 Patrick Hathaway
Patrick Hathaway
Welcome to the second installment of a 4-part blog series about search engine optimization (SEO) and its interconnectivity with accessibility ('A11Y' - because there are eleven characters between the 'A' and the 'Y'). With this series, Patrick Hathaway from Sitebulb and Matthew Luken from Deque Systems will each write complementary articles on the subject from their unique points of view.
Introduction
In my first article, I covered 'why good SEO supports accessibility' while Matthew wrote about 'why accessibility is important for good SEO,' and these articles can be considered an introduction to the topic, and set the scene somewhat for the blog series.
In this article, I will be exploring the technology of website crawlers, how they crawl, and how 'making websites accessible for crawlers' is very similar to 'making websites accessible for screen readers.'
As we shall see, the way that the technology interacts with website content dictates how websites should be designed and built, and explains why accessibility and SEO are mutually beneficial practices. You can find Matthew's counterpart article, 'SEO and Accessibility are Symbiotic,' over on the Deque blog.
Web technology consumes patterns
Search engines as we know them today are not really so different to where they began, back in the late 1990s with the likes of Yahoo! and Lycos. They were tackling the problem of organising the information of the world wide web and making it findable by everyday internet users, which broke down into three essential tasks:
- Crawling
- Indexing
- Ranking
As a result, the practise of SEO was predicated by this system:
- URLs could not rank for search queries if they were not indexed
- URLs could not be indexed by search engines if they could not be crawled
Although some aspects of this have changed over the 20+ years since, 'crawlability' remains a foundational element of search engine optimisation: fundamentally, your website needs to be crawlable if it is to prosper in organic search.
What is website crawling?
Website crawling is carried out by computer programs, often referred to as 'search engine bots,' 'website spiders' or 'website crawlers.'
Starting from a seed URL, the crawler consumes the HTML of the web page, looking for links to other URLs, which then get added to the crawl queue, and subsequently crawled. This process works iteratively - URLs get taken out of the crawl queue for crawling, as they get crawled, new URLs get discovered, which then get added to the crawl queue.
A crawler program like Sitebulb is designed to focus on a single website - so when all of the 'internal' URLs from that website have been crawled, the crawler will stop. Search engines like Google have lots of seed URLs from many sources, and are constantly crawling and re-crawling pages in order to find new links - and therefore new URLs.
Search engine crawlers are also looking for content within the pages that can be used for indexing - they index a web page alongside the content found on that page; the index is then used to serve results for search queries.
HTML parsing
Faced with the HTML content of a web page, search engines crawlers need to 'parse' the HTML in order to split it up into meaningful chunks - as such, parsing is a fundamental part of the crawling process.
Without going into the full technical definition, HTML parsing is basically taking in HTML code and extracting relevant information like the title of the page, paragraphs in the page, headings, links, anchor text, etc…
It is during this process that links to URLs are discovered (to go in the crawl queue if they are new URLs) and text content is found that can be indexed against the URL.
How crawlers work (pre-JavaScript edition)
For a large chunk of the history of search engines, crawling was a reasonably straightforward task.
Crawling a single page would look like this:
- Crawler makes a GET request a page from the website server
- Crawler downloads the response HTML
- Search engine parses the HTML to extract links and content
- Content and URLs are indexed
When we talk about the 'response HTML' (step 2), this is the equivalent of doing 'View Source' in a browser.

The search engine could take the HTML markup and use it to extract the content they needed for indexing:
- <title>
- <meta robots>
- <canonical>
- <h1>
- <a href>
- Etc…
They could make use of the predictable, hierarchical structure of the HTML, and make further inferences when semantic markup was used:
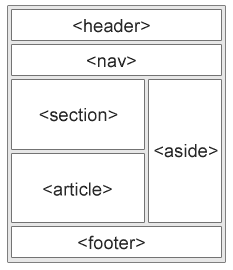
The whole concept of website crawling is built upon this recognition of patterns in the HTML that enable search engines to extract content in a predictable manner.
Screen readers are like search engine bots
Screen reader technology is used to help people who are blind or have limited vision to access and interact with digital content. If you are less familiar with screen readers, now would be a great time to jump across to Matthew's article for an explanation of how they work.
