



Why Your SEO Strategy Still Matters for AI Search (And What Needs to Change)
 Jojo Furnival
Jojo Furnival
Published February 9, 2026
In a recent Sitebulb webinar, Jes Scholz (growth marketing consultant specialising in entity authority) and Dan Petrovic (founder of DEJAN agency and machine learning enthusiast) tackled one of the most contentious questions in SEO right now: has AI search changed everything, or is it just more of the same?
The answer is, of course, IT DEPENDS (lol). It depends which “camp” you’re in.
Some people are insisting we need to rebrand everything as "GEO" (generative engine optimisation) and learn entirely new skillsets. Others are in what Dan calls the "denialist camp," claiming nothing's changed and we should just keep doing what we've always done.
As with almost everything under the sun, the real answer is in the grey area somewhere in between those two extremes.
The reality is that AI search has added a new layer of complexity on top of traditional search, but it hasn't replaced the foundations. Think of it like when mobile-first indexing arrived. The fundamentals of good SEO didn't suddenly become irrelevant, but teams that ignored the mobile-specific considerations got left behind.
Here's what's actually happening and what you need to do about it.
Contents:
What actually happens between a prompt and a citation
When someone types a query into Google's AI mode or ChatGPT, there's a wonderfully complex process (only somewhat understood by me) happening in the background before they see a response with citations. Understanding this pipeline helps explain why some of your content gets cited and other pieces don't, even when they're ranking well in traditional search.
Dan walked us through the entire process:
Step 1: Reformulation into multiple queries
First, the system takes the user's prompt and reformulates it into multiple synthetic search queries. These aren't the queries the user typed; they're what the system thinks it needs to search in order to answer the question properly. There might be two queries, or six, each bringing back a unique set of results.
Step 2: Shortlisting
From several hundred results, the system filters down to just a few through a process that Dan calls re-ranking (though it's more nuanced than that).
Step 3: Relevance scoring
Then, for each of those remaining results, the system looks at the cached version of the page and scores individual passages against the query using something called a cross-encoder model.

“The content is then scored against a query in each passage by using something like…a model called cross-encoder. Think of it as a BERT or an embedding model that takes both the query and the target chunk, embeds them together in the embedding space, and then does the scoring.”
Step 4: Grounding snippet
The system plucks the most relevant bits from each page and creates what's called a "grounding snippet" for the model. These snippets, along with the reformulated queries, then go into the actual language model's context.
Here's where it gets interesting: the model has biases baked in from its training. It's been influenced by everything it has seen during pre-training and fine-tuning.
“You're hoping for the best that the pre-processing pipeline sent the right things to the model that speaks to your product, that speaks to your brand, that conveys the message properly. And then the model synthesises the results and attaches the citation to the grounding source.”
If the user continues the conversation, this entire process repeats again and again, with multiple cycles happening throughout the chat session.
