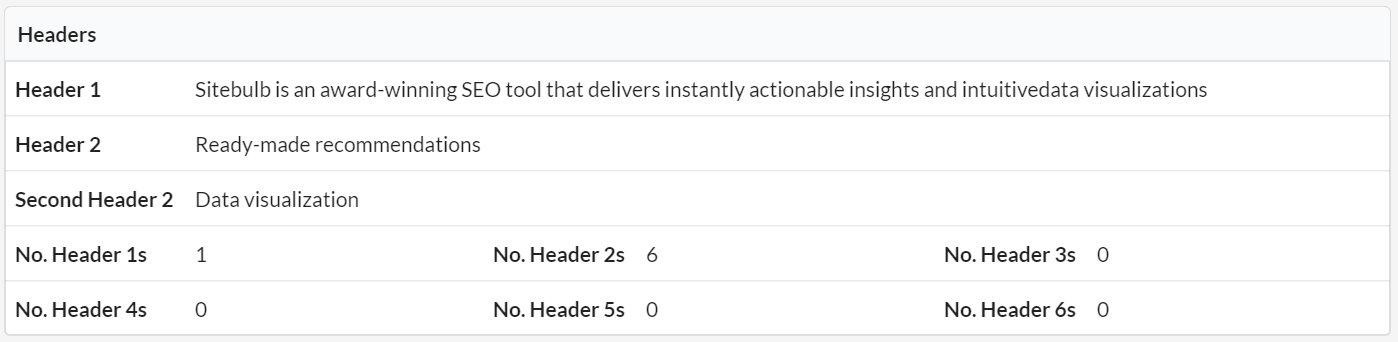
Sitebulb Version 3
Version 3 took up most of our 2019, and was very much a labour of love. Our main goal with this update was to answer the question a lot of users were having: 'which issue do I work on first?'.
Version 2 was developed mostly during 2018, following on from Version 1 and the beta years.
Version 3.7.1
Released on 8th July 2020
Nothing revolutionary here, this is basically just a bug fix update to tide you all over before we give you version 4.
If you want to find out what we've got in store, check out this podcast where I reveal our plans, otherwise you'll just have to wait to find out.
Wait for it, wait for it, wait for it, wait...
Updates
#1 Updated the redirects export
Redirect chains were causing botheration. Specifically redirect chains that lead to external broken (404) pages - Sitebulb was not making it easy to find the internal 'origin' URL.
We have dealt with this by implementing a number of small improvements:
- Added External and Resource redirects to the redirect chain export. This means that you can see the full redirect chain for broken external redirects.
- Fixed an issue that was causing duplication in the redirect chain export.
- Fixed an issue that stopped redirect chain csv exports from being regenerated.
#2 Improved link location analysis
When we released out Link Explorer earlier this year, we also improved our link data. We pushed the envelope with it, being the first crawler tool to automatically class links based on where they were found (footer/header/navigational/content).
Apparently, this wasn't quite working perfectly on some sites, and would sometimes mix up header/footer/navigational links; so we've improved the parser to make it more accurate and robust.
When you got skin in the game, you stay in the game.
Fixes
- On URL Lists, the metric UR (URL Rank) was listed as a column to 'Add/Remove', yet nothing happened when you tried to remove it.
- In the URL Explorer, the list for Security > HTTP URLs was wired up incorrectly, and therefore showing 0 results.
- If you switched dark/light mode, the UI will change in the background, but on the site visualisation map it didn't change. It now does.
- The Mixed Content export was for some reason putting all the data on one row, instead of separate columns.
Version 3.7
Released on 15th June 2020
Updates
#1 Updated Chromium Crawler
As per our commitment to maintaining our Chrome Crawler to be evergreen, like the Googlebot crawler, we have updated it to use the latest stable version of Chromium, version 83.
His full name is version 83.0.4103.0, but only his mother calls him that (when he's being a naughty little shit).
Fixes
#1 Sitebulb unable to properly crawl some websites
Rather vague, I know. The more specific version is: "there was a typo in the code that causes an error in pages that have picture elements with certain types of child elements."
Not a great deal clearer.
Let's just go with 'there was a typo.'
#2 SVG title tags trigger the Hint 'URLs with More than One Page Title
SVGs have proven to be a pain in the collective arse of everyone at Sitebulb recently. Firstly, they were causing the parser to shit a brick, so we stripped them out of the DOM, but then this meant some URLs would not crawl AT ALL, so we stopped stripping them, and then because we put them back in, it triggered Hints like this one for multiple title tags.
What a ballache (look it up).
This time we've gone back to stripping the SVGs from the DOM, but we're doing it a different way that does not systematically break a whole bunch of other things. We hope.
#3 Sitebulb misreporting compression
When we changed over to the new (much faster) HTML Bot in version 3.6.3, it seems the library stopped reporting content-encoding in the HTTP header. Which means that Sitebulb would report pages as uncompressed when they actually were. How very annoying.
Version 3.6.4
Released on 4th June 2020
Unfortunately, Patrick is not available today to write the release notes, so you are stuck with me and my ramblings. I am not as funny, nor as rude!
This is a reasonably critical update for some users. If you are v3.6.3 our advice is, you upgrade to this version as soon as you can. Now please!!!
Updates
#1 On some sites and servers the HTTP Response headers were not being stored.
This data is pretty important information for a lot of the hints and report data. This is the critical update.
#2 Fixed Images missing alt text exports and URL lists
Yet again, we managed to introduce a bug into the "images missing alt text" hint that means this data is not being collected. We were reporting it, but the bug stopped you from accessing the data in the UI and via the export.
Boring, hey! I promise Patrick will be back.
Version 3.6.3
Released on 27th May 2020
When the shit first hit the fan with this fucking pandemic we were all over the shop. We'd sleepwalk through each day, getting next to no work done, constantly refreshing the news and watching the graphs go up and up and up, wallowing in wrappers of Snickers and empty packets of salt and vinegar Pringles.
So. Very. Depressing.
These days the world is not really a great deal brighter, but at least we've managed to pull up our socks and get down to business.
And you know when I'm down to just my socks what time it is...
Updates
#1 Added scheduled and recurring audits (finally!)
On our feature upvote site, Scheduled Audits was first requested way back in October 2017. All it took was for the entire world to shut down before we got motivated enough to build it (in our defence, according to Gareth it was 'really tricky').
But build it we have, and now all Pro subscribers can download the new version and get scheduling right away. It's business time baby.
We have a full documentation guide on how the feature works, so I'll just provide the highlights here:
- You can schedule an audit to run at any time
- You can set recurring audits to run at specific intervals
- You can allow Sitebulb to run in the background and run scheduled audits when it needs to
But how?!?!
When setting up a new audit, once you have finished customising the other elements, you should notice an option at the bottom entitled Scheduling (optional).
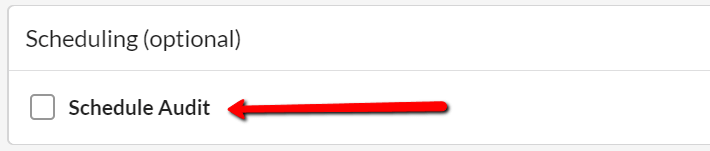
If you tick the Schedule Audit box, it will open up the Scheduling panel and options:
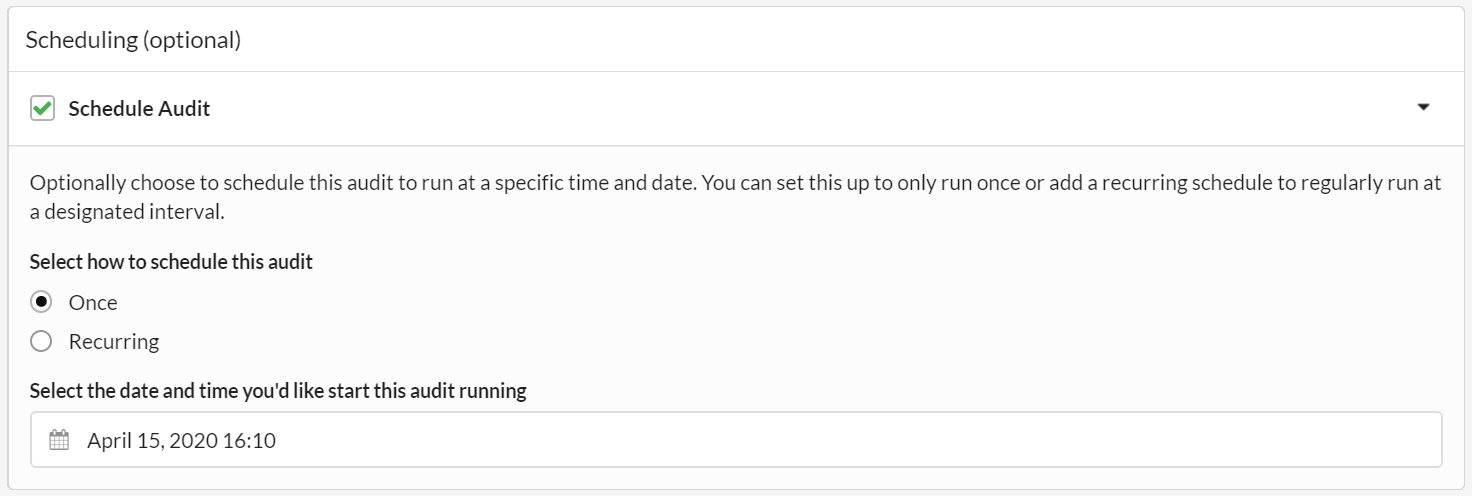
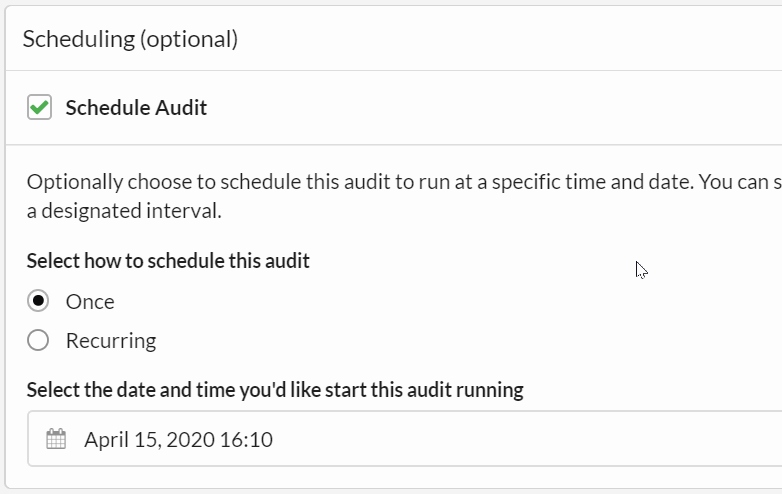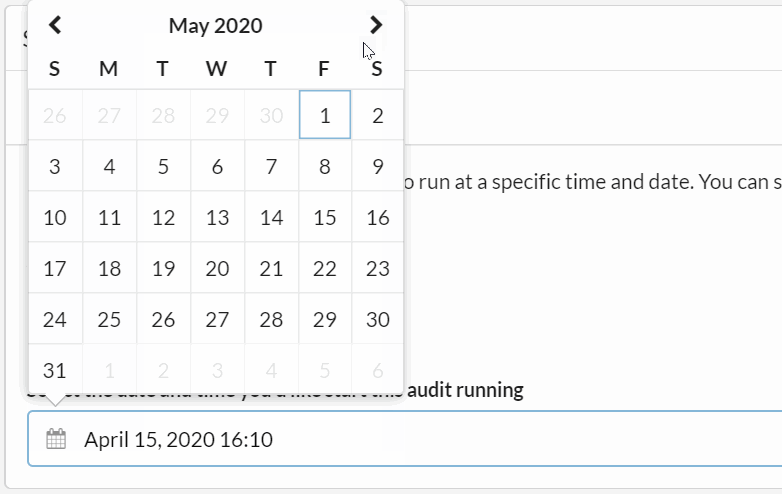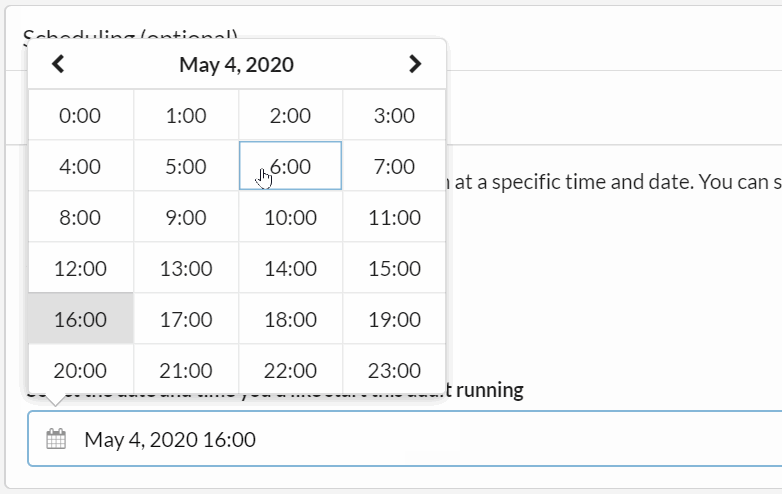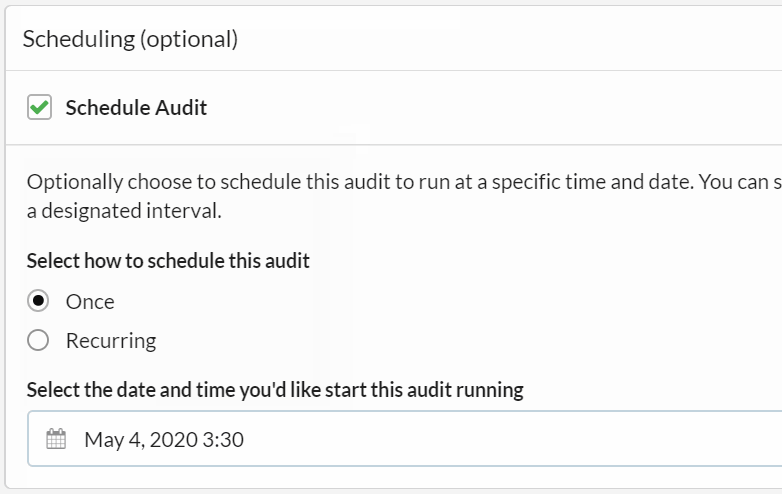
By default, the 'Once' radio button is selected, which essentially means you are setting up a scheduled audit to run only once, but not regularly recur.
All that is left to do is select a date and time, which can be specified to a 5 minute interval:
You can also set up recurring audits. A recurring audit is effectively a special case of a scheduled audit, so the initial steps as above are all the same.
To set up a recurring audit, this time you need to select the Recurring radio button, which will also open up a set of new options underneath.
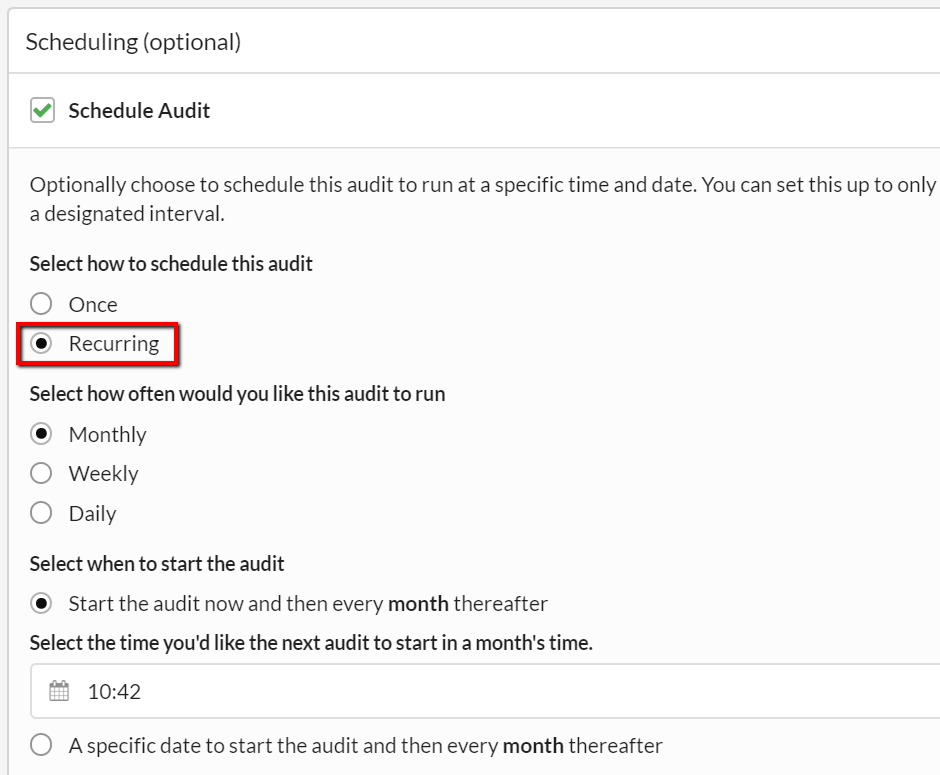
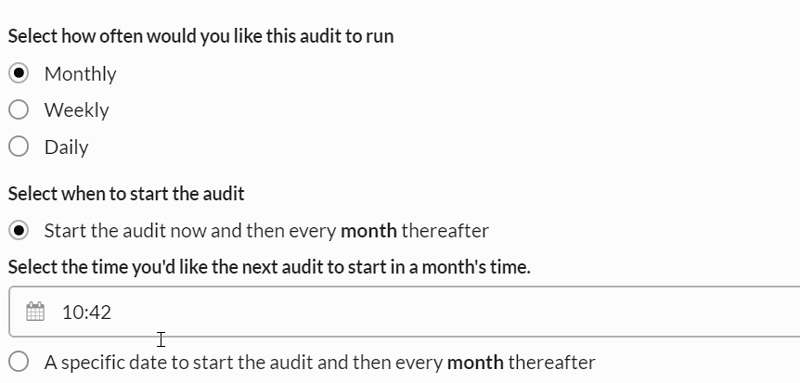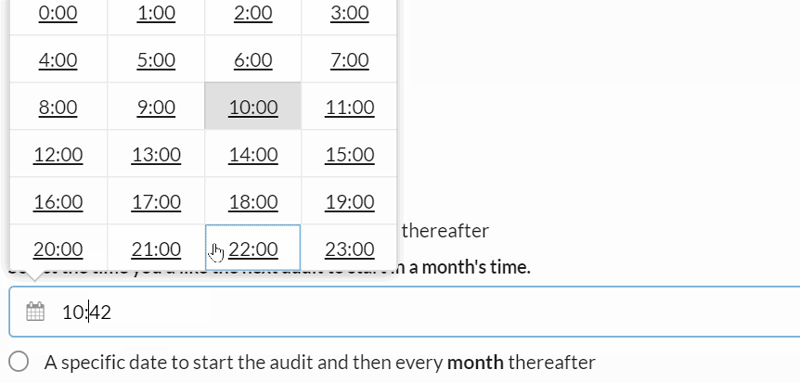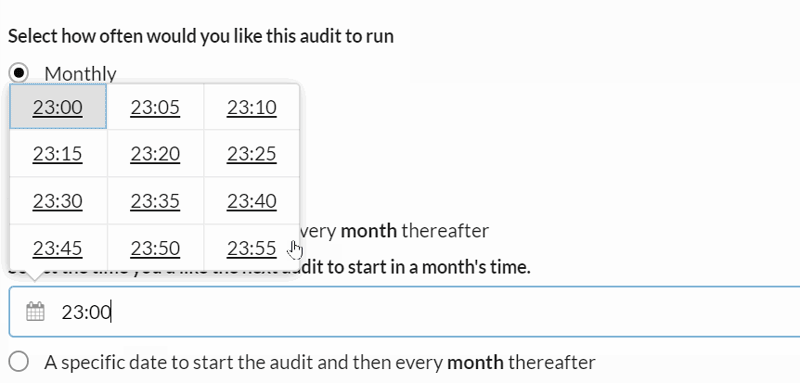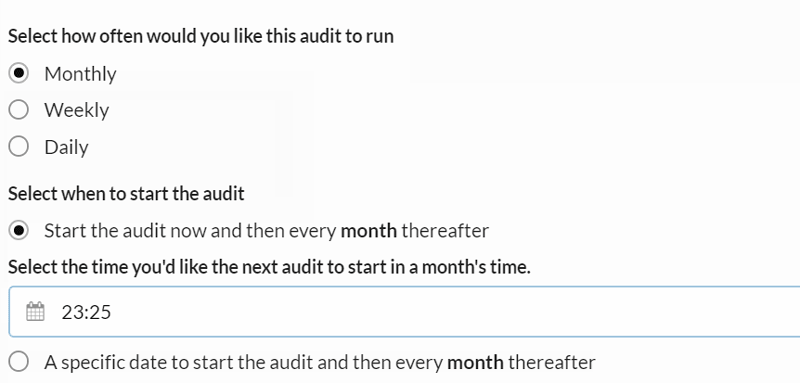
You can also choose whether to start the first audit now, or pick a specific time to schedule the first audit, before reverting to the recurring schedule.