Screen readers need to do a very similar job to a search engine crawler. They need to scan the HTML of a page and parse out the important elements, in such a way that the user can tab through the information to find what they are looking for.
Just like a crawler, a screen reader works through the recognition of patterns in the HTML that enable it to extract content in a predictable manner.
This is why things that are good for on-site SEO are often also good for web accessibility. By including a header 1 you can indicate to search engines the main topic of the page, which performs exactly the same function for a screen reader user.
But the inverse is also true - things that are bad for on-site SEO are also often bad for web accessibility. If you don't include alt text on an image, when a screen reader encounters the image, it cannot describe what it depicts. Search engines are similarly unclear on what the image represents (although they have started trying to 'guess' with AI).
This crossover becomes even more pertinent at the extremes.
Technology can break the patterns
New and innovative web technologies can allow developers to create more immersive, interactive website experiences. The results can be excellent - in terms of user experience, SEO and accessibility.
But certain technologies, if implemented incorrectly, can be extremely damaging.
Enter JavaScript.
How crawlers work (post-JavaScript edition)
It is impossible to discuss the history of crawling without discussing JavaScript. For many years, it proved the bane of SEOs, when dealing with JavaScript-heavy websites.
Why? Because simply analysing the response HTML no longer cut the mustard. As developers were able to access JavaScript libraries that could make 'cooler' websites (e.g. animated or interactive elements), they inadvertently made websites that were not good for crawling.
And this is because executing JavaScript would change the HTML. If we 'View Source' on a website that is heavily dependent on JavaScript, all we get is a big pile of seemingly unstructured code:
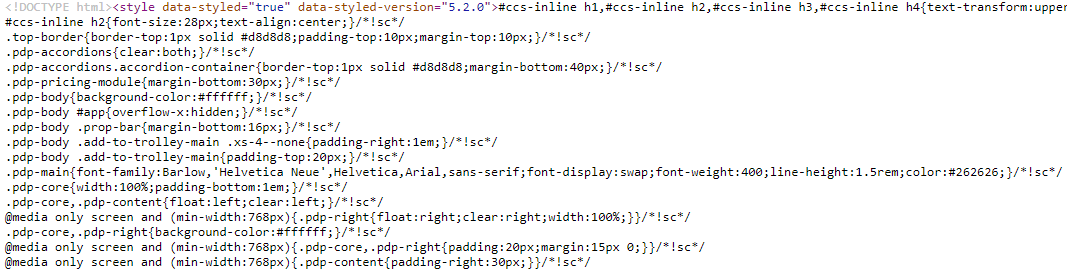
Compare this to the 'rendered HTML,' which we can see if we 'Inspect HTML' in the browser:
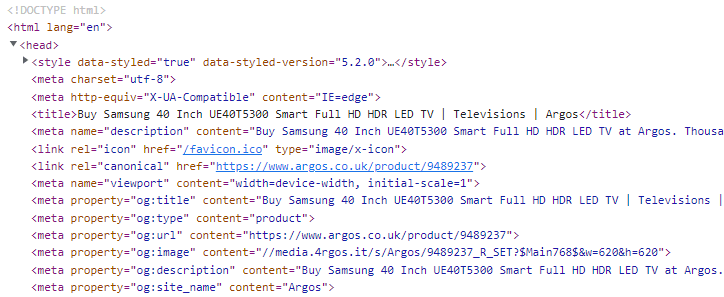
In other words, the familiar patterns and hierarchy of the HTML markup which search engines were relying on was either being changed by the rendering process, or was simply not there at all until the page had finished rendering.
