. In Screaming Frog you have to select rendering from a setting menu. In an enterprise crawler like Lumar and OnCrawl you have to pay extra to enable rendering.
There are 3 types of websites
You can roughly bucket sites like this:
No JavaScript: Rendered HTML = Response HTML (e.g. Sitebulb’s own site).
Key content inserted with JavaScript: Rendered HTML ≠ Response HTML (e.g. React SPAs).
Some elements changed by JavaScript: Mostly the same, but JS changes key elements (the dangerous middle).
Sites built using JavaScript frameworks (e.g. React) are examples of #2. These ones are pretty easy to spot - try and crawl using the default 'response HTML' option and you won't get very far - you literally need to use a Chrome-based crawler (read How to Crawl JavaScript Websites for details why).
Type #3 is where SEOs get caught out. Crawls look fine, but JS quietly flips a canonical, injects links, or overwrites titles.
What content does JavaScript change?
Here are some of the page elements that may be deleted, created, or modified by JavaScript:
Meta robots
Canonicals
Titles
Meta Descriptions
Internal Links
External Links
As an SEO, if that doesn't worry you, you have your priorities wrong.
How to compare response vs render
Sam Torres wrote an excellent guide on how to audit JavaScript for SEO. Best practice is to compare the response HTML with the rendered HTML.
“But how?” I hear you cry. Fear not, Sitebulb gives you a Response vs Render report, highlighting exactly where JS:
Creates new elements
Modifies existing ones
Duplicates them
Or removes them entirely
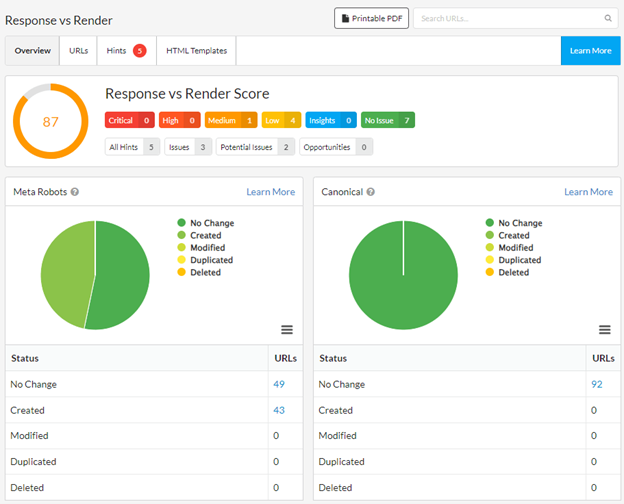
With the Response vs. Render report enabled, Sitebulb will even provide you with page-by-page data about the difference in the DOM once JavaScript is rendered.


Why you need to investigate this stuff
Google’s Martin Splitt once suggested SEOs should “just assume your pages get rendered and get on with it.”
As far as I can see, to "assume my pages get rendered and get on with it" is to fundamentally misunderstand the purpose of an SEO.
It's our job to not "just assume and get on with it". It's our job to not accept things on blind faith, but to dig and explore and investigate; to test and experiment and verify for ourselves.
"We will not go quietly into the night!"
President Thomas J. Whitmore, Independence Day
Google optimises for the aggregate. SEOs optimise for the specific. If rendering changes how your site is indexed, you need to know. Because:
Pages can suddenly become non-indexable.
Content can disappear or mutate.
Internal links may not exist when Google first crawls.
And remember: it’s not just search engines. Most large Language Models (LLM crawlers) don’t render JavaScript either. They consume raw HTML/DOM. If your important content only appears after JS execution, you’re invisible not just to Googlebot, but to AI-powered assistants as well.
So test it. Crawl it. Render it. Compare it. Investigate it. Because until bots and models start executing every line of your JavaScript (don’t hold your breath), JavaScript rendering will remain one of the most important technical SEO checks you can run.
TL;DR
Google does index JavaScript content, but only after rendering, and not always consistently.
noindex pages aren’t rendered for indexing: noindex ⇒ no render.
Always compare response vs rendered HTML for titles, canonicals, robots, and links.
Use Search Console → URL Inspection → Test live URL → View tested page to see Google’s rendered HTML.
Critical content and links should be present in the initial HTML — bonus: LLM crawlers don’t run your JS either.
You might also like:

Patrick spends most of his time trying to keep the documentation up to speed with Gareth's non-stop development. When he's not doing that, he can usually be found abusing Sitebulb customers in his beloved release notes.
Related Articles
 Silo-Busting: Integrating SEO into Dev and Design Workflows
Silo-Busting: Integrating SEO into Dev and Design Workflows


 SEO & UX: Organic Growth via “The Retention Ladder”
SEO & UX: Organic Growth via “The Retention Ladder”

 AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean
AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean

 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.