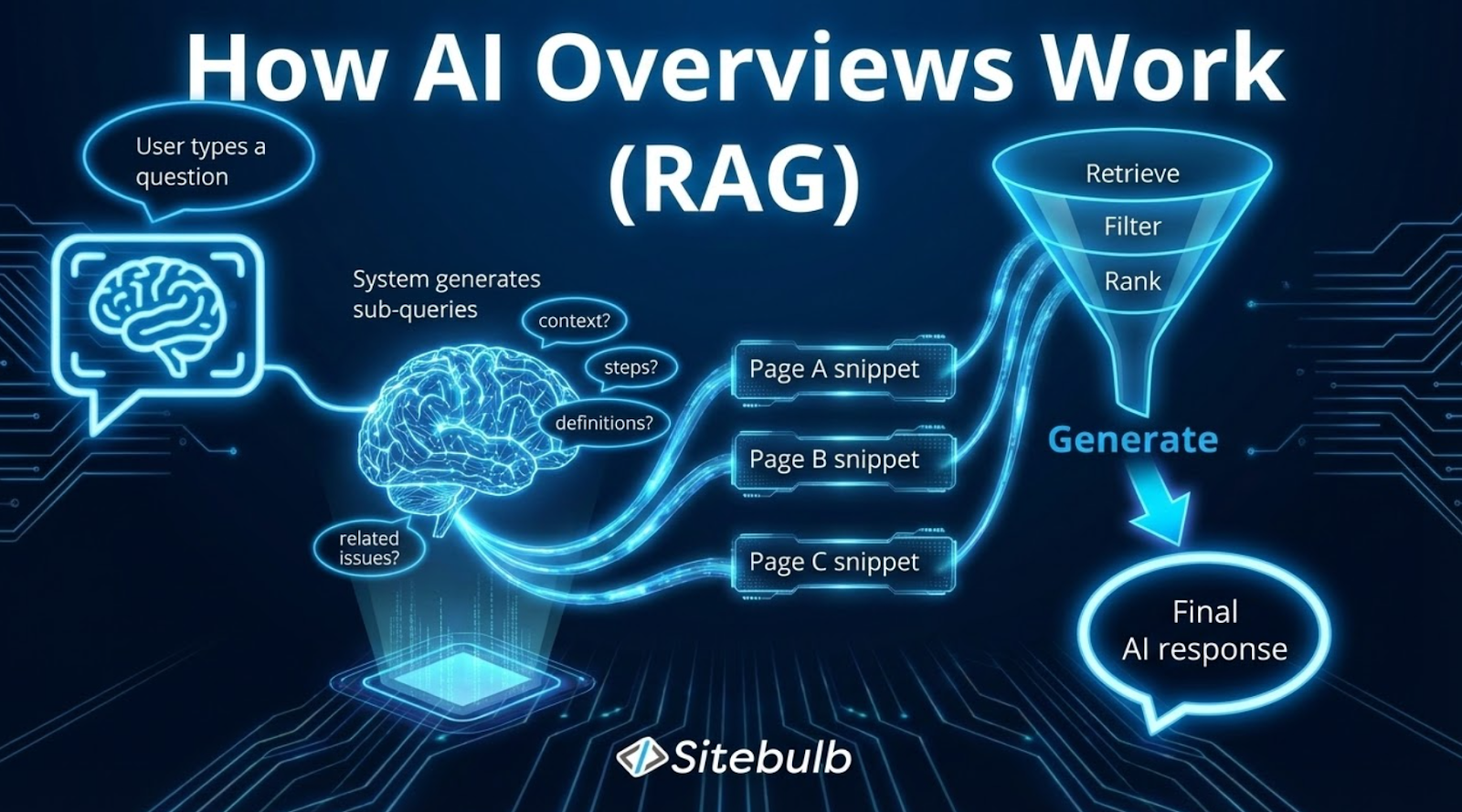
The key difference from traditional search is control.
In traditional search, you can write and optimise your meta description and title tag, and unless Google rewrites it for you, the user sees those and decides whether or not to click.
With AI search, you're at the mercy of the pre-processing pipeline to send the right portions of your content to the model. You might have a thousand-word article, but the model might only see a couple of hundred words from it. And you won't know which couple of hundred words unless you test.
This also explains why some perfectly good content doesn't get cited. It's not necessarily that your content is bad; it might be that the wrong bits made it into the grounding context.
Why longer content isn't always better for AI citations
There's been quite a bit of discussion lately about Dan's research into what he calls the "grounding budget." The term has stuck, even though Dan didn't name it that himself. But the concept is crucial for understanding how to structure content for AI search.
Google (and other AI systems) have a fixed number of tokens they're allowed to use for grounding each ranking result. Tokens are the units that language models process, and they're roughly equivalent to words or word fragments.
This creates an interesting dynamic. If you have a 1,000-word article, a larger portion of that article will go into the grounding context. If you have a 10,000-word comprehensive guide, a smaller proportion will be used. Google's system uses extractive summarisation to pluck what it considers the most relevant bits based on the query.