For normal web users, it was the equivalent of viewing websites without JavaScript enabled, which could take a website from this delightfully rich experience:
To this…
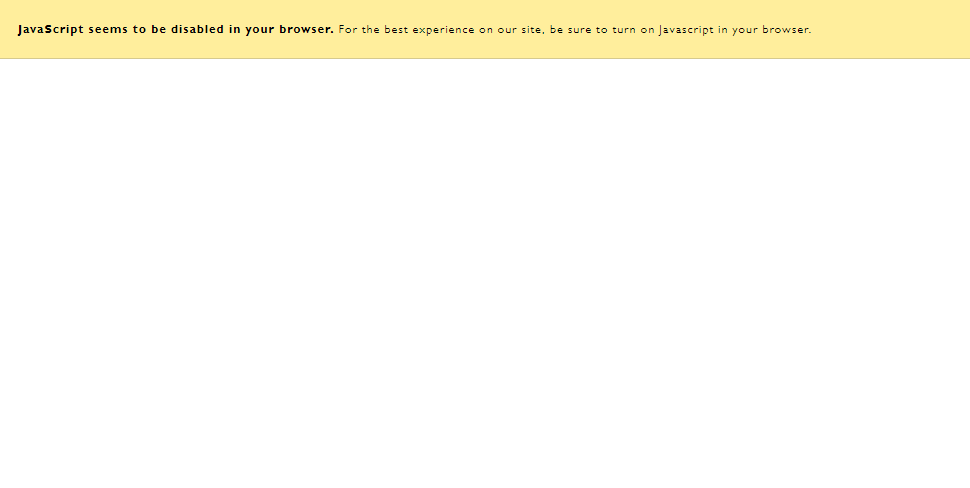
Nowadays, almost every website uses JavaScript to some degree, and as a result of this shift in technology, Google needed to shift their crawling and indexing methodology - they wanted to ensure web pages that they include in their search results were based on the actual page content that searchers would see.
They updated their crawler so that it now crawls and renders web pages, before analysing and indexing the content.
Rendering is a process carried out by the browser, taking the code (HTML, CSS, JS, etc...) and translating this into the visual representation of the web page you see on the screen.
Search engines are able to do this en masse using a 'headless' browser, which is a browser that runs without the visual user interface. They are able to build (render) the page and then extract the HTML after the page has rendered.
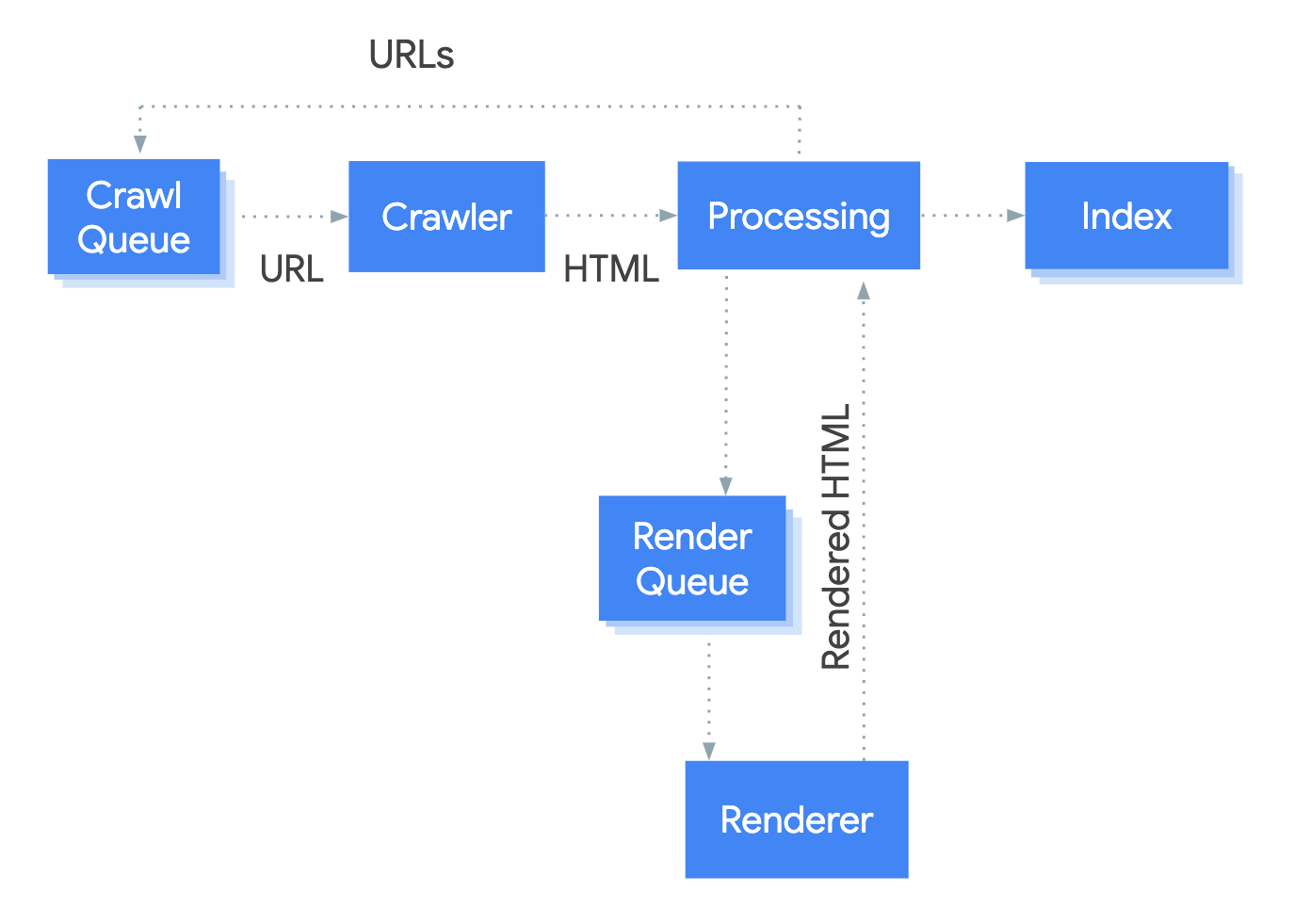
To better understand the rendering process, check out my post 'How JavaScript Rendering Affects Google Indexing.'
The problem with JavaScript for crawlers
Despite Google now committing to use an 'evergreen Googlebot' (i.e. using the latest release of Chromium for rendering), and claiming to render every page they index, JavaScript heavy websites are still problematic.
For example, some websites are stuffed with so much JavaScript code that it takes upwards of 30 seconds to finish rendering all the page content. Google will most likely not wait that long, and may therefore miss some of the content.
You can also get into a really dicey situation if JavaScript is being used to alter indexing signals, for example if you have a noindex tag in the HTML response, but change it in the rendered HTML:

To this day we are still seeing lots of research and guides published by SEOs wrangling with JavaScript SEO issues, and Google themselves have a whole document on how to 'Fix Search-related JavaScript problems'...
...and this is just Google - who are absolutely at the forefront among the search engines when it comes to rendering.
The point is, you need to be extra careful with JavaScript powered websites in terms of SEO - and this isn't really anything to do with the technology itself, but how it ends up being used by developers.