It is worth bearing in mind that the default behaviour of scheduled audits works on the basis of two core assumptions:
- That your computer is actually on, when scheduled audits need to run
- That Sitebulb is actually running on your computer, when scheduled audits need to run
If both of these assumptions are met, Sitebulb will handle scheduled audits just fine. If either of them is not, then it is not possible for Sitebulb to carry out the scheduled audit. Why?! Because the program is not fucking running!
However, Sitebulb has a number of in-built settings that help mitigate these issues, which are accessible via this link on the Scheduled Audits page:
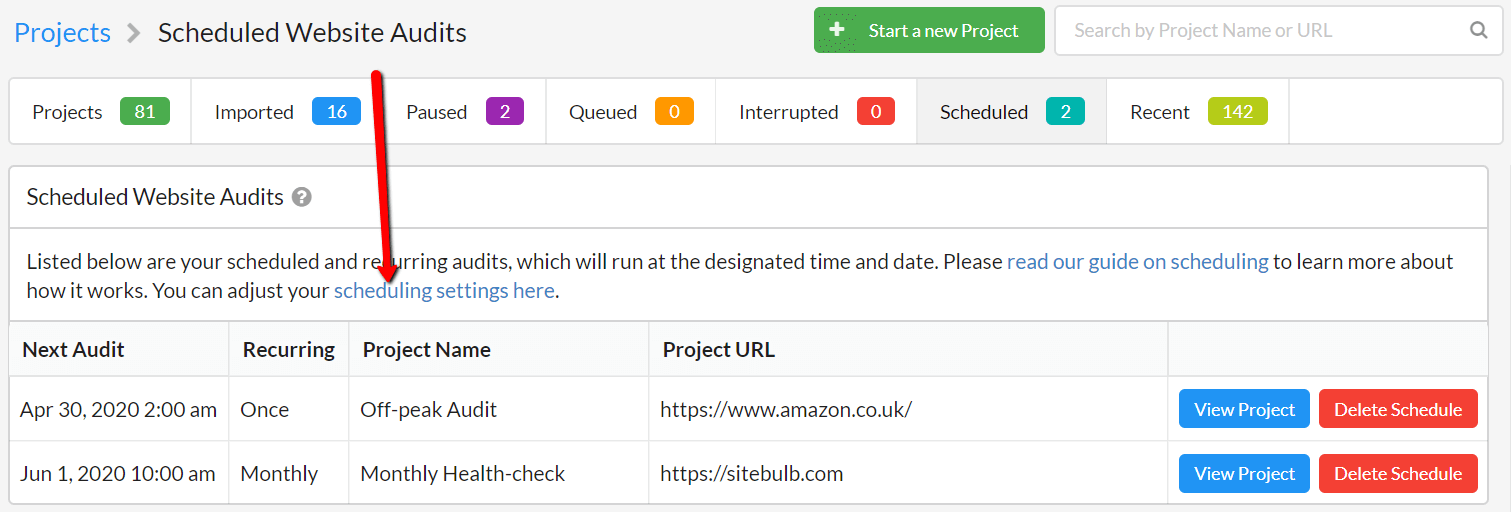
This will bring you to a settings page with specific scheduling settings:
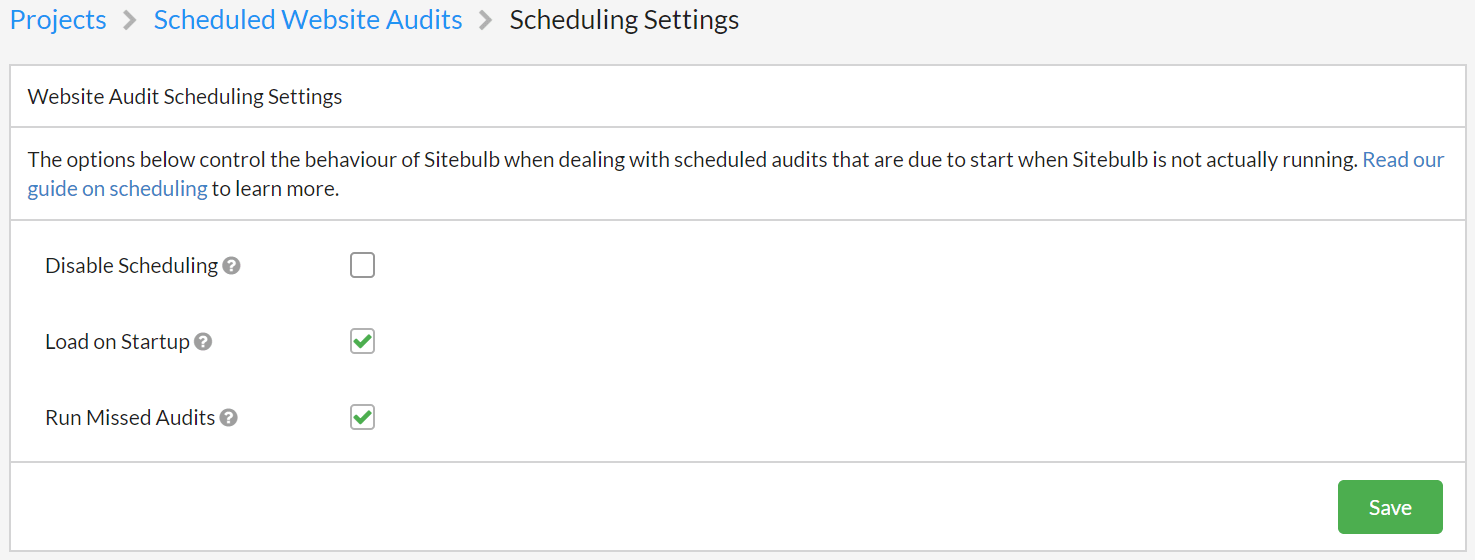
These tickboxes offer the following options:
- Disable scheduling - stop Sitebulb running any scheduled audits at any time, while this box is ticked.
- Load on Startup - enable Sitebulb to load up when you start up your machine, and run silently in the background.
- Run missed audits - if Sitebulb has not been running for a period of time, and has missed some scheduled audits, force Sitebulb to queue up and run these audits the next time it is running.
These options come with a degree of nuance, so you may wish to read our guide for a more complete explanation of why they exist and how you might wish to use them.
You turn to me and say something sexy like, "Is that it?"
Actually it's not...
#2 Custom save location for export files
We told our friend and trusted confidante Martin McDonald about the new scheduling feature, expecting perhaps a response like 'oh my god this is great' or perhaps even 'you guys rock, especially you Patrick'.
Alas, not.

I tell you something, if I wasn't practising social distancing... (and there wasn't 5,000 miles holding me back).
In the end, we decided to be the bigger men and choose the adult response, swore under our breath at him, and built the automatic exporter as well.
You'll find the new setting in Advanced Settings, and it enables you to build a more automated workflow where Sitebulb can run audits and then automatically save the export files in a location of your choosing - either on your local machine or in a shared cloud drive that your whole team can access.
You simply pick a location for the exports and/or the audit share file, and then at the end of the audit Sitebulb will save the data there for you.
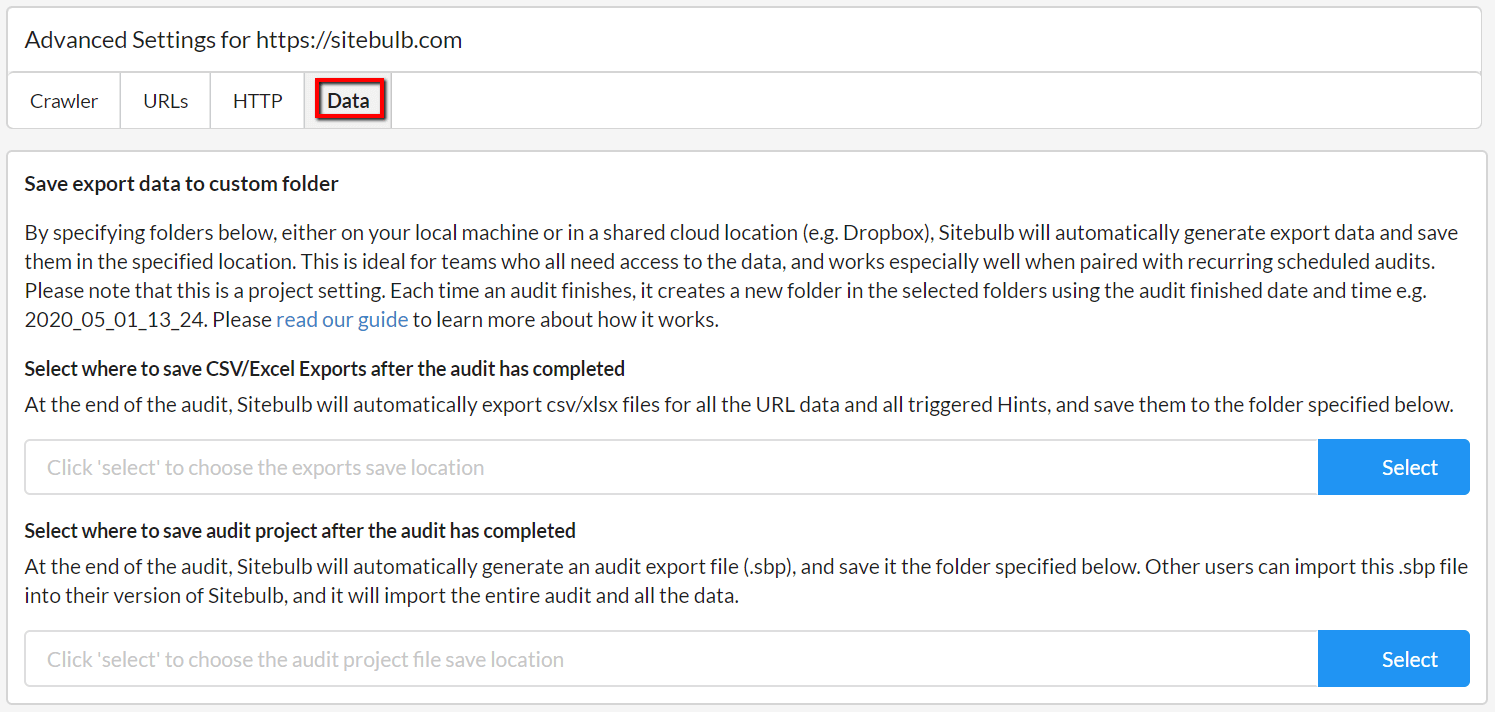
While the custom save location works for any audit, it is most powerful when you use it alongside a recurring or scheduled audit.
The features combine to allow you to set up fully automated workflows, such as:
- Set up a project to run weekly recurring audits on a website
- Set up export files to save to a shared folder on Dropbox
- Give other team members access to the shared folder
Every week, new export files will appear in the shared folder, allowing team mates to grab the new files and build their reports with all the fresh data.
#3 Made the crawler significantly faster (for those that need it faster)
Another update inspired by Martin McDonald complaining incessantly, we have now made Sitebulb POTENTIALLY crawl 30-40% faster.
The reason I wrote 'potentially' all massive and that is because most users won't actually notice the speed difference. This is because Sitebulb is built to be deliberately responsible, and to make Sitebulb crawl faster, you'll need to over-ride the default speed settings in the advanced settings (if you don't know how to do this, check out this guide).
For those, like Martin, that do want to smash the lights out of their client websites (and have the necessary permissions to do so), Sitebulb will now willingly oblige...
#4 Improved handling of staging sites
Up until now, Sitebulb has not done an amazing job of letting you audit staging/dev sites, for instance, in preparation for a site migration. Although Sitebulb supports both HTTP authentication and forms-based authentication, some sites employ other indexing-avoidance methods, such as:
- Adding a 'disallow all' rule to robots.txt
- Adding meta noindex to every single page
- Adding meta nofollow to every single page
These sort of things have annoying side effects when you carry out an audit in Sitebulb, such as 'Sitebulb can't crawl any of the pages' or 'Sitebulb thinks all your pages are not indexable' or 'Sitebulb refuses to save any links because they are all nofollow.'
Now we all know that when the site is launched, this stuff will be removed (note to all devs: 'REMEMBER TO REMOVE THE FUCKING DISALLOW ALL'), but this doesn't really help when you want to actually audit the site.
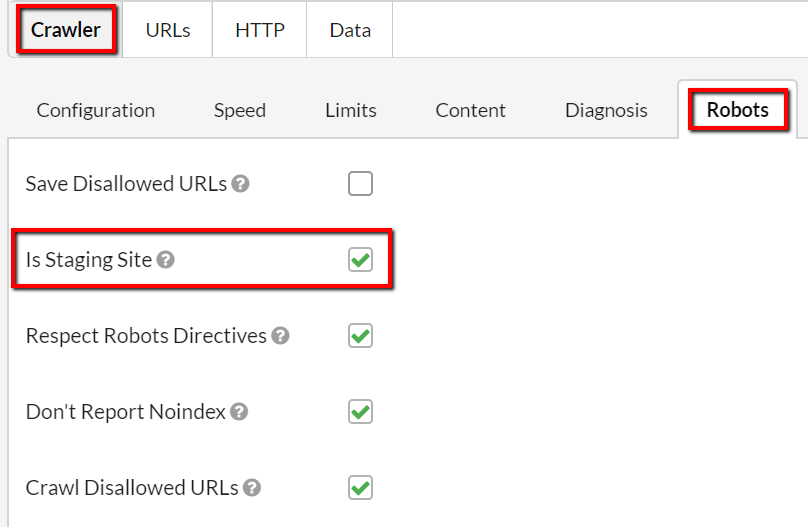
So, we've added some 'Staging Site' options which basically allow Sitebulb to pretend that these anti-indexing measures are not there at all. If it is a pretty obvious pattern (e.g. 'Disallow all'), Sitebulb will show you a big red box on the pre-audit:
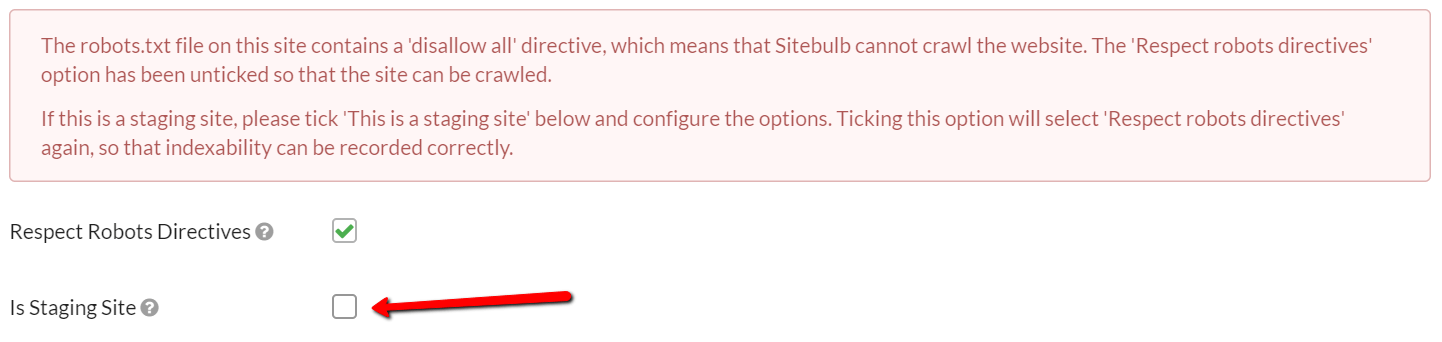
By ticking the box 'Is Staging Site' you will open up a bundle of different configuration options that allow you to crawl the site differently:
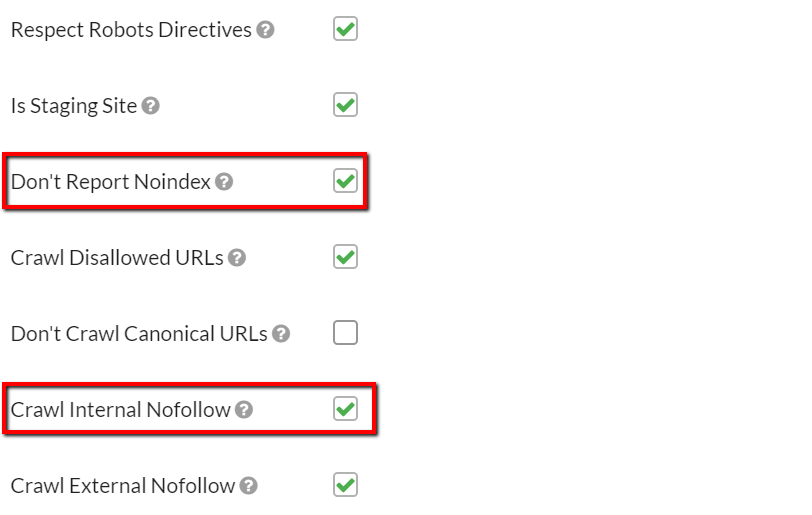
The two most useful I think are:
- Don't Report Noindex - if Sitebulb sees 'noindex' on any URL, it records it as 'index' instead
- Crawl Internal Nofollow - if Sitebulb sees 'nofollow' on any URL, it records it as 'follow' instead (and then follows all the links on the page)
Now, it is important to note that these options are fundamentally different from the classic 'don't respect robots' option you get in most crawling tools. Sitebulb will literally change what it records in the reports.
