Sometimes you may find that you want (or need) to restrict the crawler in order for it to crawl the website as you want it to be crawled.
For example:
In all of these cases, you will need to configure the crawler to exclude certain URLs so that they do not end up being added to the crawl queue, which you can do via the URL Exclusions option from the left hand menu of the audit setup.
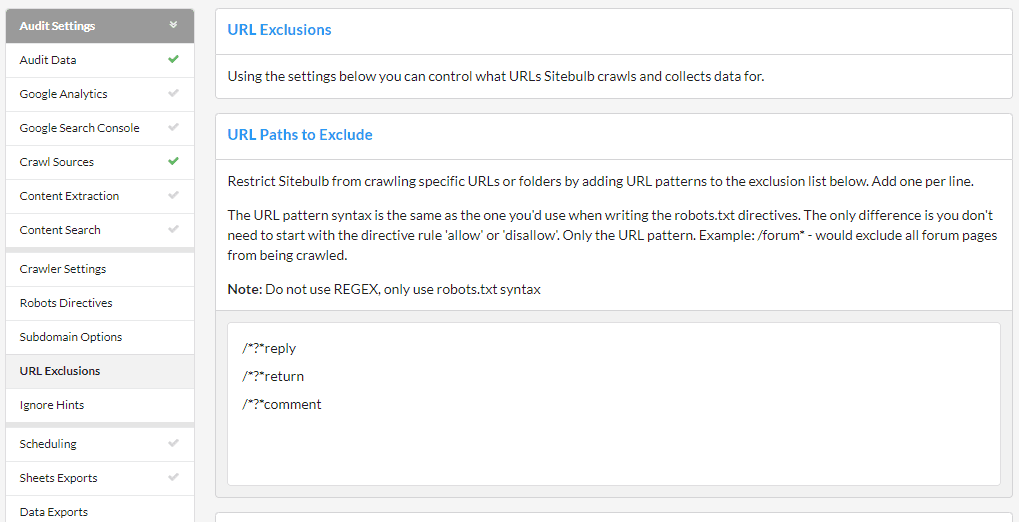
As you scroll down the right hand side, you will see that there are 5 different ways to exclude URLs, each of which is covered below.
Using Excluded URLs is a method for restricting the crawler, and this method allows you to specify URLs or entire directories to avoid.
Any URL that matches the excluded list will not be crawled at all. This also means that any URL only reachable via an excluded URL will also not be crawled, even if it does not match the excluded list.
The list is pre-filled with some common patterns, which you can either over-write or add to using the lines underneath. As an example, if I were crawling the Sitebulb website and wanted to avoid all the 'Product' pages, I would simply add the line:
/product/
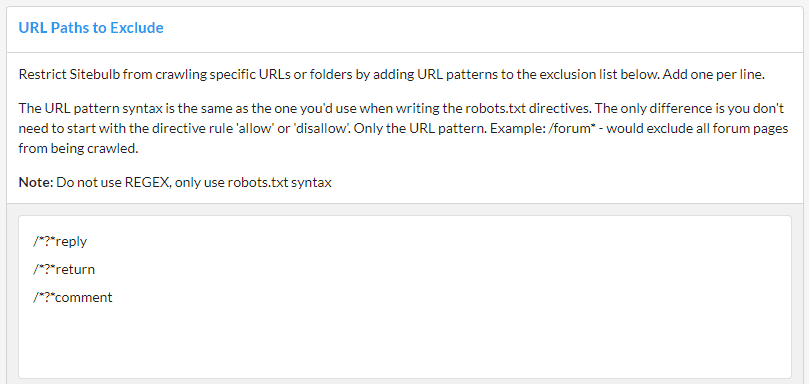
Using Included URLs is a method for restricting the crawler, and this method allows you to restrict the crawl to only the URLs or directories specified.
As an example, if I were crawling the Sitebulb website and only wanted to crawl the 'Product' pages, I would simply add the line:
/product/
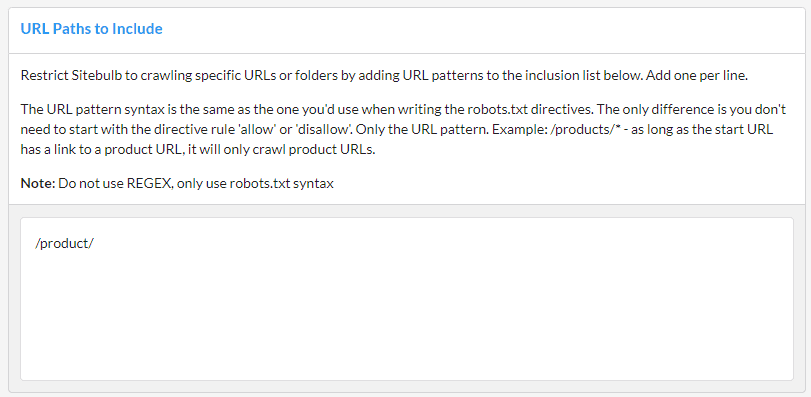
It is worth noting a couple of things:
For any URLs included in the seed list, Sitebulb will also parse the HTML on these pages and extract links - in addition to the Start URL and any other pages crawled.