The problem with JavaScript for screen readers
This also holds true for accessibility - a particular web technology is neither good nor bad for accessibility, but how it gets used by developers can have an enormous impact.
Specifically when it comes to screen readers, we know that the HTML structure and patterns are as important for screen readers as they are for search engine crawlers. In particular, screen readers look for semantic landmarks that enable a user to tab around to different logical elements of a given web page.
Enter JavaScript.
More to the point, enter JavaScript frameworks - where basically all of the content on a web page is built using JavaScript. A common problem with JavaScript frameworks is that they don't always output semantic HTML, particularly when a developer isn't trying to output semantic HTML, or isn't even aware that they should.
JavaScript frameworks are new and sexy and cool - most web developer jobs these days are looking for experience with the likes of Angular, React, Vue, etc... But HTML itself… not so much.
For example, React allows you to build and compose components utilising any type of HTML element - whether or not they are semantic. And the underlying HTML semantics can be obscured by the JavaScript code itself.
Younger developers who have only been in the field for the last 5 years may have spent little time learning HTML in the push to learn the latest JavaScript frameworks, so knowing how or why it is important to output semantic code is often not high on their agenda (for more on this topic, it's worth reading 'JavaScript Frameworks & The Lost Art of HTML').
As a result, the use of JavaScript frameworks can mean that the semantic landmarks are absent or inconsistent, taking away the fundamental structure that screen readers rely upon, leading to a negative and frustrating experience for the user.
Cause and effect are symbiotic
Following the rule of cause and effect, if we produce content that does not follow established rules and/or patterns, then the tools that are used to consume that content will no longer work properly. Search engine crawlers may not follow links or index content properly, screen readers may not work efficiently, even sighted readers' comprehension may suffer because the content just does not make sense to them.