This then allows it to accurately report on internal links, indexability and duplicate content (which only analyses indexable URLs in the first place).
Baked into this is some inherent danger, however. Some sites may deliberately employ 'noindex' or 'nofollow' directives on some specific pages (i.e. not sitewide in an anti-indexing effort), and if you tick the boxes above, Sitebulb will also convert these to be index/follow, as it can't tell the difference between the directives or their overall intention. In these cases we'd recommend locking the site down using authentication (username/password login) so you don't need to bother with the staging site settings at all.
Finally, there are some websites for which it is not obvious that they might be staging, and so Sitebulb can't 'guess' and give you a massive red warning on the pre-audit. For these cases, you can go and select the Staging Site options from Advanced Settings:
#5 Allow MUCH bigger uploads to Google Sheets
Back in February for v3.3 we added our Google Sheets integration, and back then we told you the maximum row limit was 192,000 rows, as this was all the API allowed us to do. One of our magnificent customers told us how to work around this limit, and so we have added this flexibility into this update as well.
- Sheets still has a hard cell limit of 5,000,000 cells, that bit has not changed.
- We can now reduce the number of columns on the sheet, allowing more rows to be included.
- You can control this yourself by doing 'Add/Remove columns' in the URL List to reduce the number of columns pushed into Sheets (and therefore increasing the potential maximum columns).
- Alternatively, Sitebulb will offer you a '1 column' option where we just push the URL column itself, allowing all 5million rows to be used.
In most cases, you won't even need to make a choice about this as you won't be getting near the limits. If you are, Sitebulb will warn you and offer you some options:

Fixes
- Fixed the export option on URL Lists to 'Export Incoming Links' so that all the incoming links are included in the export.
- Forms authentication was not working on Shopify sites when using the Chrome Crawler, so we have improved the handling of forms authentication cookies.
- Non-encoded canonical for encoded URL was being reported as different URL. U wot m8?? Let's just leave it as 'there was an encoding issue with canonicals' that affects 0.000001% of all sites. Just pretend I didn't say anything.
- There was a stupid scrolling error in Hints lists that meant you couldn't scroll to see all the Hints when you applied a filter (e.g. 'Medium').
- Anchor text was not being displayed on the Single Page Analyser tool.
- Adding and removing columns was not always updating, in some exports. You could add columns on a URL List, and they would appear in the export. Great. But when you then went in and deleted all the columns apart from a couple, all the deleted ones were still being exported out even though they were not visible inside Sitebulb. Muchos annoying.
- If you're in "Add/Remove Columns" and accidentally remove a column, you can click "Cancel" to avoid removing that column. However, if you re-opened "Add/Remove Columns" to make another change, the column you accidentally removed would still be removed. We fixed the cancel function so it actually works properly now.
- Sitebulb was incorrectly reading HTTP headers on PDF files, and reporting them wrong.
- Some external hreflang missing was from reports, which meant that some international Hints were incorrectly firing.
Version 3.5.2
Released on 27th March 2020
Version jump alert. This happened because the devs created v3.5.1 as a hotfix while I was busy homeschooling, and since they are developers they are incapable of stringing a sentence together, so they just did not bother to even release it.
Updates
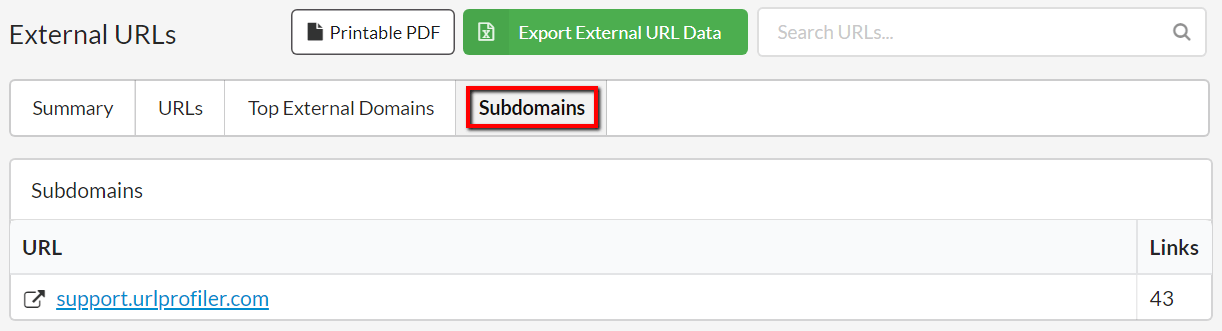
#1 Added subdomains tab into 'External'
Sitebulb treats subdomain URLs as external URLs, but up to this point we did not make it very easy to separate out subdomain URLs. So we added a new tab into the External report which does this for you. Simply click the subdomain link for a URL List of all the URLs for each subdomain.
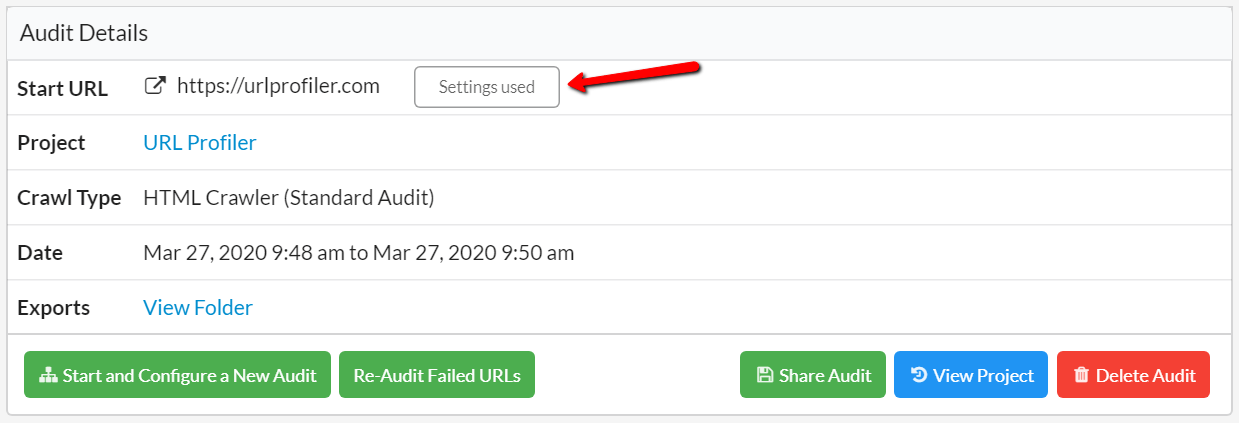
#2 Clearer settings button
Too often, customers would come up to me in the street and ask me 'but what settings did I use on this audit?'. Frankly, I have better things to talk about*, so we made a easy to spot button on the Audit Overview:
*This is actually not true. The only thing anyone ever talks about anymore is the bastard coronavirus. I'd rather talk about settings.
#3 Changed the default sort order to descending
In URL Lists, whenever you clicked the column heading to 'sort', it would sort the wrong way. I know there is really no right or wrong way to sort, but it always seemed wrong. So we swapped it.
Fixes
- If you viewed incoming/outgoing links in the URL Details page, it would claim that no anchor text was used for any of the links. This was a bug, y'all aren't actually THAT bad at SEO.
- if you had a dev site that used forms authentication, you were sometimes unable to add authentication, as there was a security restriction in Sitebulb which stopped in-site password modals from opening (which meant you could not login). Fixed.
- Sitebulb was not crawling any links when the URL rewriter (an advanced setting, if you know, you know) was being used in any way shape or form. Not quite the intended behaviour.
Version 3.5
Released on 20th March 2020
Given the current state of the world, we thought it appropriate that this update should be focused mostly on BUG fixes. If you're expecting these notes to either (a) Avoid the topic or (b) Attempt to be serious and sombre... you might want to close your eyes or look in the other direction.
Updates
#1 Introduced a new metric: URL Rank
As you all know, I never like to criticize our customers (it's just not my style), even when their first reaction after being given a new feature is to ask for more.
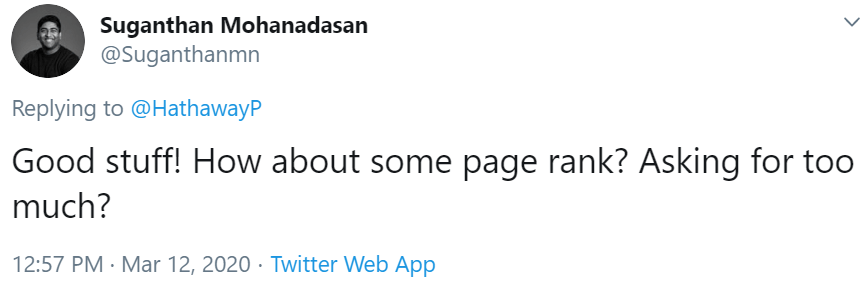
Of course, in my Twitter response I ignored the needy and selfish undertones, and simply demonstrated where you could find this data in the tool, for we already had it.
However, Suganthan's self-indulgence did spark something in us to examine more closely the data we were providing. Sitebulb was calculating a 'Link Equity Score', which was based on the original PageRank algorithm. This was a measure of page strength based on internal links.
However, when we looked at it further, we noticed that it was a really shitty metric for identifying good/medium/bad pages on the site. Lots of sites ended up like this:
A handful of strong pages, barely any 'medium' pages, and tons of weak pages. This was not useful at all for finding strong or weak pages.
So, we threw it in the bin and figured out a new metric: URL Rank (UR). This is a URL-level metric based on internal links, and works like other similar links based metrics; rewarding pages with lots of incoming links, and not those with few.
We made a few changes off the back of this update:
- Made UR (URL Rank) a much more prominent column in URL Explorer/URL Lists.
- Included UR in the new Link Explorer, for both target and referring URLs.
- Adapated the table on the Links report for UR.
Here it is in action:
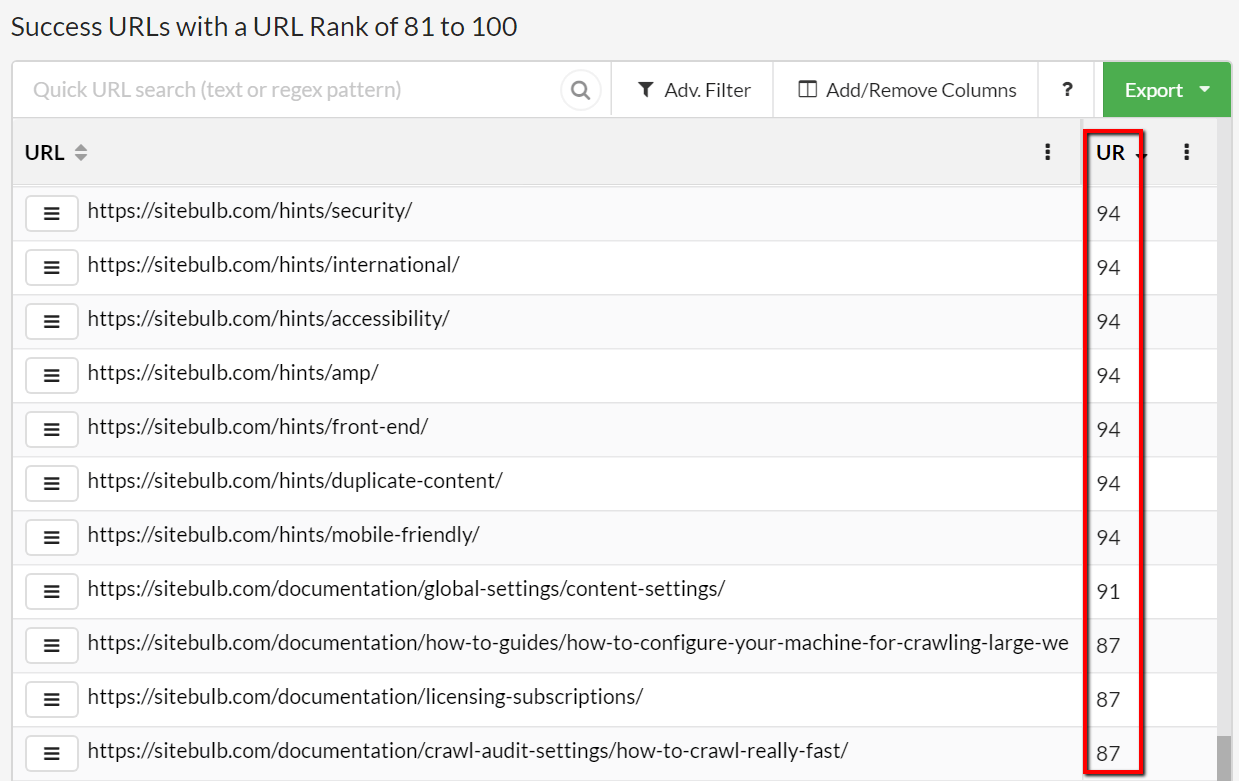
I have written a guide on what URL Rank is and how to use it to identify strong pages.
#2 Little improvements to the Link Explorer
The links view is now hooked directly through to the anchor text view, so clicking on an underlined phrase in the Anchor Text column will filter on the anchor text. The next bit is even cooler though, click on the anchor text itself and you'll see all anchor text variations of that phrase.