“If you have a tiny little article, 100% of it will go into grounding. But I'm not advising that people necessarily write ultra short things.”
And that's the important nuance that some people missed when this research first came out.
The solution isn't to make everything shorter. Google's snippet-building system is actually quite sophisticated. It can identify relevant passages from longer content. The question is whether those passages accurately represent your brand and product.
Dan's advice is to measure first: "One thing is for you to do nothing and just measure what's happening in the AI search to see if you are misrepresented, and act on it only if you have a problem."
If AI systems are citing you and the citations accurately reflect what you want to communicate, you don't have a problem. If they're consistently pulling the wrong sections or misrepresenting your offering, then you need to look at content structure.
And on this, the research Dan conducted into how users actually read content is pretty cool. He set up a tricksy little experiment with a survey asking people whether they are "readers" or "skimmers," but had JavaScript running in the background tracking their actual behaviour on the page.
The results? Everyone spent about two minutes, regardless of what they claimed.
People who declared themselves thorough readers, who "read everything word for word," didn't actually do that. Dan calls them "aspirational readers." They feel like they read everything, but the data shows they don't.
"The content piece has to sell itself to the reader for the reader to commit their time to read the full thing," Dan noted. "Is your content piece fit for that?"
Dan even built a tool that acts as a content substance classifier, telling you if your content is largely fluff or substance and identifying which specific sentences are which.
As an experiment, I chucked the text of this article through the tool to see what it would come up with, and this was the result:
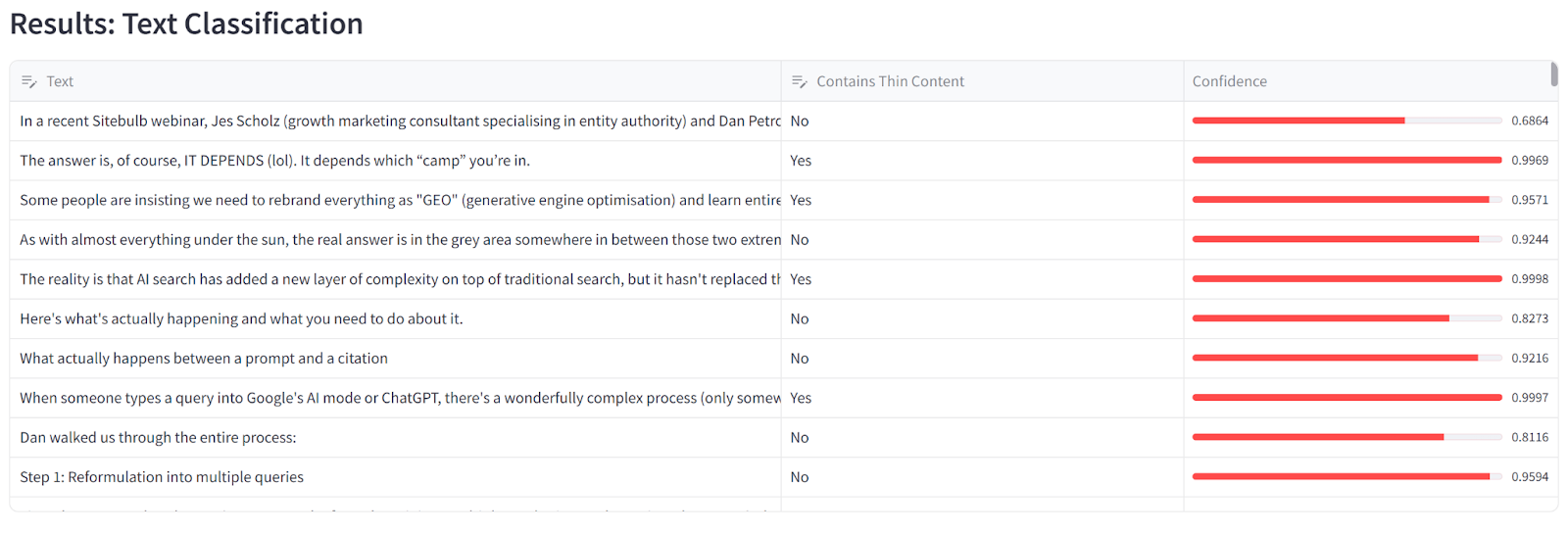
There's what Dan describes as a "beautiful symmetry" between how AI and humans perceive content. Both look for cues, attention patterns, quick summaries. The top and bottom of content get attention; the middle gets lost. Not only that, AI and humans both struggle with content that's 90% fluff and 10% actual ideas.