The newer technologies we have available today can enable developers to create true digital spectacles that are perhaps closer to art than a functioning and usable website. We're talking fully interactive experiences that make heavy use of video and visual imagery, and eschew the design constraints of traditional web design, like text content, headers and navigation. The experience they are looking to provide may indeed be immersive to some, but at what cost?
The result: For a search engine, the lack of textual content can mean they struggle to understand the context and meaning of the page, and the lack of a logical architecture may affect how link equity is distributed. For a screen reader user, it's nearly impossible to navigate a website that has no wayfinding. How can they skip ahead to the information that's pertinent to their visit when the screen reader can't make sense of it for them? Even for sighted users, the severe deviation from their expectations of 'what a webpage is' means they will struggle to orientate themselves and consume the content in a familiar way.
Following the rules enables interoperability
When two things are built to the same set of standards then each can predict the other's actions. This predictability allows for these two things to be interoperable.
A website that is designed with strong SEO fundamentals is one that is built with crawler accessibility in mind. Where logical internal linking practices are used, where page content is well targeted, where titles and headers are meaningful, where indexing signals are consistent, and where these elements are not damaged by the effects of rendering JavaScript. This is a website that follows the rules of what search engines are expecting, and by doing so it allows the search engine to extract and understand the content in an efficient manner.
A website that is designed with strong accessibility fundamentals is one that is built with screen readers in mind. Where thoughtful information architecture and navigation is used, where content is laid out with strong hierarchy, where pages have titles, where titles are consumable and meaningful, where semantic HTML code standards are used, and where these elements are not damaged by the effects of rendering JavaScript. This is a website that follows the rules of what screen readers are expecting, and by doing so it allows the screen reader user to extract and understand the content in a meaningful and efficient manner.
The symbiotic nature of SEO and accessibility means that they are mutually beneficial - improving one often improves the other. As we stated in the last set of articles in this series, code that is designed and built well tends to be accessible. When websites are accessible they tend to have good experiences as well as good SEO. The interoperability of assistive technologies like screen readers is naturally supported. Everything, as they say, works as expected.
Don't forget to also read Matthew's counterpart article over on Deque. And stay tuned for the next article in our 4-part series.
About Matthew
Matthew Luken is a Vice President & Principal Strategy Consultant at Deque Systems, Inc. For the four years prior to Deque, Matthew built out U.S. Bank's enterprise-level Digital Accessibility program. He grew the team from two contractor positions to an overall team of ~75 consultants and leaders providing accessibility design reviews, automated / manual / compliance testing services, defect remediation consultation, and documentation / creation of best practices. In this program there were 1,500+ implementations of Axe Auditor and almost 4,000 implementations of Deque University and Axe DevTools. Also, Matthew was Head of UXDesign's Accessibility Center of Practice where he was responsible for creating seamless procedures and processes that support the digital accessibility team's mission & objectives while dovetailing into the company's other Center of Practices like DEI, employee-facing services, Risk & Compliance, etc. He and his team's work has been recognized by American Banker, Forrester, Business Journal, and The Banker. In his user experience and service design backgrounds, Matthew has worked with over 275 brands around the world covering every vertical and category. He continues to teach User Experience, Service Design and Digital Accessibility at the college-level, as well as mentor new digital designers through several different mentorship programs around the USA.
About Deque Systems
Deque (pronounced dee-cue) is a web accessibility software and services company, and our mission is Digital Equality. We believe everyone, regardless of their ability, should have equal access to the information, services, applications, and everything else on the web.
We work with enterprise-level businesses and organizations to ensure that their sites and mobile apps are accessible. Installed in 475,000+ browsers and with 5,000+ audit projects completed, Deque is the industry standard.

Patrick spends most of his time trying to keep the documentation up to speed with Gareth's non-stop development. When he's not doing that, he can usually be found abusing Sitebulb customers in his beloved release notes.
Related Articles
 What AI Agents See: The Accessibility Tree Is an SEO Surface
What AI Agents See: The Accessibility Tree Is an SEO Surface


 Webinar: Optimising for AI Agents: What Google's New Guidance Means for SEOs
Webinar: Optimising for AI Agents: What Google's New Guidance Means for SEOs
 Key Learnings from Women in Tech SEO Fest 2024
Key Learnings from Women in Tech SEO Fest 2024
 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.