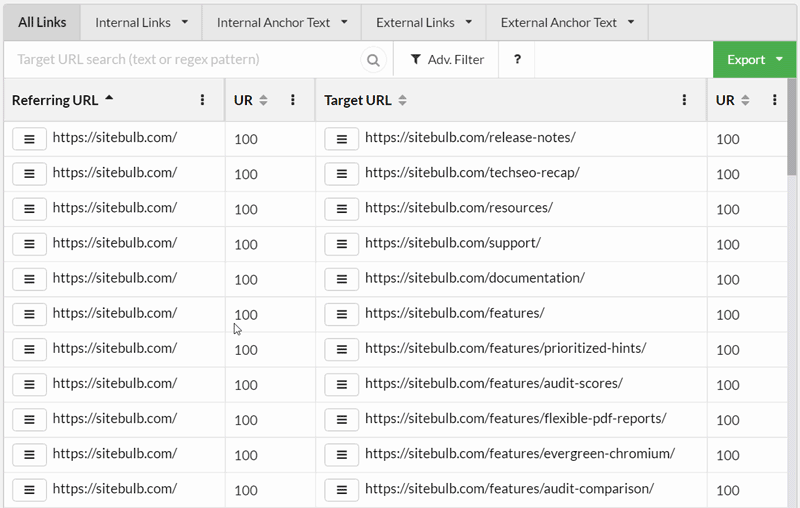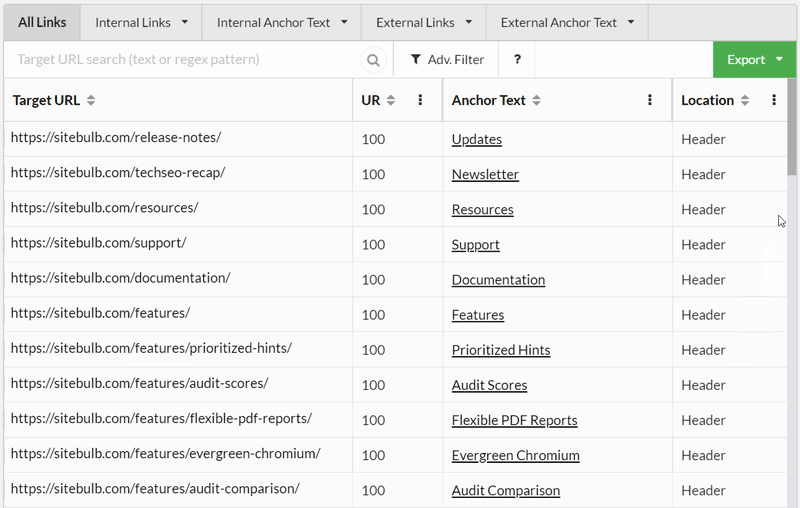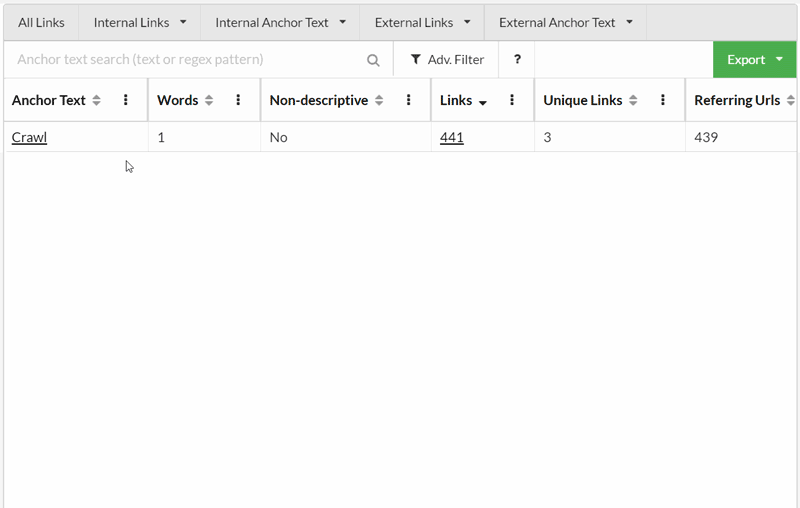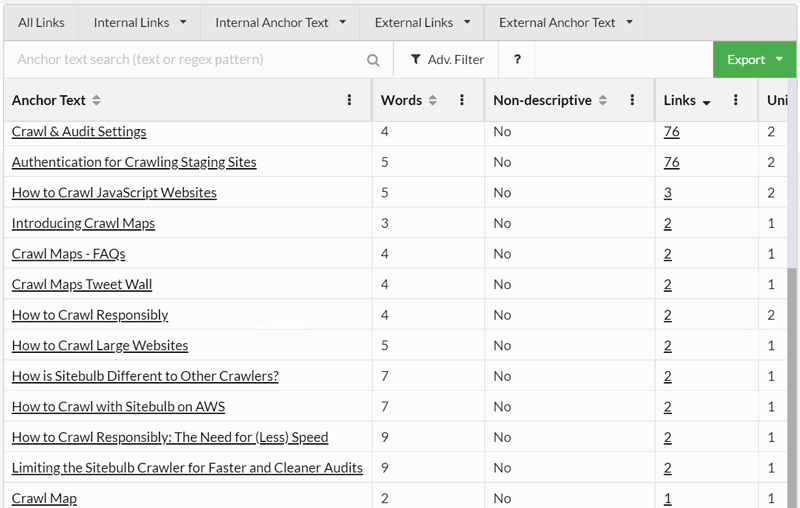
In case the gif is a bit hard to follow, in this wee demo I clicked on the 'Crawl' anchor text which brought up the Anchor Text table, and then clicked 'Crawl' again to see all the variations of anchor text that include the word 'crawl', ordered by number of links:
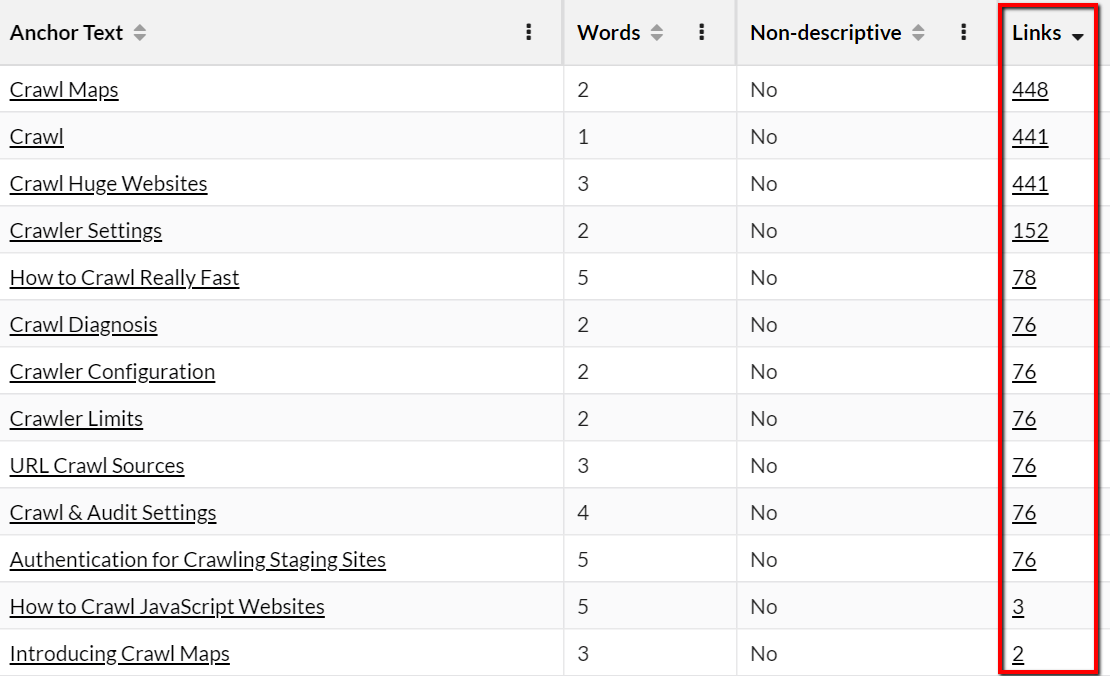
Using this methodology you can investigate how anchor text is used across the site, and use it to help identify keyword cannibalisation situations or over/under optimized pages.
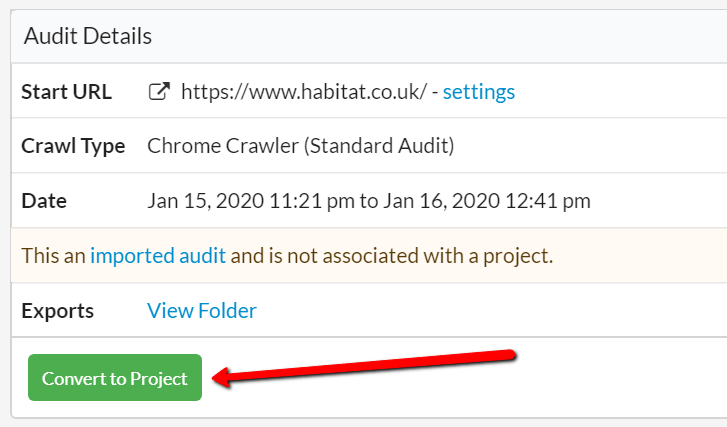
#3 Convert an imported audit into a Project
This one has been a long time coming, you can now take an imported audit and magically convert it to become a proper Project - which means it will live in the 'Projects' list, and will forevermore be treated like a Project.
Fixes
#1 Mixed Content export was empty
I was chastised by Gareth for adding this ticket. 'This is already fixed!' he said. 'It wasn't when I added it', I replied, indignant. A lesser human would have spent the next 20 minutes scanning through emails and hunting through old audits to find conclusive evidence I was in the right. But not me. I only spent 10 minutes.
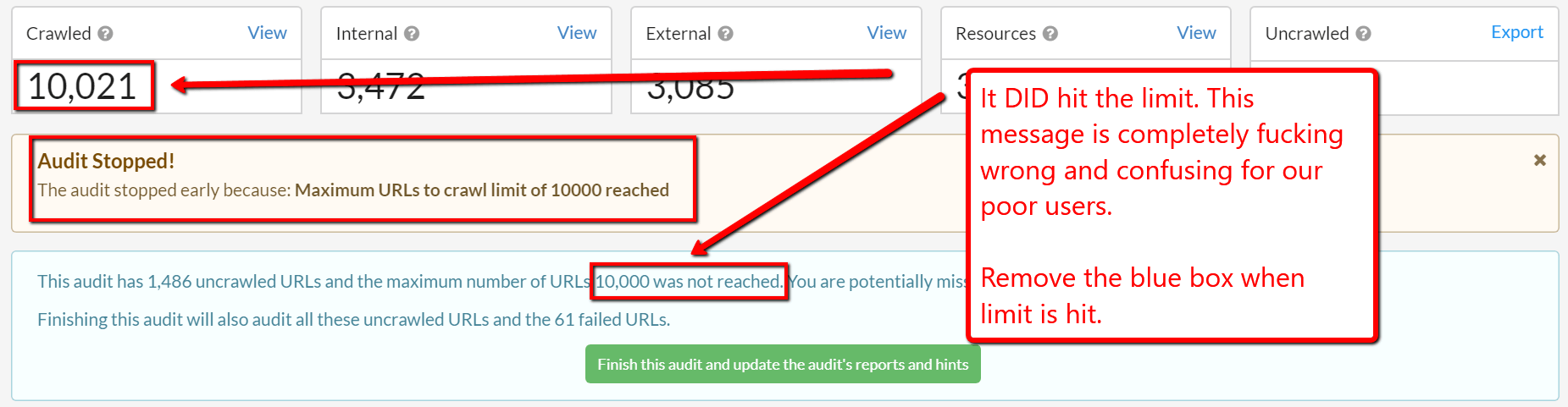
#2 'Finish this audit' message box was showing incorrectly
To clarify, it was showing on audits which had hit a pre-set crawl limit. It should not have been showing then.
Luckily for our users, I spotted it and added it as a bug to fix. Pro tip for any Product Managers out there: 'use clear images with tactful messaging'.
#3 Reset the message to "While you wait, guess the movie..." when the print PDF modal is opened
Every so often, Gareth relents to one of my whimsical ideas, and, with more than a pinch of scepticism, implements things like the 'Guess the movie quotes' when you print PDF reports:

The thing is, when he added it, there was a flaw. If you went to 'Print PDF' more than once, the second time (and all subsequent times) the message "and it's done" was displayed before "While you wait, guess the movie...".
This annoyed the fuck out of me for years, yet I did not bring it up as I did not want to push it with Gareth, who saw the whole thing as superfluous gobshite.
Enter James, another developer who has started working alongside Gareth on some of our stuff. He noticed it as well, and just went ahead and fixed it! James, you magnificent bastard.
And by the way, yes I do know the quotes are so difficult that no one has managed to guess them all yet*.
*Yes this is a challenge, come at me** on Twitter
**Don't be that dickhead that just Googles them
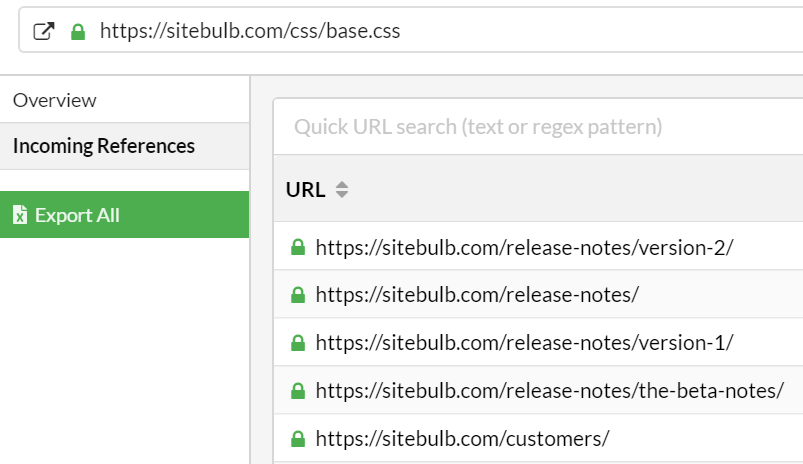
#4 For page resource URLs, replaced 'incoming links' with 'incoming references'
When you click the 'View URL Details' for any page resource URL (e.g. a CSS file), there would be a tab for 'Incoming Links.' Since incoming links for page resource URLs was always precisely zero, this screen was absolutely useless. We replaced it with 'Incoming References' instead.
#5 Removed stupid rule from robots.txt interpreter
Every so often we find a bug that is so embarrassingly stupid, that Gareth coyly suggests we maybe just don't mention it in the release notes. And to that I say: no chance! What is this Trumpian dystopia where we cannot admit our mistakes and be at peace with being imperfect? Yeah let's just blame it on the Chinese instead. Fuck. Right. Off.
We're fighting our own fight one robots.txt mistake at a time.
This one happened to be changing this */- to this /*-
Which, well yeah, really is quite an embarrassing mistake. But at least we learnt from it!
#6 Crawl Paths were blank
Another stupid embarrassing bug, Crawl Paths were not recording any data, sparking worldwide panic and confusion the likes of which not seen since... oh.
#7 Issue with Hint: 'Internal HTTP URLs'
This was seemingly mis-reporting, saying Sitebulb had found more HTTP URLs than there actually was. The Hint and the count in Hint statistics didn't match - the Hint was requiring the content type to be HTML, but the count in the statistics didn't. We've corrected this so that the count is also now only for HTML.
Version 3.4
Released on 12th March 2020. Please note that all the new stuff below will only be available in audits run on v3.4 or later.
Updates
#1 Brand new addition - Link Explorer
It feels like we've been battling with the issue of 'what to do about links' since we first launched the tool.
As we see it, there's basically 2 things that people want to do with links:
- Find links that point to stuff that's broken.
- Explore link relationships to seek optimisation opportunities.
The existing solutions for these problems (both in Sitebulb and in other tools) generally revolve around the notion of 'build a massive CSV and dump it into Excel, then figure the rest out yourself.'
This has always seemed inadequate, and we finally figured out a way to do something about it, with our brand new Link Explorer:
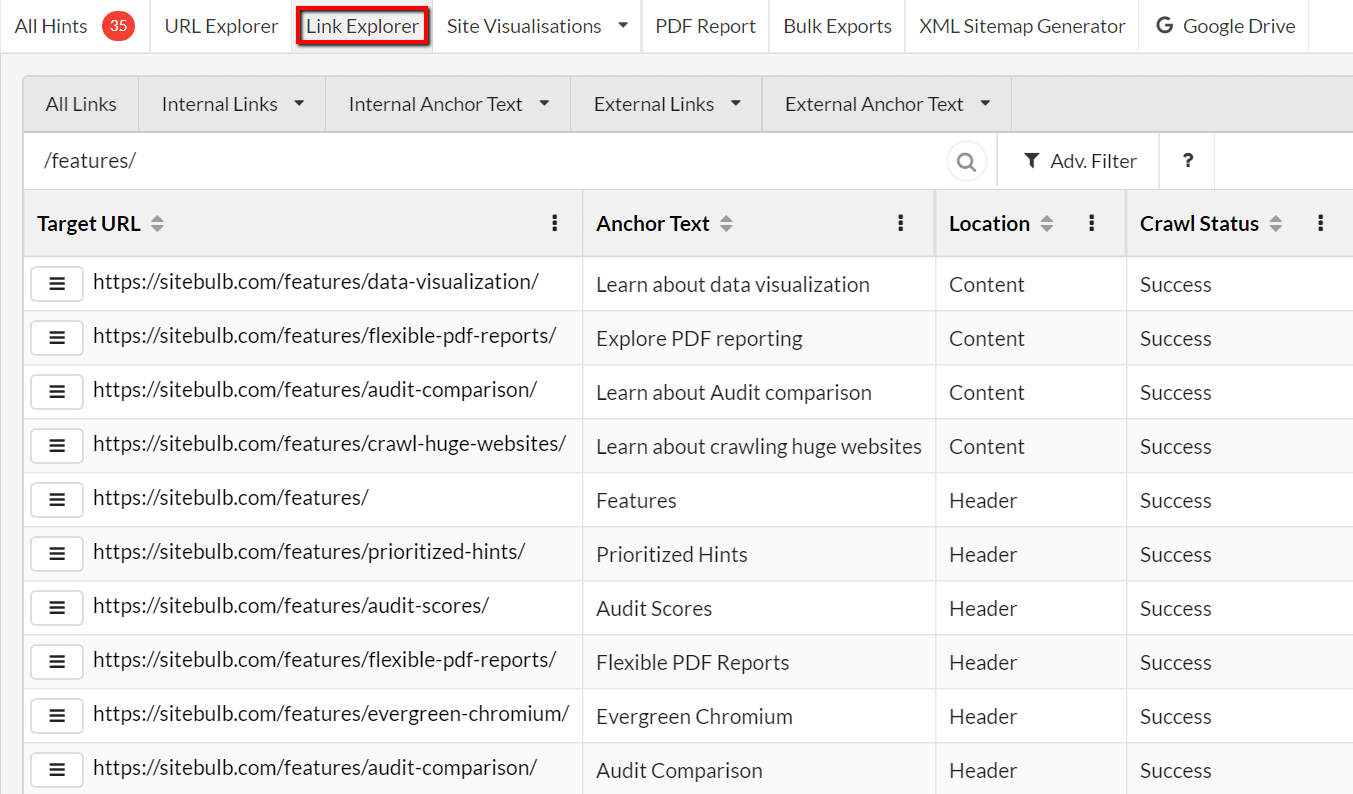
Some quick highlights of what this baby will let you do:
- Show you every single link relationship, even when there are millions of links (where the Excel method becomes as effective as a Mourinho team talk).
- Quickly filter on target URL, to explore the links to specific pages or groups of pages.
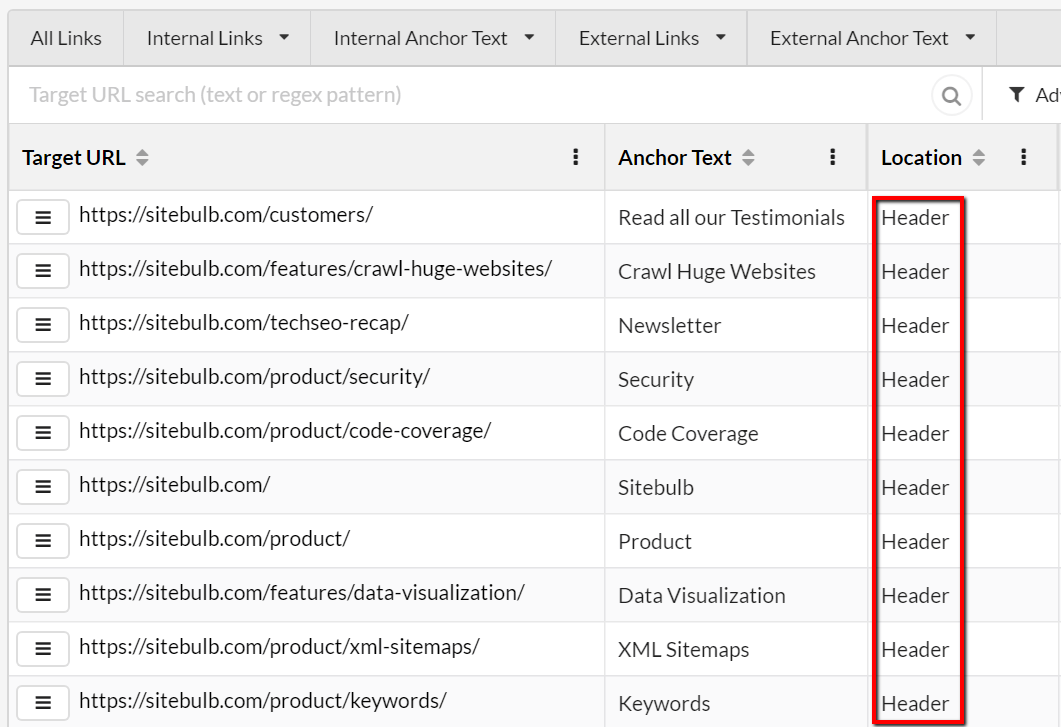
- Build very specific and customised lists using the Advanced Filter, filtering any combination of: Crawl Status, Target URL, Anchor Text, Referring URL, Link Location, Attributes (nofollow/sponsored/ugc), Internal/External.