So the takeaway isn't "write short content" or "write long content." It's to write information-dense content where every section conveys something valuable (*nervously re-evaluates all previously written content). Structure it with clear headings and logical flow so that extractive summarisation has the best chance of pulling representative passages.
AI system bias: When ranking number one still isn't enough
Just to make things more difficult, e ven if you're ranking well and your content is brilliantly structured, you still might not get recommended by AI systems. And the reason is both fascinating and wildly frustrating.
Dan introduced two concepts that are crucial for understanding AI search: primary bias and selection rate.
Selection rate:
Selection rate is essentially your new click-through rate, except models don't click; they select.
When a model has five results in its grounding context, it might prefer one over the others for a variety of reasons. Position still matters but brand recognition is a huge factor.
If the model is familiar with one brand and unfamiliar with the others, it's more likely to recommend the familiar one. Or if it's familiar with all five brands, it might find one particularly relevant for what the user needs based on its training.
“Models are just statistical machines and they snap to their probabilities. You want to be the brand that the model snaps to when it's associating things with a certain entity [or] product.”
This stems from the model's pre-training (where it learns language patterns) and fine-tuning (where it's aligned with human values through reinforcement learning). Eventually, the model is baked and released with a worldview. If you probe the model enough times with the same types of queries, you start to see patterns in where its biases lie.
Primary bias:
This is what Dan calls primary bias: the raw, naked version of the model without the internet plugged into it. If you had the model running on your machine and asked it a question, whatever it answers is its unaltered opinion before being influenced by search results.
And here's the thing that should make every SEO sit up and pay attention: primary bias influences which search results get selected from the grounding context.
Real world example
Dan shared a case study that perfectly illustrates this problem.
They had a client in Germany selling sports equipment to a worldwide market. The models simply wouldn't recommend them to non-German customers. If the customer was German, fine, the brand would appear. Australian customer? The model would decide the German brand "wasn't relevant" and recommend American or British alternatives instead.
This is despite the client having good products, decent rankings, and perfectly adequate content. The model was biased against them based on geography.
The fix took two approaches and six months of hard work.
Fix 1: Brand to entity association
First, they did what Dan calls "brand to entity association" work. They constantly mentioned the client alongside the big players like adidas, Nike, and Under Armour, trying to bring them closer in status. Think piggybacking on established brands to build association.
Fix 2: Americanisation
Then they "Americanised" the client. They created content associating the brand with America, the US, New York. They were deliberately trying to break the geographic bias the model had formed.
Sounds like a smart approach.
But SEO is both a nightmare and a little bit ridiculous, so of course nothing happened for six months. They did all this work and saw zero results. Aaaaaaand then Google released Gemini 2.5 and it suddenly worked!
Models are frozen in time. You can do all the hard work, but you won't see results until they release a new version or a fine-tune of the existing model.
"If it wasn't the model release, nothing would have happened," Dan said. "It's like we are in the early days of SEO, we need to wait for the Google update to see the results."
But there's another part to this story.
Fix 3: Local SEO
While all that brand association work was happening (and apparently not working), they also made basic localisation changes to the website. They removed the "GmbH" from the company name and added "LLC." They changed the German phone number to a +1 number. They updated the address to show a local presence.
Once they had decent rankings and the model update happened, these localisation changes worked almost immediately. Within a week, the brand started being recommended.
The crucial point Dan kept coming back to throughout the webinar is this: Nothing happens without normal SEO.