In conjunction with inclusion paths you have listed. This can be useful when using inclusion rules in cases where the start URL doesn't contain links to all the paths you wish to crawl.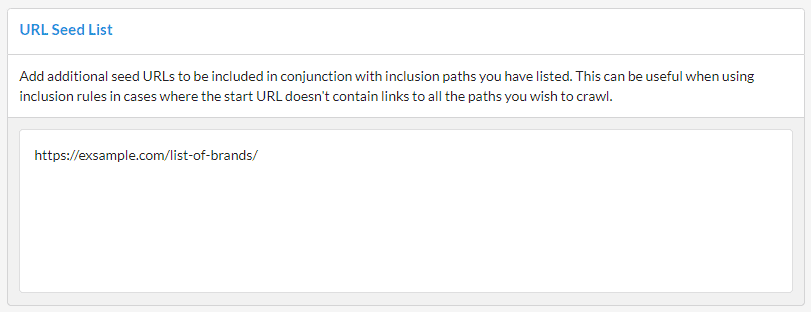
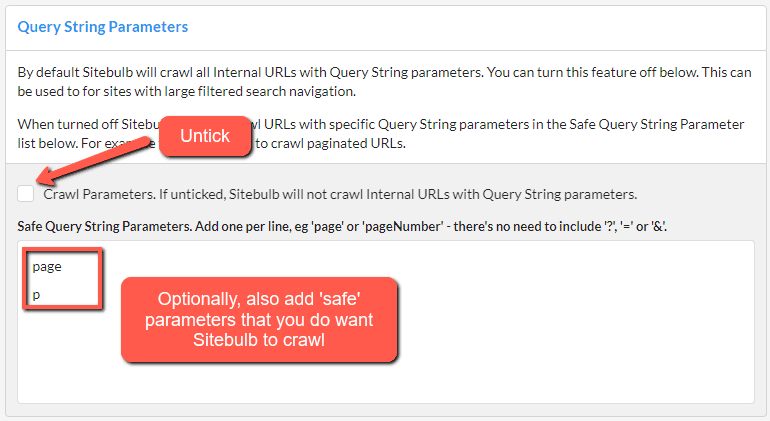
By default Sitebulb will crawl all internal URLs with query string parameters. However, on some sites you may wish to avoid this, such as on sites with a large, crawlable, faceted search system.
To stop Sitebulb crawling all URLs with (any) parameters at all, untick the 'Crawl Parameters' box. In the box below for 'Safe Query String Parameters', you can add in parameters which you do want Sitebulb to crawl, such as pagination parameters (e.g. 'page' or 'p').
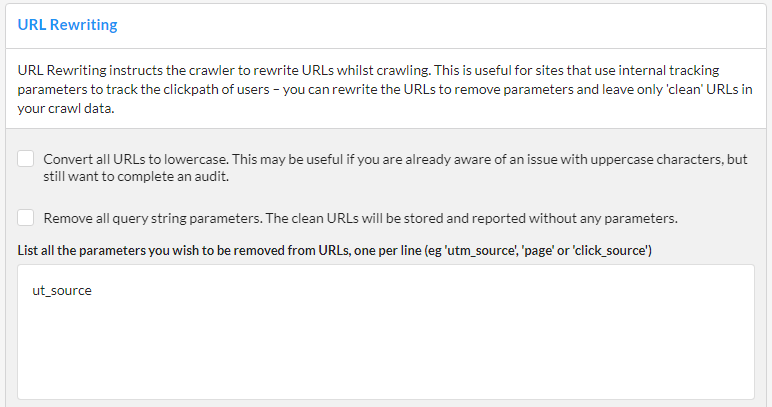
URL Rewriting is a method for instructing Sitebulb to modify URLs it discovers on the fly. It is most useful when you have a site that appends parameters to URLs in order to track things like the click path. Typically these URLs are canonicalized to the 'non-parameterized' version, which really just completely mess up your audit...unless you use URL rewriting.
You use URL Rewriting to strip parameters, so for example:
Can become:
And you end up with 'clean' URLs in your audit.
To set up the example above, you would enter the parameter 'ut_source' in the box in the middle of the page. If you also wish to add other parameters, add one per line.
Alternatively, the top tickboxes at the top allow you to automatically rewrite all upper case characters into lower case, or remove ALL parameters, respectively. The latter option means you do not need to bother writing parameters into the box, it will just strip everything.
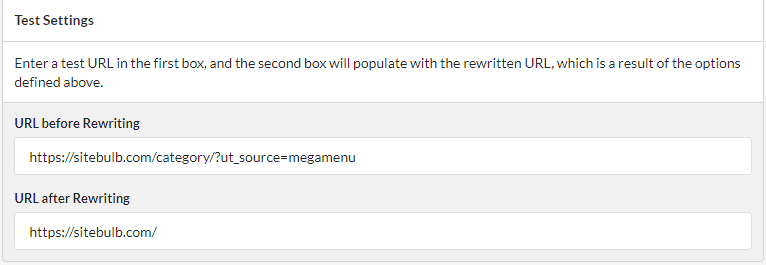
Then, you can test your settings at the bottom by entering example URLs.
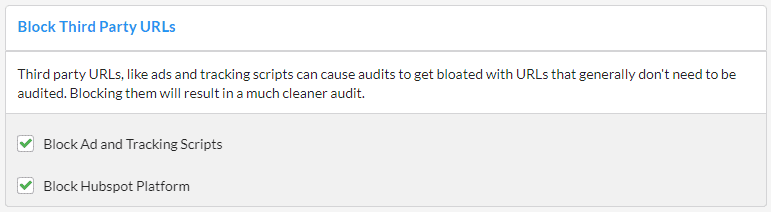
Third party URLs, like ads and tracking scripts can cause audits to get bloated with URLs that generally don't need to be audited. Blocking them will result in a much cleaner audit, so Sitebulb does this by default - untick this option to include them in your audit.
Hubspot platform in particular can spawn tons of tracking scripts, so again this is blocked by default.
There is an instance where you may wish to unblock tracking scripts in order to get better audit data, and this is when the website is set up to dynamically insert or change on-page data via Google Tag Manager (read about how to set this up here).