- Explore anchor text variations and then cross-link this back into the link data.
- Export everything into CSV (if you really really do still want to use Excel) or Google Sheets.
It is incredibly powerful, and allows you to explore link data in a way that has not been possible before.
As a quick gif-based demo, here is how you can explore anchor text:
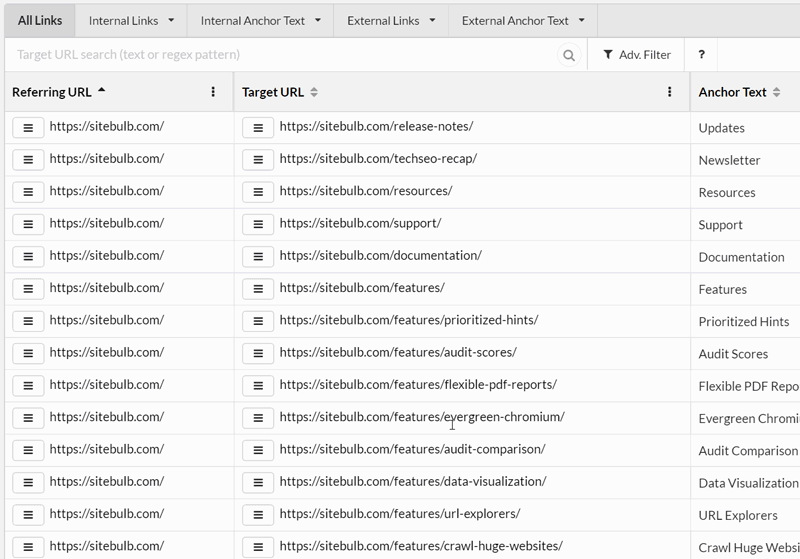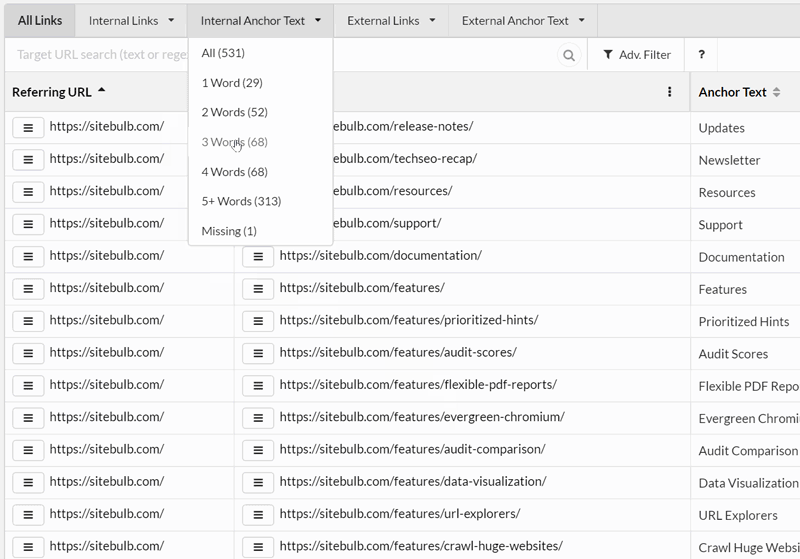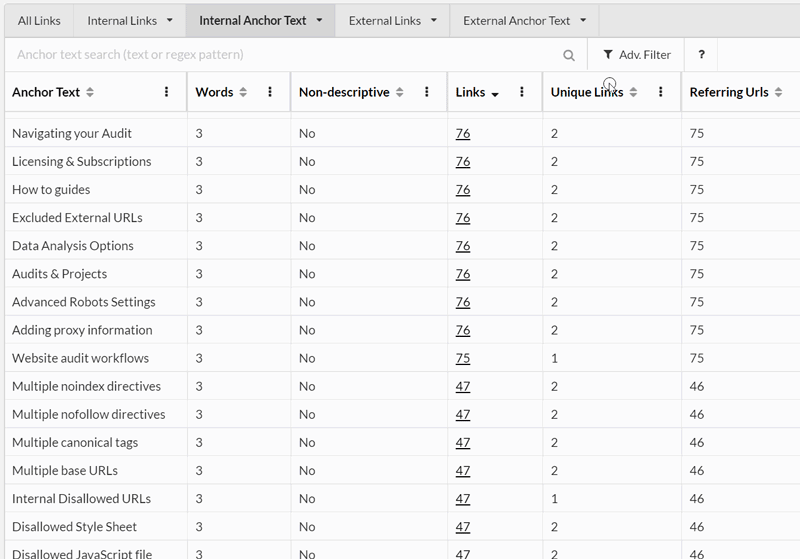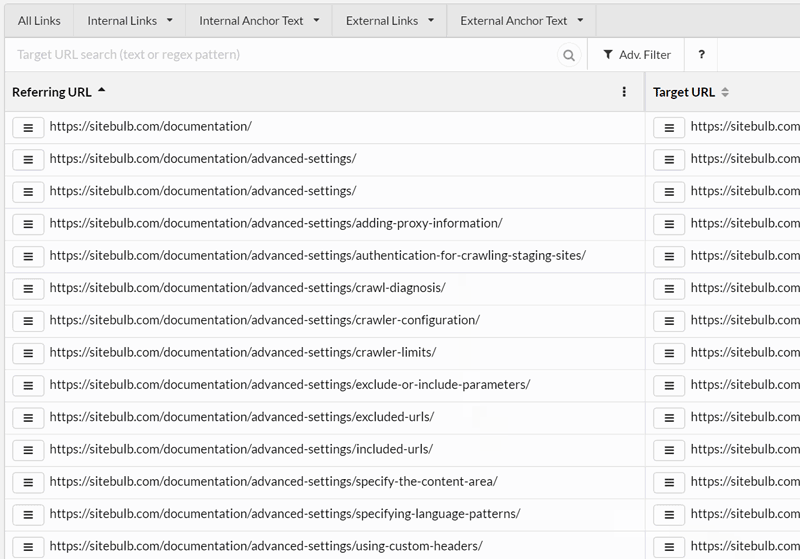
You can learn more about the Link Explorer and how to use it in our guide post here.
#2 Revamped Links Overview
Building on the Link Explorer, we wanted to rework the Links report itself, to help highlight some of the data that is now accessible in the tool.
We have added a number of new data tables, which allow you to dig straight into the link data itself. Straightforward, and super useful:
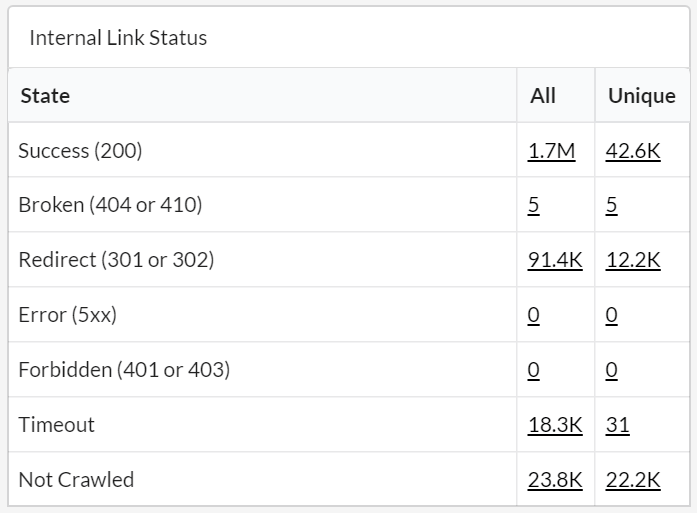
Clicking through any of the underlined numbers brings you through to the Link Explorer with the filter applied, so you can investigate further.
Of the new data tables we've added, this one is my personal favourite:
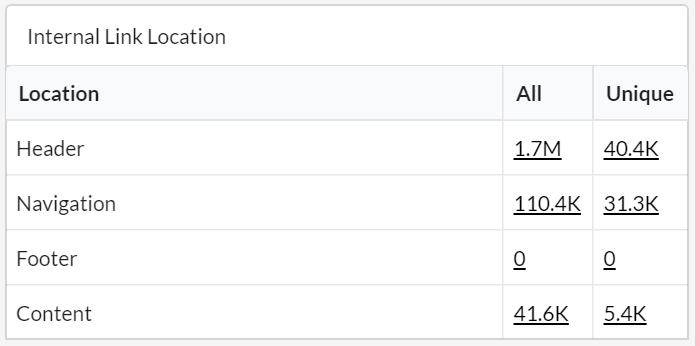
This separates internal links based on where they are located on the page. So you can finally differentiate links found in the content from links found in the header, footer or navigation (e.g. sidebar).
You may have also noticed we have these two columns 'All' and 'Unique'. The 'All' column represents every single link found, whereas 'Unique' represents links that have unique anchor text, target URL and link location (i.e. a templated header link from 500 pages only counts as 1 unique link).
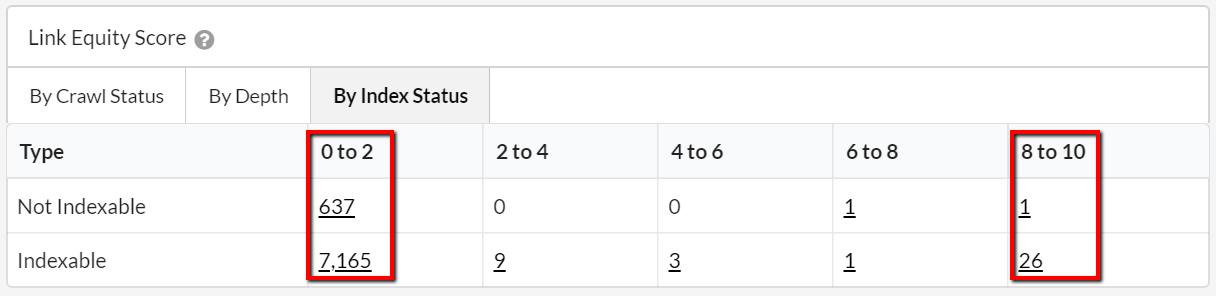
We've also added some tables for Link Equity Scores, which plot pages grouped by ranges of link equity against different technical metrics in the crawl data. The ranges go from 0-2 (weakest pages) up to 8-10 (strongest pages).

- Link Equity by Crawl Status allows you to quickly spot if you have any broken or redirect pages that are strong in terms of Link Equity, which is a wasteful use of the site’s Link Equity.
- Link Equity by Depth allows you to see where strong or weak pages lie in the overall architecture of the website. Typically you would expect to see the strongest pages at depth 0 or 1, with the weaker pages much deeper in the architecture.
- Link Equity by Index Status allows you to spot any strong pages which are not indexable, which is a wasteful use of the site’s Link Equity.
Additionally, we have also added Link equity score as the second default column on all internal URL Lists, to surface this data more easily.
#3 Add your own non-descriptive link text
In the Links section, one of the things that Sitebulb checks for is 'non-descriptive text', which basically helps identify instances where a website is not passing on relevancy signals through anchor text, and instead using generic text like 'read more' or 'click here'. These can represent opportunities for optimization.
Up to now, this was a pre-set list in English, that could not be customised by the user. To improve this functionality, we have added a new 'Global Settings' option:
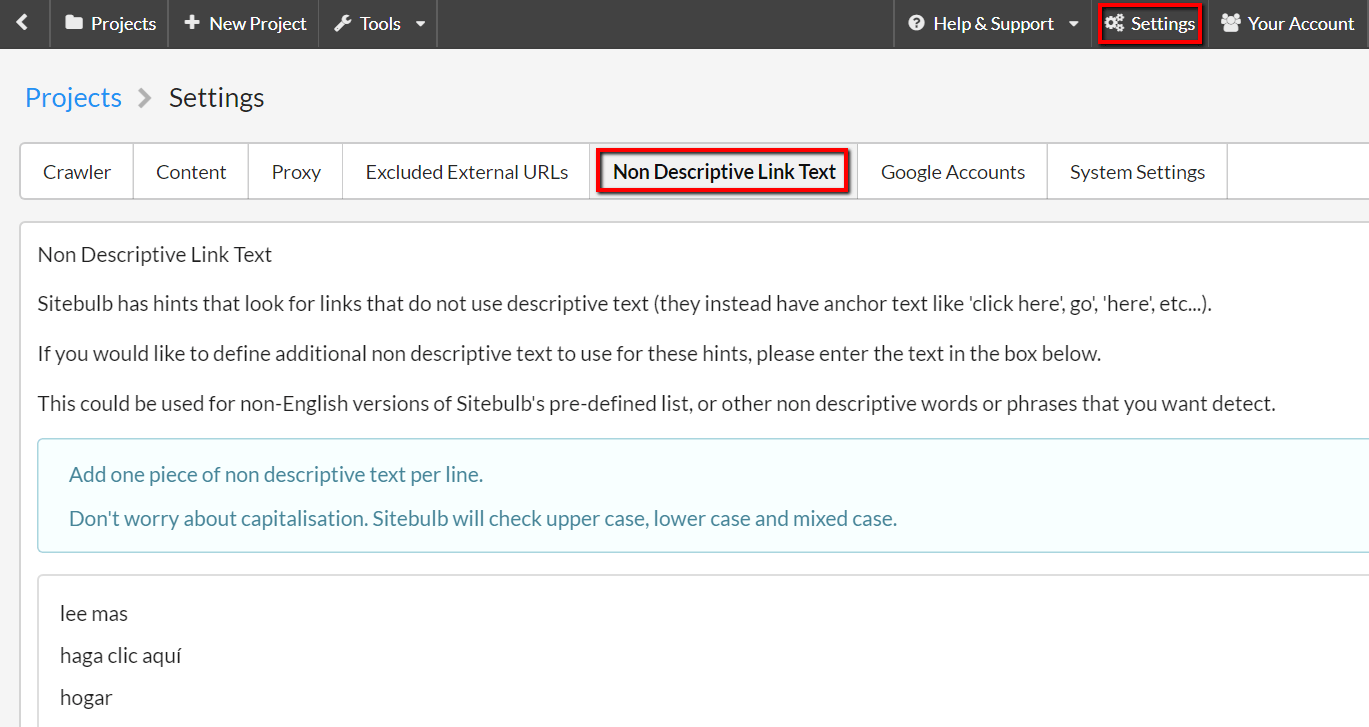
Add in any other variations you please, such as non-English generic text, and Sitebulb will use these to classify non-descriptive links in future audits.
#4 New Indexability Hint added: Canonical points to homepage
This highlights instances where a URL contains a canonical tag that points at the homepage (what else were you expecting?).
This sort of problem, on a large scale, is symptomatic of a fundamental misconfiguration of templated or dynamically driven canonical tags, and could be damaging from an indexing perspective.
Fixes
- When building printable PDF reports, Sitebulb was generating blank PDFs, which was pretty fucking useless indeed.
- The 'Save' button on Site Visualisations was not working at all. As in, it was not saving the graph. Which is literally its only job in life. One fucking job.
- The 'Hint Details' HTML highlighter view for the Hint 'Has a link with whitespace in href attribute' was not correctly identifying the errors.
- On some sites the CSS and JS code coverage was incorrectly being set to 100% wastage.
- This Hint was wired up wrong: 'Canonical URLs with no internal links' (it would say on the list, e.g. 500 URLs, then you would click through and there would only be 5 URLs in the list. Which is wrong. Like I said).
- Special characters were not being uploaded properly to Google Sheets.
- When clicking 'URL Details' from a Site Visualisation node, it was not taking you to the URL Details page.
Version 3.3
Released on 11th February 2020
Updates
#1 Export spreadsheets directly into Google Sheets
We regularly end up in conversations with our customers like this:
Random Customer: Hey Sitebulb, what's up with you?
Us: Sup?
Random Customer: I love your exports, but it is a pain in the ass uploading each one to Google Sheets separately.
Us: Seen.
Random Customer: We deliver client audits through Google Docs that link out to each Sheet; it would be dope if you could just upload them all to Sheets for us.
Us: I getchu.
This 'upload everything to Sheets' workflow is common among a bunch of our users, and we are keen that Sitebulb fits into existing workflows, so it totally made sense as a feature for us to add.
Now, you can upload pretty much any export you find in Sitebulb, directly into Sheets. Once you hit an Export button, you'll be able to select the Sheets option:
The first time you do this, you'll need to authorise a Google account to use, but you won't need to keep doing this step in the future:
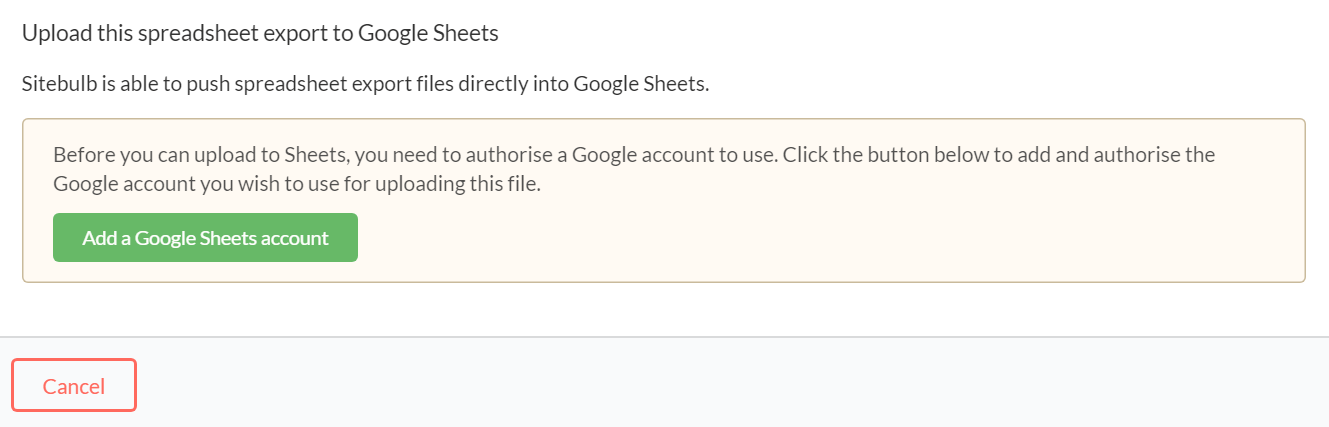
This step is super straightforward, and once complete you just need to give the Sheet a name (or use the pre-filled option) and hit Export and Upload.

The upload will typically take a few seconds to process, however if you are uploading spreadsheets with LOTS of data, this can take a few minutes.
Once the upload is complete you will be presented with two options, either to go into the 'root' Google Drive folder, or directly into the uploaded Sheet itself.