“That's a really easy and simple case where it worked really well with normal SEO and it took a long time… Nothing happens without SEO. If you're so arrogant and thinking, 'Oh my brand will be the top of mind when the model speaks,' you have to be like a top, a major, major brand.”
Unless you're Nike or Apple, you can't rely on the model's training data alone to make you top-of-mind. You need to be ranking in traditional search to even be in the consideration set. The model bias work matters, but it's meaningless without the SEO foundation.
Interestingly, model bias can work in your favour too. It's not always negative. The model might be biased towards your brand for certain queries based on its training. Understanding both the positive and negative biases is valuable because it tells you where to focus your efforts.
Why content distribution beats content volume in AI search
Jes Scholz brought her refreshingly practical perspective to the question of resource allocation. If a team only has budget to focus on one thing, should they spend time perfecting individual content pieces or building brand distribution and presence?
Her answer was unequivocal: distribution.

“You could put 50 hours into one piece and then it completely flops, while if you put 50 hours into distribution, you're going to get more impact.”
Obviously, you need good content to distribute. One requires the other. But the equation has shifted. You'll get more impact taking a selection of really good, focused content that's distribution-worthy and getting it in front of as much of your target audience as possible, rather than producing many pieces that live on your website waiting for people to find them.
From an AI search perspective, this distribution work isn't just about reaching human audiences. It's about influencing how models perceive your brand.
Jes uses a brilliant analogy: "It doesn't matter if I say I'm a hula-hoop champion and some random person says the same thing. [But] It would matter if the Olympic committee said that I was a hula-hoop champion."
(For the record, Jes is not actually a hula-hoop champion, which is disappointing.)
The point is that who says something about you matters enormously.
This is classic brand building principles meets AI search behaviour. It's not about getting as many mentions as possible on any site. It's about relevant sites from Google's perspective, from the knowledge graph's perspective, corroborating who you are and what you do.
This connects to what Jes calls "category entry points," a concept borrowed from Byron Sharp's marketing research.
In a user's mind, certain triggers make them think of buying situations, which then make them think of specific brands. Maybe you're walking down the street, you see someone in a cute top, and you think, "Oh, I haven't been shopping in a while." That trigger leads to recalling your favourite brands for clothing.
AI models behave similarly. When someone asks an AI for recommendations, the model looks at what brands it associates with specific entities and situations.
This is why brand distribution matters so much. You're not just trying to reach potential customers directly. You're building the network of associations that models use to determine relevance and authority.
Product feed optimisation: Why data completeness beats website polish
There's a dangerous assumption floating around that having a product feed means you're ready for AI search. Jes has consulted with multiple teams who say confidently, "Yeah, but we've got a product feed already."
Her response? "Great. How many attributes have you got filled in there? How accurate are those attributes?"
That's usually when things start falling apart.
The reality is that the competitive advantage in AI search sits in your data completeness and the granularity of your categorisation, not your website design and polish.
Here’s an example
Imagine you're searching for a black dress. But you're not just looking for any black dress. You want it in a size six, A-line cut, with jewel detailing. Maybe it's for a specific occasion or body type.
If all you have in your product feed is "dress" and "black" (or worse, "noir" because someone thought that sounded aspirational on the website), you're not going to match that query in AI search.
The solution is to go deeper than your competitors on every possible attribute. This applies across industries, not just ecommerce.
Property portals? Don't just say "5 bed rental for X price." Include that it's pet-friendly, furnished, serviced, on the fourth floor with northern light. List every detail that might matter to someone's search.
B2B SaaS? Your product database should include not just features but use cases, integrations, company size suitability, industry-specific applications.
Content publishers? Each article needs rich metadata about topics covered, level of detail, target audience, related concepts.
“Go deep into these details, that's where the competitive advantage is. The competitive advantage is in the database, not the website so much.”
This becomes even more important as AI systems become more sophisticated. Dan mentioned that Gemini is multimodal now, with agentic vision capabilities that launched the day we hosted this webinar. So the system can evaluate the content of your product imagery as well as text.