If you click into Google Drive Folder you'll see how the export has gone in, and that Sitebulb has created a 'Sitebulb Exports' folder in Drive, which will be the place that all future Sitebulb data is saved to. Within this you can also see that the data is organised further into Projects and Audits, so your data stays within a consistent structure in the future.
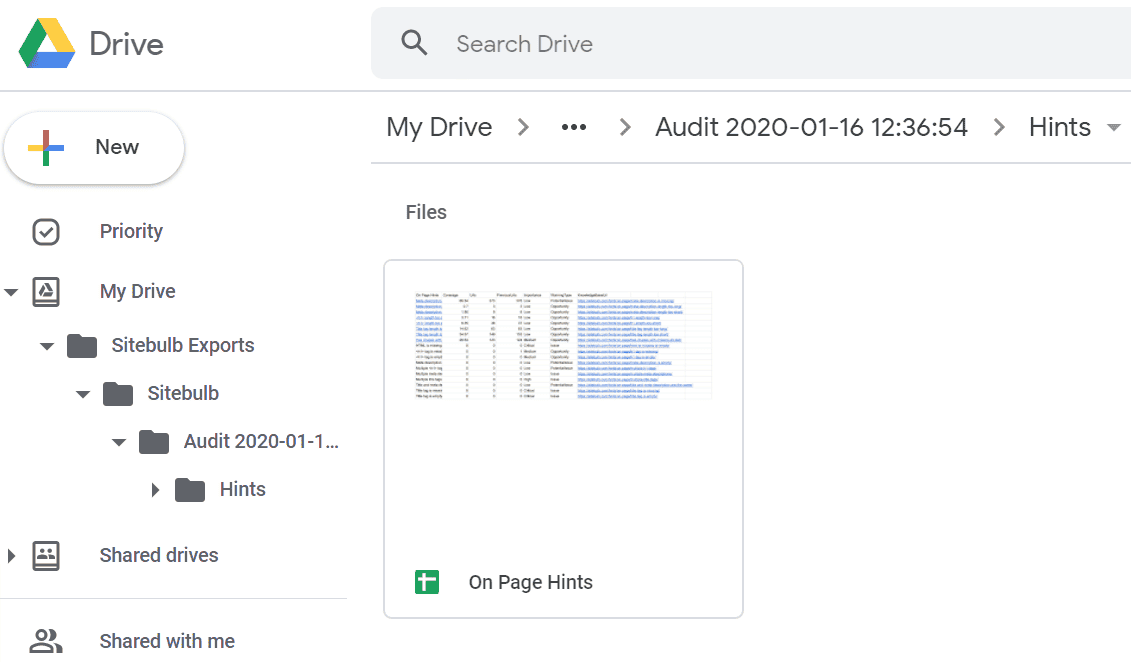
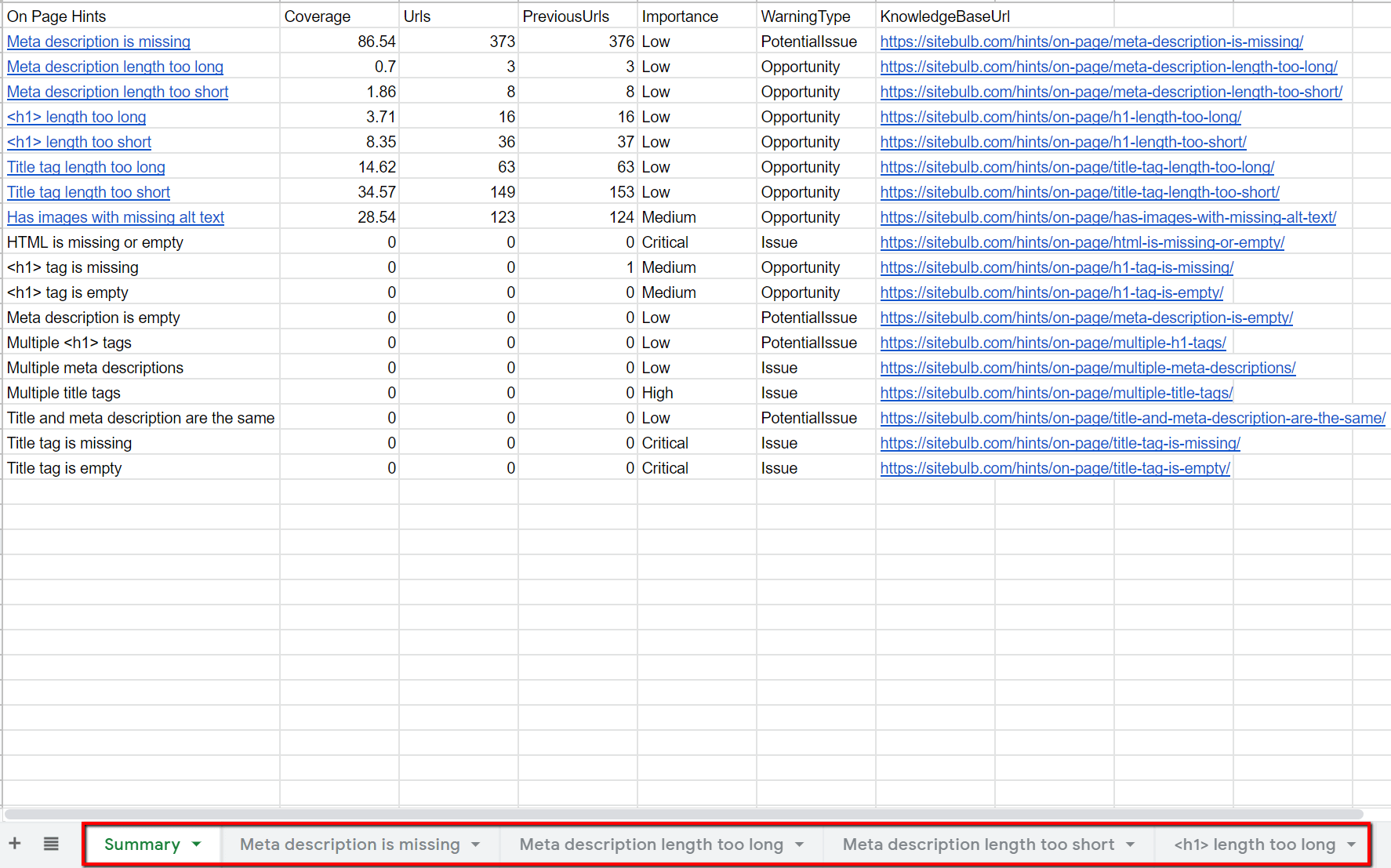
You can of course then click through into the Sheet itself, which you could do directly from Sitebulb by hitting the View Google Sheet button. In this case I selected the export option 'Export all Hints', which results in a summary sheet, which is linked through to individual Hints worksheets via the links on the left and the tabs at the bottom.
Clicking through to an individual Hint worksheet will show the URL data itself, as it appears in URL Lists in the tool:
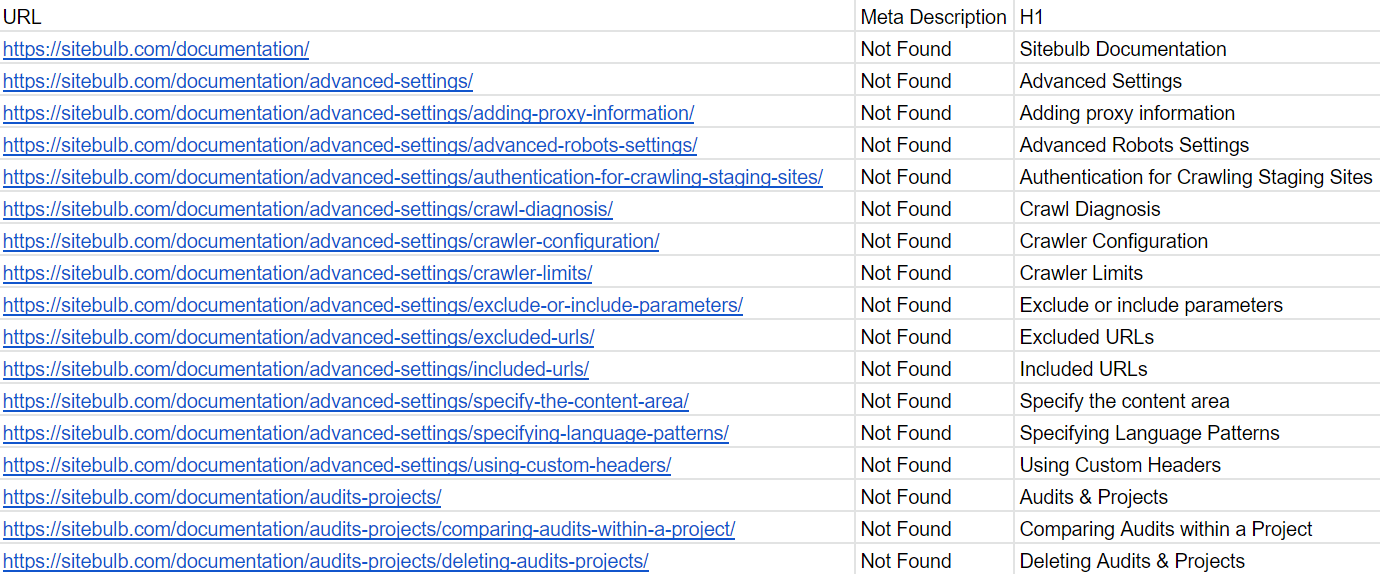
In this example, I uploaded an entire set of Hints for the On Page section, however you can also do this with individual export files and upload them to Sheets, or customise the data first using URL Lists or the Data Explorer, and push these exports up into Sheets.
Essentially, you can pretty much do whatever you want with it, however it best fits your audit workflow.
Note that you can also jump directly into the Sitebulb Google Drive folder from anywhere within the audit, by pressing the Google Drive button in the top navigation.
Quick notes on limits
Google Sheets is not designed with scale in mind. On bigger sites, Sitebulb CSV exports can go into millions of rows, but Sheets is not able to handle this quantity of data. You'll find yourself frustrated with the results if you try to push everything you possibly can into Sheets, for every audit, regardless of website size.
The limits you need to bear in mind are:
- Sheets has a hard maximum of 5 million cells.
- The minimum number of columns they allow in a Sheet is 26.
- This results in a hard maximum limit of 192,000 rows.
- File size limit is 100Mb.
- Sitebulb will truncate the spreadsheet (by rows) if you go over these limits.
Be particularly careful with Links exports, as it can be easy to underestimate their size. By way of example, this is an ecommerce site with only 22,000 internal URLs, somehow has 5,800,000 internal links (hello, mega menu):

Trying to upload this much data to a Google Sheet is a frightening prospect indeed, and if you try it you will be politely rebuffed:

Just remember... although scary is exciting, nice is different than good.
We're super excited to get feedback on this feature and find out what you guys want us to do with it next. We've written a post already on how you can make the most of Google Sheets in your website auditing workflow. If there are other ways that you currently integrate Google Sheets into your audit workflows, we'd love to get your feedback on this.
You can also read a more detailed walkthrough of the Sheets integration in our documentation.
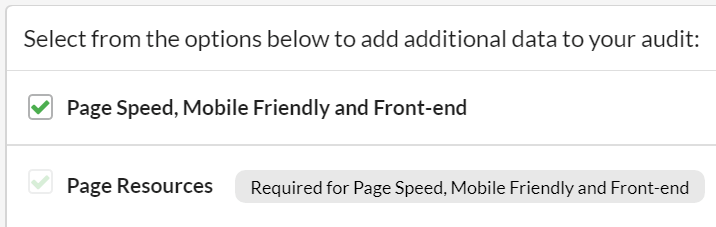
#2 Made it clearer that turning on Page Speed also turns on Page Resources
We must have confused at least 104% of our users with this in the past - they'd want to select 'Page Speed, Mobile Friendly and Front-end' but did NOT want to select Page Resources.
So they'd tick one then untick the other, and carry on with their day. When they came to watch the crawl progress, they'd storm our support desk, cataclysmic with rage, and demand to know why their explicit instructions had been ignored.
At this point we'd politely and patiently explain to them that it had all been a big misunderstanding - you see, Sitebulb needs to collect the page resources in order to do some of the Page Speed, Mobile Friendly or Front-end checks.
So we'd just collect them anyway, even if you switched it off.
It wasn't always like this, by the way, back in the good old days we had a switch in there that would automatically flick the other options on or off depending on what you selected. However people ended up like this:
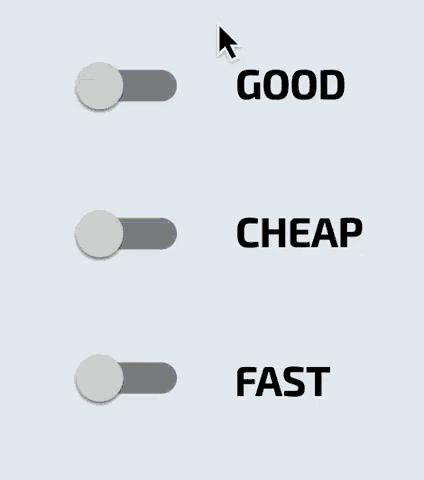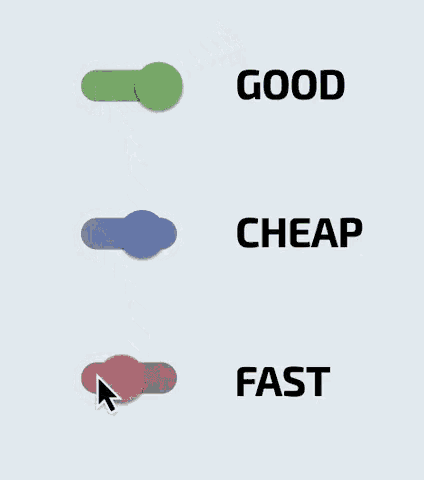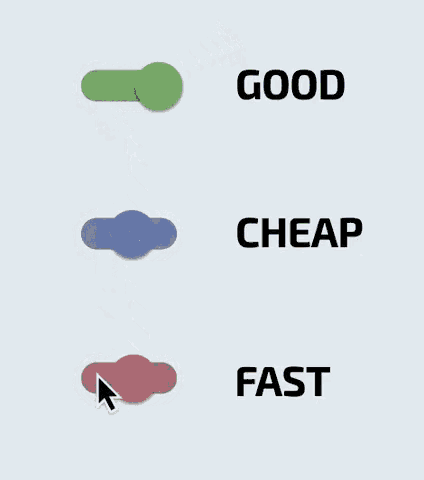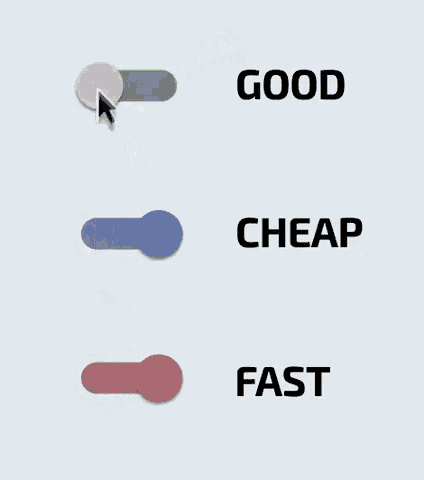
Again, cataclysmic rage ensued.
So this time we've gone for the boring option, we'll just tell you:
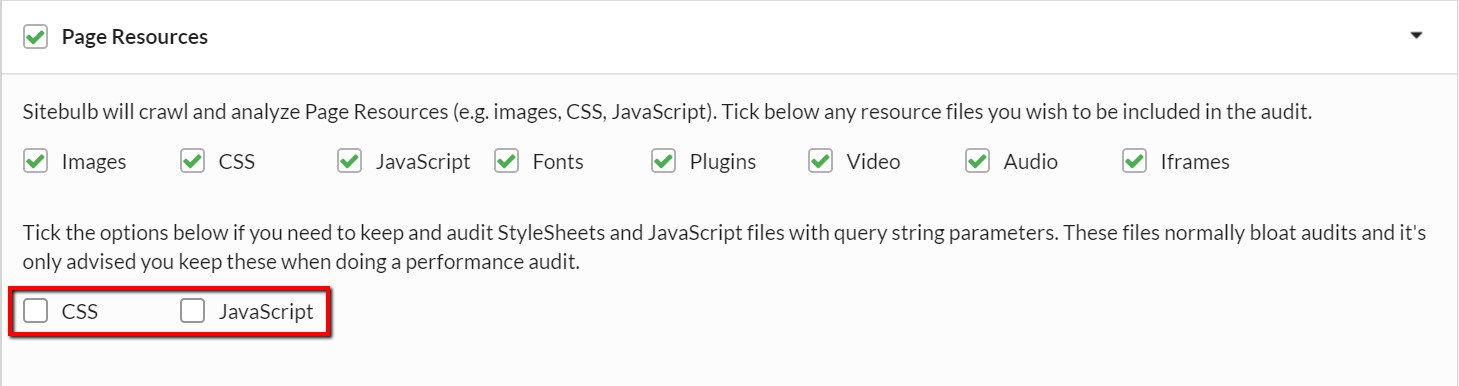
#3 Strip query strings off JavaScript and CSS (by default)
Some websites add query strings to JavaScript and CSS file URLs as a way to stop browsers from caching the files. In some implementations, this can end up where every single web page generates its own set of unique script URLs, which can completely screw up your audit as Sitebulb endlessly crawls page resource URLs that are identical save for a parameter. The crawl blows up like a fat kid in a cake shop.
Since these audits can get so badly out of hand, we have added a default setting to strip the query strings off JavaScript and CSS files, so they only get crawled once.
Props to Tom Howell for finding us a site so shitty that this made Sitebulb fall over. I hope for his sake that they weren't a long-time customer...
However, there may be circumstances where you actually do want to check if duplicate scripts are being generated, such as when doing a performance audit on the site, so it is possible to over-write these default settings. When setting up an audit, click on 'Page Resources' to open up the tickbox options, and tick the two bottom boxes if order to crawl these URLs without stripping off the query strings.