In the future (and it's not far off), this will extend to video content. "Think about quality of your media as being part of the content, not just text," Dan said.
The point Jes kept returning to is that you need to structure your content and data so it can be chopped up into feeds and queried effectively by multiple platforms. It's not just about one AI system. It's about creating a database that works across all the surfaces where your audience might encounter your brand.
SEO fundamentals for AI search: What actually needs to change
Ok, here are some practical steps you can take today to prepare for AI search without completely abandoning everything you know about SEO.
1. Fix the basics first
Dan's number one recommendation: stop blocking AI bots.
Many brands have this notion that AI systems are "stealing" their content for training, and they feel ripped off. So they've toggled on Cloudflare's AI bot blocking or similar protections. Dan's advice is blunt: "Allow training, allow theft, allow content use, get into the model's mind as aggressively as quickly as you can."
Beyond that, it's back to SEO fundamentals:
Structure your content properly and make it obvious
Don't hide important information in tabs and accordions, especially if they don't render properly
Ensure your pages are server-side rendered so content is easily accessible
Allow proper page content fetching
"Just do some SEO,” said Dan (which I loved!), because AI is an interpretive layer on top of search.
2. Prepare for the agentic web
If you're a brand and you've got the basics sorted, the next level is staying on top of emerging protocols and technologies:
Agent-to-agent protocols
Agent payment systems
Product feeds for AI marketplaces
When OpenAI announces they have a marketplace, are you ready to be in it?
We're heading towards a world where transactions happen in the background with no website visits. Dan predicts that the agentic web will arrive in 2027. Websites will become optional surfaces, interfaces rather than necessary destinations.
"What does an SEO do in the world where everything happens in the background, nobody visits the page?" Dan asked. The answer is exactly the stuff we've been discussing:
Product feeds need to be comprehensive
Structured data needs to be impeccable
Content needs to convey your offering clearly in whatever chunks might be extracted
3. Measure what matters
Jes makes a compelling case that share of voice is the metric that unifies traditional and AI search performance. Report on share of voice across all surfaces, she said: traditional search, Google Discover, AI platforms, social media.
This isn't a new concept in marketing. Les Binet's research proves there's a correlation between share of search and market share. In fact, share of search is a predictor for market share. Jes believes this will translate to AI surfaces as they become more prominent.
When people are new to a category and don't know what they want to buy or who to buy from, they're increasingly asking Gemini or ChatGPT first. If you're not recommended in those early consideration moments, you're out of the race before it even starts—I heard this exact same thing at last year’s brightonSEO from Dixon Jones:
But here's the crucial point Jes made about how to use AI prompting for measurement: treat it like focus groups, not absolute truth. Take a sample that's as unbiased as possible, see what that sample says, act on the data, then go back and re-ask a new sample to see what's changed.
Don't fall into the trap of running 100 or 1,000 prompts daily and treating those rankings as gospel. As Dan commented, "Talk about meaningless metrics. That's worse than clicks."
4. Test model perception
Dan's approach to measurement is more technical (no surprises there!). He recommends associative probing to understand what the model associates with your brand, followed by relevance probing to see if it would recommend you for specific queries.
Here's how it works.
Ask the model what it associates with your brand. It gives you a list.
For each thing it mentions, you probe whether it would actually recommend you if someone was looking for that specific thing. Ask for simple yes or no answers rather than full explanations.
The key is repetition to get statistical confidence. If you ask once and get a "yes," that doesn't tell you much. If you ask 100 times and get "yes" 63% of the time, now you've got data you can work with.
“For every entity, I explode into query fan-outs. For every fan-out, I develop out the prompt. So for each fan-out, I say, 'Would you recommend this brand for that product? Yes? No?' And I repeat that 10 or 100 times and I get the statistical value out of that.”
This process identifies the weak spots in the model's perception of your brand. Maybe it strongly associates you with one product line but barely recognises another that's equally important to your business. So then that becomes guidance for your PR team, your content team, everyone.
Dan has tools for this, though he mentioned they're not all publicly available yet. If you're serious about model probing, it's worth reaching out to him.

The overarching message from both Jes and Dan is that you have time, but not unlimited time.
Most of your addressable market is out of market at any given moment anyway. Even for something you think you buy frequently, like toothpaste, you're probably only purchasing it once or twice a year.
B2B buying cycles haven't suddenly accelerated just because AI search exists. The vast majority of your audience comes to your website once a year, does their research or purchase, and disappears.
“You've got time to catch up, especially because there are a lot of now documented tactics that are relatively proven to move the needle in the right direction.”
Existing SEO skills vs new search optimisation tactics
The central tension running through this entire webinar is one that the SEO industry needs to grapple with honestly: Traditional SEO fundamentals have not become less important. If anything, they're more crucial than ever because you can't even begin to influence AI systems if you're not ranking in the first place.
But those fundamentals alone aren't sufficient anymore. You can have perfect technical SEO, brilliant content, and strong rankings, and still not get recommended if the model is biased against your brand or doesn't have strong associations between your brand and relevant queries.
The industry doesn't need a rebrand to "GEO" (ick). That's not helpful. But it does need to acknowledge that AI search has added a new dimension to the work.
“I'm very much against the rebrand of our industry, but I'm not in a denialist camp saying that there's nothing new to do.”
For Sitebulb users, this means your technical auditing remains as relevant as ever. Ensuring pages are properly rendered, content is accessible, structured data is correct, and site performance is solid—all of that is the entry ticket. It's what gets you into the consideration set in the first place.
The additional work sits on top of that foundation:
Enriching your content database
Building brand associations across relevant platforms
Monitoring how models perceive your brand
Preparing for an agentic future where transactions might happen without anyone ever visiting your website
You can watch the full webinar recording for more insights from Jes and Dan, and if you're not already following them on LinkedIn, that's an easy win right there.
The transformation happening in search is real, but it's not as binary as "everything's changed" or "nothing's changed." It's more nuanced, more layered, and ultimately more interesting than that. The brands that figure out how to operate at both levels – technical excellence and brand perception – are the ones that will maintain visibility as search continues to evolve.
TL;DR key takeaways
💡 AI search uses a multi-stage pipeline where only portions of your content make it into the model's context. Structure your content so extractive summarisation pulls representative passages, and measure whether you're being accurately represented before making changes.
💡 Traditional SEO rankings are your entry ticket, but model bias determines whether you actually get recommended. Without rankings, you're not in the consideration set. But rankings alone aren't sufficient if the model doesn't have strong associations with your brand.
💡 Share of voice across all surfaces (traditional search, AI, social, Discover) is the unified metric that connects to business outcomes. This leading indicator for market share gives leadership a familiar framework whilst capturing your AI visibility.
💡 Your competitive advantage sits in database detail, not website polish. Granular product attributes, comprehensive content categorisation, and structured data depth matter more than ever. Go deeper than your competitors on every attribute.
💡 Start now: unblock AI bots, fix technical foundations, enrich your data, and prepare for the agentic web.

Jojo is Marketing Manager at Sitebulb. She has 15 years' experience in content and SEO, with 10 of those agency-side. Jojo works closely with the SEO community, collaborating on webinars, articles, and training content that helps to upskill SEOs.
When Jojo isn’t wrestling with content, you can find her trudging through fields with her King Charles Cavalier.
Related Articles
 Your Products Are Entities Now. And AI Can Only Work With The Data You Give It.
Your Products Are Entities Now. And AI Can Only Work With The Data You Give It.

 JavaScript SEO in the Age of AI: Will Kennard Answers Your Questions
JavaScript SEO in the Age of AI: Will Kennard Answers Your Questions
 Your AI Assistant Is Biased: Why & How To Write Prompts Mindfully
Your AI Assistant Is Biased: Why & How To Write Prompts Mindfully


 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.