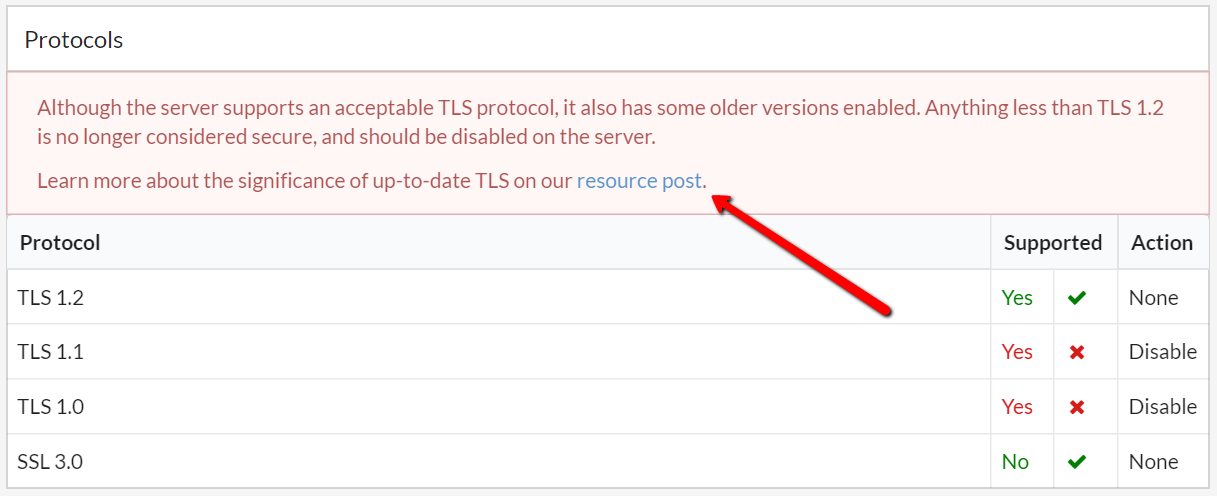
#4 Added more context and explanation to SSL warnings
Despite the fact that we have been banging on about security for what seems like days, we're still coming across folk with literally no awareness of what's going on or why it is significant.
I wrote a post recently that covers the upcoming TLS changes, and we now trigger a red warning box whenver a sub-optimal setup is detected. Within the tool itself we also link to the resource post.
#5 Added a couple of new link exports
Users doing internal link analysis have occasionally found it hard to locate the link data they need, so we have added a couple of new link exports which (hopefully) make the process a bit more straightforward.
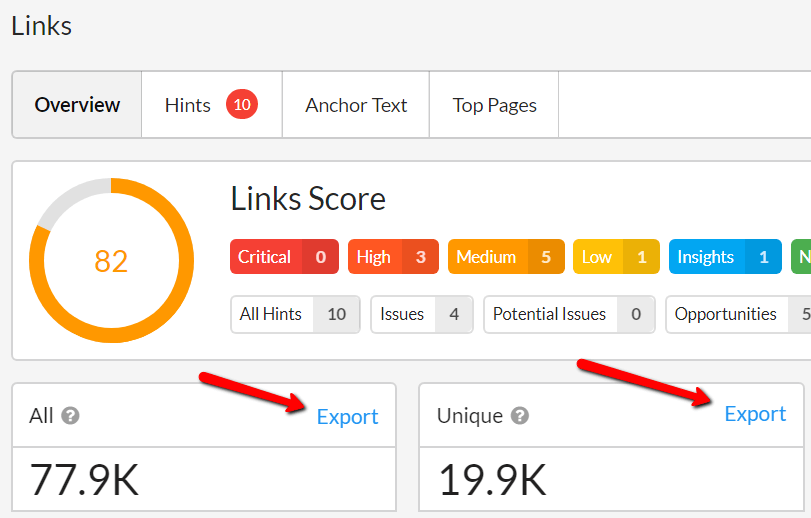
I'll briefly explain what these exports are:
- All contains the 1-to-1 link relationships of every internal link found in the website.
- Unique contains aggregated many-to-1 relationships of every unique link to destination URLs. For example, one row might represent a navigation link to the 'pricing' page, and this same navigation link is found on 499 other pages on the site. This would be reported as 1 link with 500 instances, rather than 500 separate links.
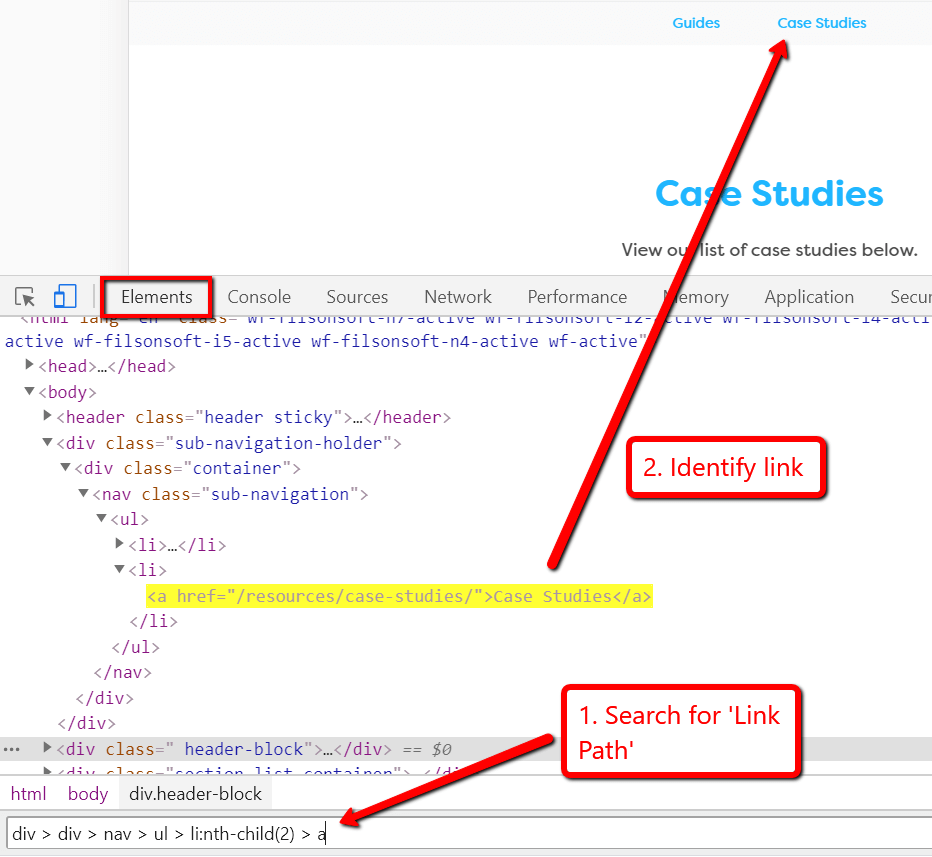
There are two columns included in this data to allow you to differentiate the unique links, these are 'Anchor Text' and 'Link Path', where Link Path identifies the DOM element.
Give the 'Link Path' reference to your developer and they'll instantly be able to find the link reference. Alternatively, find it yourself by opening Chrome DevTools, going to the Elements tab and pasting the 'Link Path' into the search box at the bottom. Hit return and DevTools will pick out the link in question.
As per the update above, these two Links exports can also be exported directly to Google Sheets (though be careful with link data!!).
#6 Added more specificity to the robots.txt ruleset
We amended some of our robots.txt rules to be more specific - now, the most specific rule based on the length of the path trumps the less specific (shorter) rule. So for example, if you had an allow rule for the path /pages/ but a disallow rule for /pages/products/ then any page in that products subfolder would be disallowed as the rule is more specific (this is all in line with robots.txt guidelines).
Fixes
- No. JavaScript (Sync) Files count was displaying as a negative integer on sites running HTTP/2. We looked into this, and discovered that you actually can't have a negative number of JavaScript files. Who knew?
- Sitebulb was returning negative download times for URLs with error (5XX) status codes. Why is everyone so negative all of a sudden?? Oh yeah, Brexit.
- On the Single Page Analyser, the same GA/GTM codes were being displayed twice for URLs that only have one code. We replaced it with a 'Not Found' designation. I appreciate this is not very flashy, but it is succint AND actually accurate.
- The XML Sitemap generator was not escaping ampersands when creating image titles. It is remarkable that some users can spot these tiny little encoding errors, yet other users can completely miss massive buttons on our pricing page 'Buy Now'. Sort it out people.
- Protocol relative canonical were not being detected by Sitebulb. This was causing pre-audit process to keep notifying the user that the canonical is different.
Version 3.2.3
Released on 17th January 2020 (hotfix)
- Improved mixed content report.
- Better reporting in instances where Chrome is autoupdating resources.
- Updated the 'Hint Details' HTML highlighter for resources that reference http:// URLs.
- Updated the resource URLs list within the URL Details view details, so all http:// urls are surfaced to the top.
- Fixed an HTML parser bug that was setting some links to lowercase.
Version 3.2.2
Released on 16th January 2020
Updates
Crawl standalone AMP sites properly
Most AMP implementations are set up as an 'AMP equivalent' to a regular HTML page. Set up correctly, these AMP pages have a canonical pointing back at the HTML equivalent, and Sitebulb is built with this understanding. As such, AMP pages do not contribute to internal link counts or link equity calculations, and you won't see them on Site Visualisations.
However, every so often we come across a site that is built in 'standalone AMP' (sometimes also called 'pure AMP'), where it is AMP from the ground up, there is no HTML 'base' and an AMP equivalent, it's just all AMP to begin with. On these sites, you really do want to count the links and see all the pretty graphs, so we needed to come up with a way to accomodate these sites as well.
I give you, the second AMP tickbox:

To clarify, most of the time you will NOT need to tick this box, as pure AMP sites are rare. But on the occasion you do need to audit one, this is absolutely essential in order to get a proper audit.
Increased emphasis on breaking the issues
By adding various critical Hints, we have tried our best to raise awareness of the issues that can arise from including elements in the
Here's a quick example, if we 'View Source' we can see there is an in the
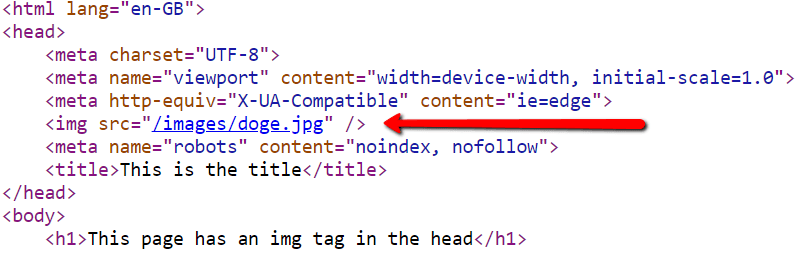
Now, right click to 'Inspect' and bring up Chrome DevTools, we can examine the rendered DOM ('Elements'), and all of a sudden the
has closed early, and the meta robots and title tags have ended up in the .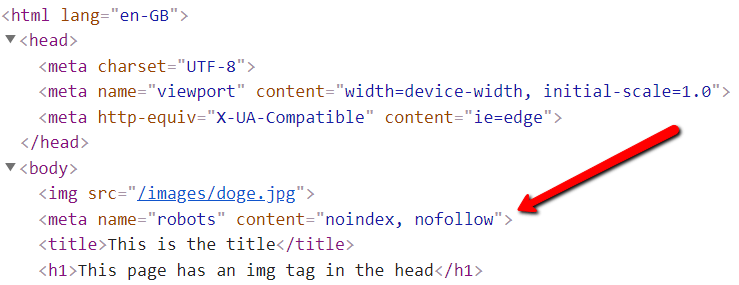
And to be clear, the rendered DOM is the bit that Google use when they crawl and render, and the claim nowadays is that they render everything.

However, despite the importance of this issue, we have seen numerous support requests where users fail to connect the dots... the data is wrong because the
is broken!So, we have taken it upon ourselves to better illuminate the repurcussions by upgrading a couple of Hints to Critical:
These are typically the effects of breaking the
, so hopefully this makes it a bit clearer what is going on.We've also added a red warning in the URL Details box:
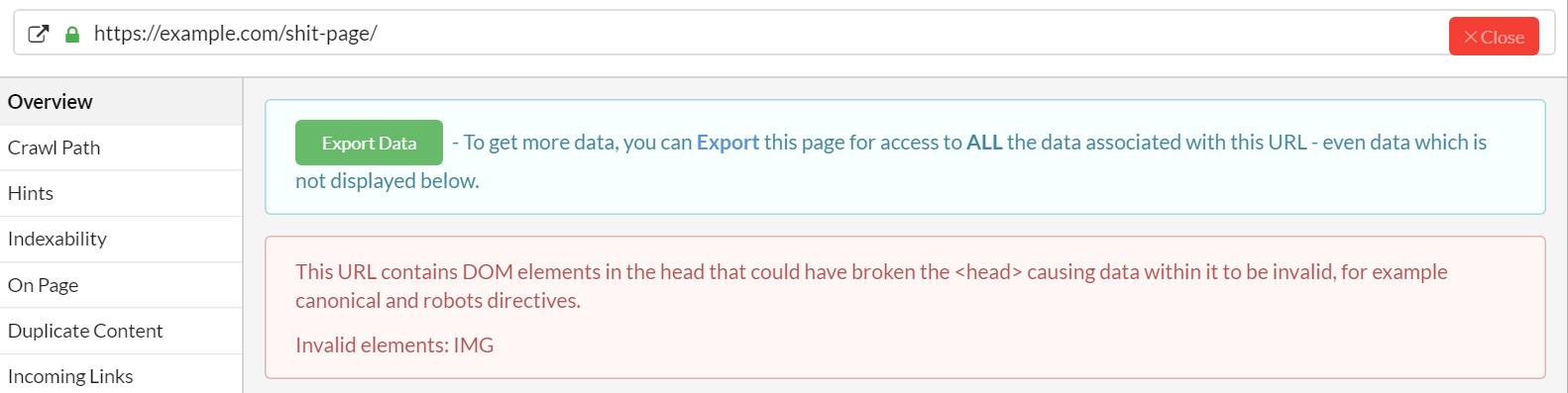
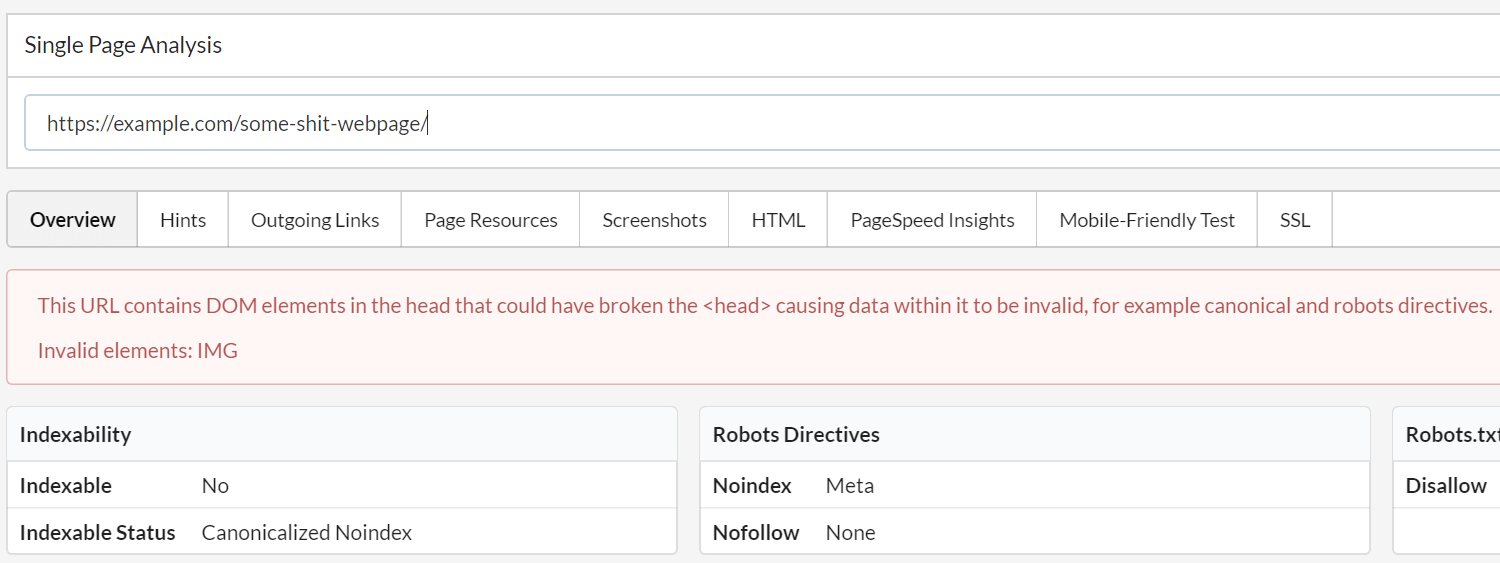
AND in the Single Page Analysis tool:
Improved Duplicate Content exports
In the Duplicate Content Hints, there is now an extra 'custom' export option, alongside the 'Learn More' button. This is a much better export to use than the one below it, which just prints off a list of URLs, as it will actually show you all the duplicates so you can group them together and quickly understand where the dups are coming from.
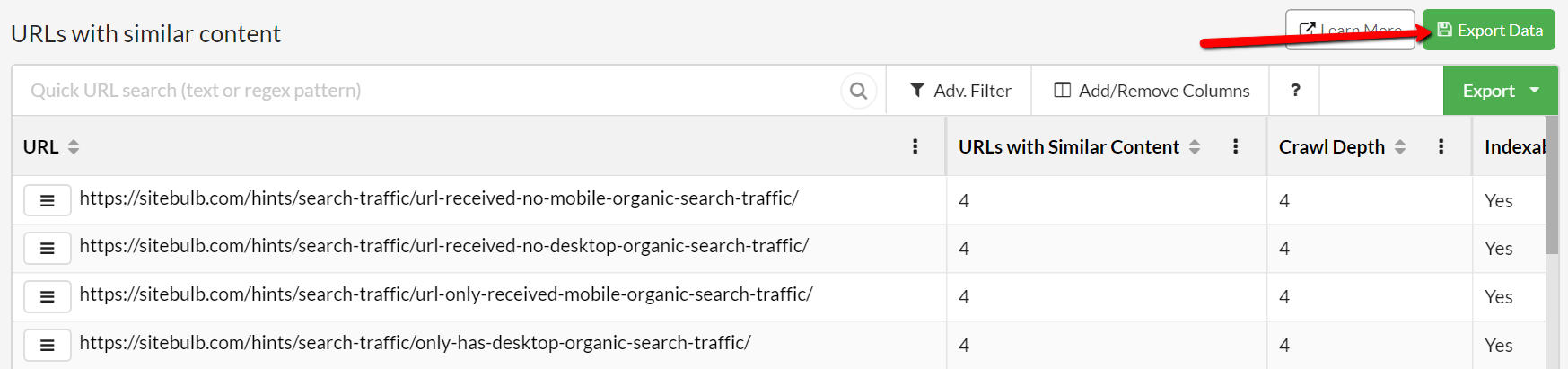
This export will show all the duplicates in the spreadsheet, so you will see the same URL multiple times in the first column if there is more than one duplicate, as below. This allows you to group the content and quickly understand what is causing the duplicates, which will help you decide what to do about it.

Some may argue that this export really should have done this in the first place, and to be fair to her, Some would be right.
Fixes
- Keywords PDF report had some incorrect (repeated) chart titles.
- Hint firing false positives: contains invalid HTML elements - this would happen in cases where < was used in the copy (e.g. Thin Thor
- We recently added the option for a 'smart export' of links for any URL list, which would tell you the link path and a count for each unique path. However one of the columns was misaligned so it looked a bit pants.
- Tweaked a few elements in dark mode where it looked more double-o-shit than 007.
- Exporting URL Lists was not applying filters than had been added in the UI.
- Unchecking 'Check Subdomain Link Status' (in Advanced Settings) was stopping included/excluded URLs from being correctly applied.
- Organic Traffic export - when you have GSC but not GA (or vice versa) the wrong export was being produced (i.e. 'the other one').
- Regional settings are now being applied to CSV exports, so if your settings require a semicolon separator, you will no longer see CSVs as 'all the data in one massive annoying column.'
- Updated regional database for hreflang, as it was missing some less common options.
- When viewing a Site Visualisation, the back button was taking you back to the Projects page not the place you came from.
Version 3.2.1
Released on 19th December 2019
Fixes
- Some URL List exports were not applying filters to the export.
- Links were being counted and reported twice.
Version 3.2
Released on 17th December 2019
Updates
Changed Google Analytics/Search Console permission login
Sitebulb's user interface is delivered via an embedded browser framework, which has allowed us to build something robust and flexible. However, we discovered an issue recently where Google was concerned with this sort of framework being used for sign-in and authentication of Google products.
They state that a type of phishing known as 'man in the middle' is hard to detect with an embedded browser framework, and have started restricting usage since the summer.
We didn't appear to be affected at first, but over the last week we've had numerous users run into this issue:
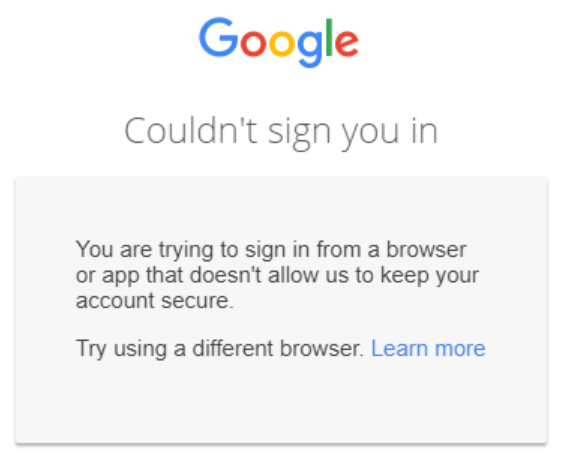
At this point we've still only had a handful of reports. Of course, there could be thousands more of you silently fuming at us, refusing to contact support. Could it be really me, pretending that they're not alone?
Either way, we decided to make a change, where authentication is now handled through a browser window rather than in-tool. Unfortunately this means we had to wipe all previous saved credentials, because they would not have worked at all. So when you start a new audit (or a re-audit), you'll need to re-authenticate.
Conveniently, this move to 'authentication in a separate browser window' also means that Sitebulb now plays nicely with password managers like LastPass, so if you have all your GA client credentials saved in there, you can now easily add them when authenticating. So I'm spinning this as a good thing that's gonna make a difference.
Make that change...
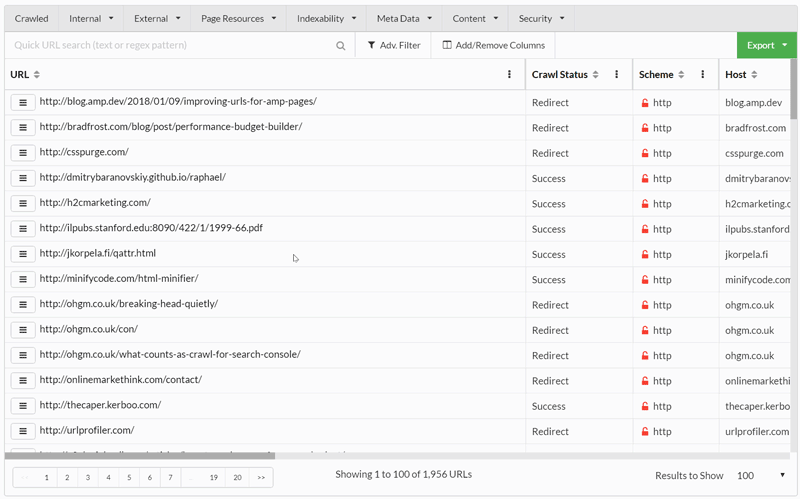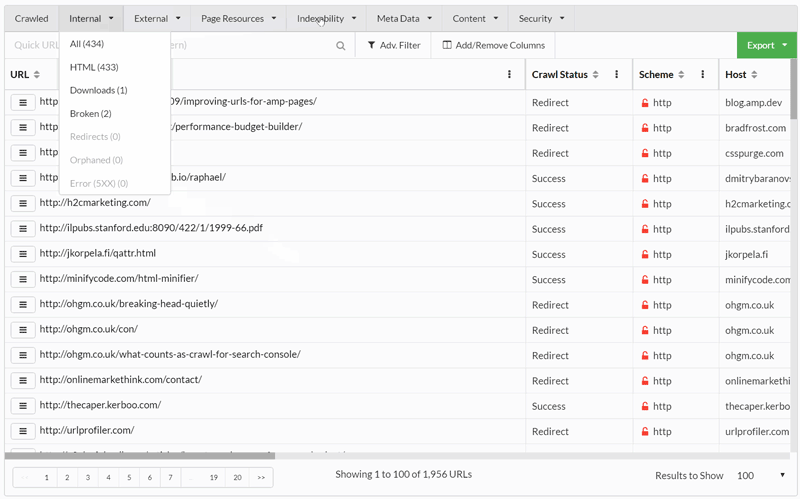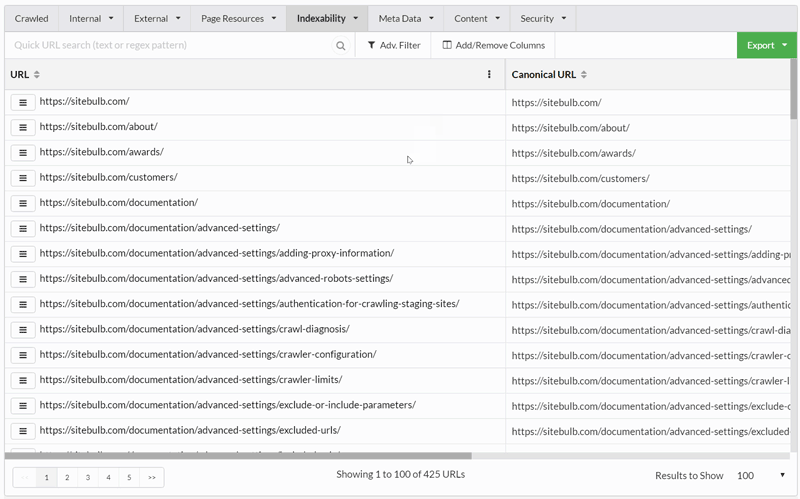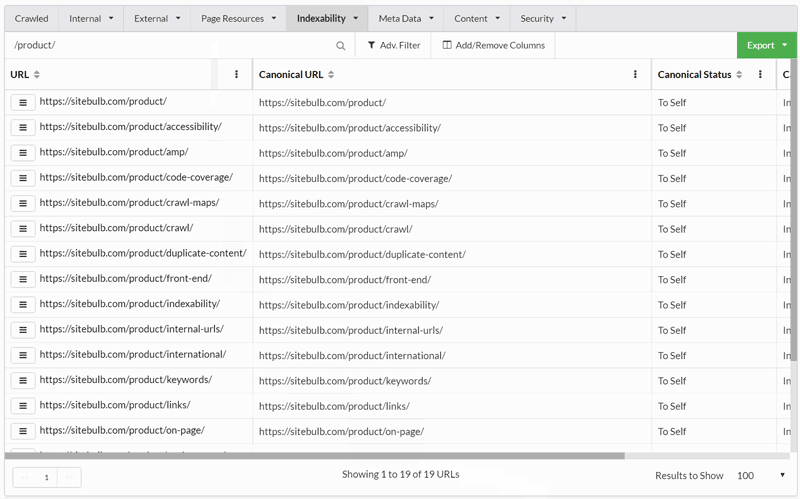
Evolution of the URL Explorer
No matter how many pretty graphs or helpful Hints we build, there remains a subset of our users who just like to see the data, in a way that is easy to jump around and quickly scan for issues.
This 'classic view' offers a lot more flexibility and allows users to port familiar workflows into their Sitebulb experience.
Re-jigged top navigation
Gareth and I too often have conversations that go along these lines...
Gareth: Sigh.
Patrick: (rolls eyes) What is it now?
Gareth: A user just told me he's only just discovered the 'All Hints' button.
Patrick: Ok...
Gareth: How can he have missed it? It's right there!
Patrick: (pretending to care) He's probably just a new customer or something. He'd have found it eventually.
Gareth: It's
Patrick: Man, that guy's a complete dickbag. Forget about him.
Gareth: Yes I know he is. But if he can't find it maybe others can't either.
Patrick: (now actively trying to walk in the other direction) I guess...
Gareth: I'm changing the entire navigation.
Patrick: Oh bloody hell.
I bring it upon myself.
And now it looks like this:
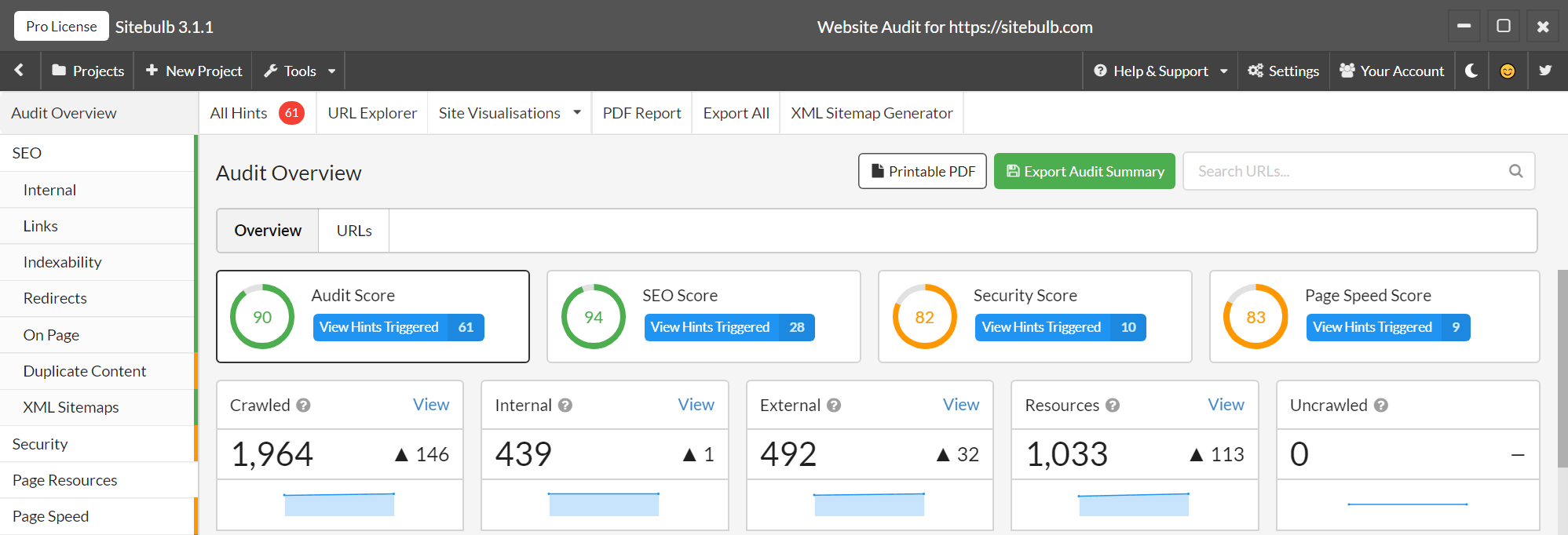
I know what you're thinking, 'But Patrick now you'll have to re-do several hundred screenshots and re-write tons of documentation because everything has moved.' Of course you are right, thank you for your concern. Hopefully my kids can entertain themselves over Christmas.
But it also affects you. Hopefully everything is a little more intuitive and still easy to find. If it's not, let us know!
The left bar on the old 'Dashboard' has been removed, and all those options pushed up into the grey nav-bar.
You'll also notice a new 'Tools' dropdown:
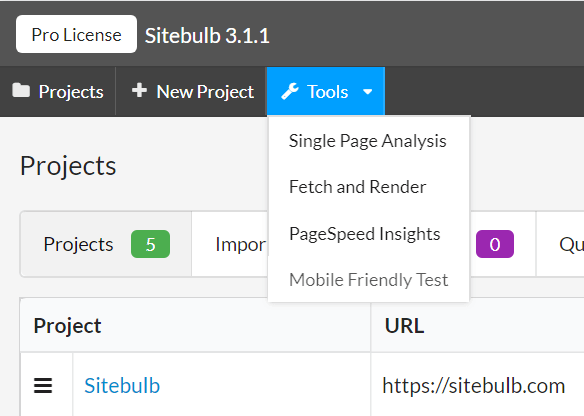
Which is 4 new 'single URL' tools for quick data checks.
We'll run through each one:
New Tool: Single Page Analysis
The most comprehensive of Sitebulb's new tools. Enter a URL and Sitebulb will go off and fetch the page and render it in real-time, then present a complete technical analysis.
It presents Indexability data, meta data, triggered Hints, outgoing links (and checks HTTP status for all), page resources, screenshots, response/rendered HTML, PageSpeed Insights data, Mobile Friendly check, server/SSL security data, and a partridge in a pear tree.
New Tool: Fetch and Render
You don't need to wait for Google Search Console access to inspect live URLs and see how they render for Googlebot. Instead simply fire up Sitebulb's new tool and enter the URL. Sitebulb will render the page in real-time, then display the source code and screenshots. Change the user-agent to verify how different bots see your content.
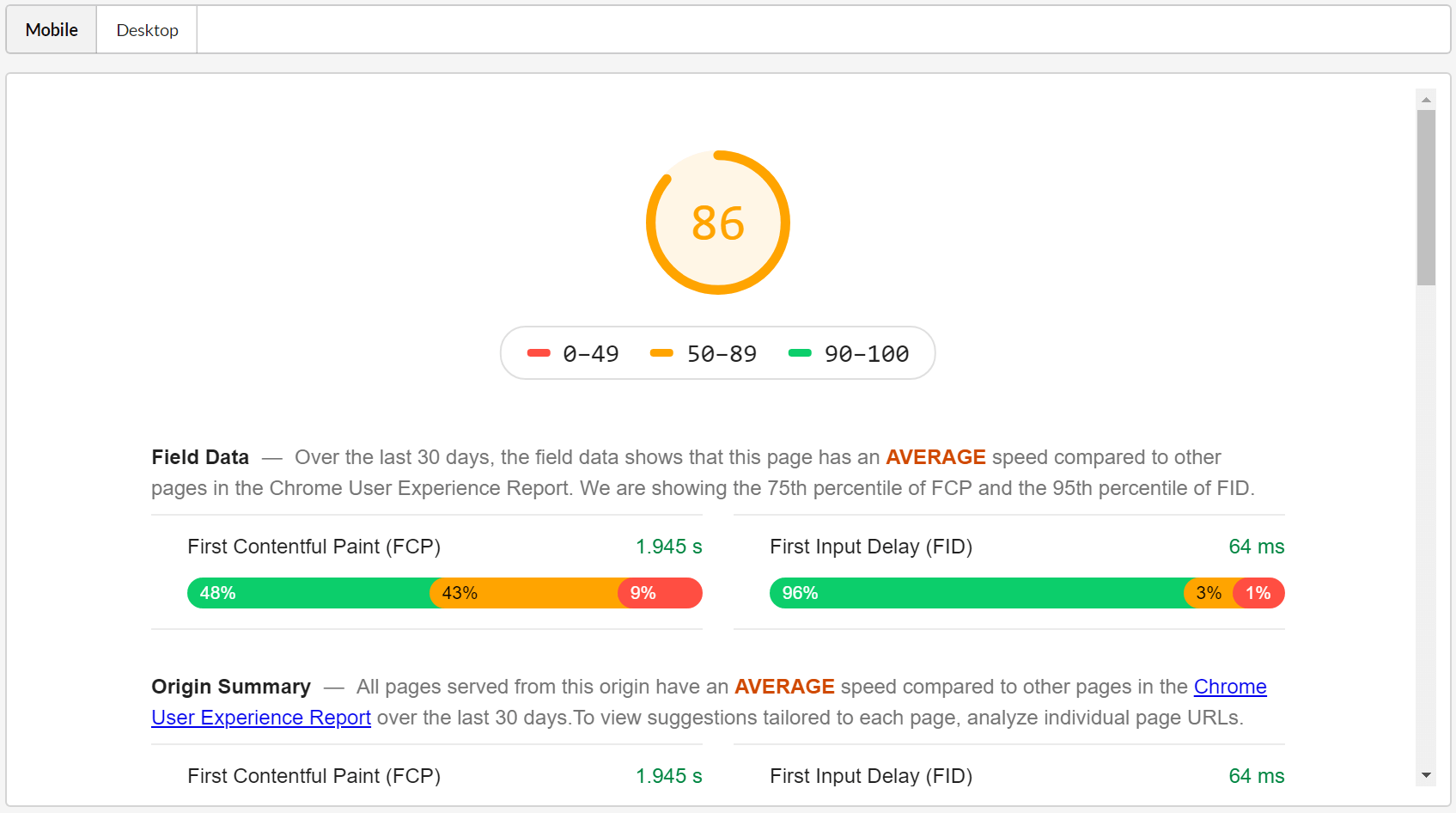
New Tool: PageSpeed Insights
This one just does what it says on the tin. Enter a URL and Sitebulb will ping the PageSpeed Insights API and pull back all the PageSpeed data, including all the cool Lighthouse metrics and CrUX data.
New Tool: Mobile Friendly Test
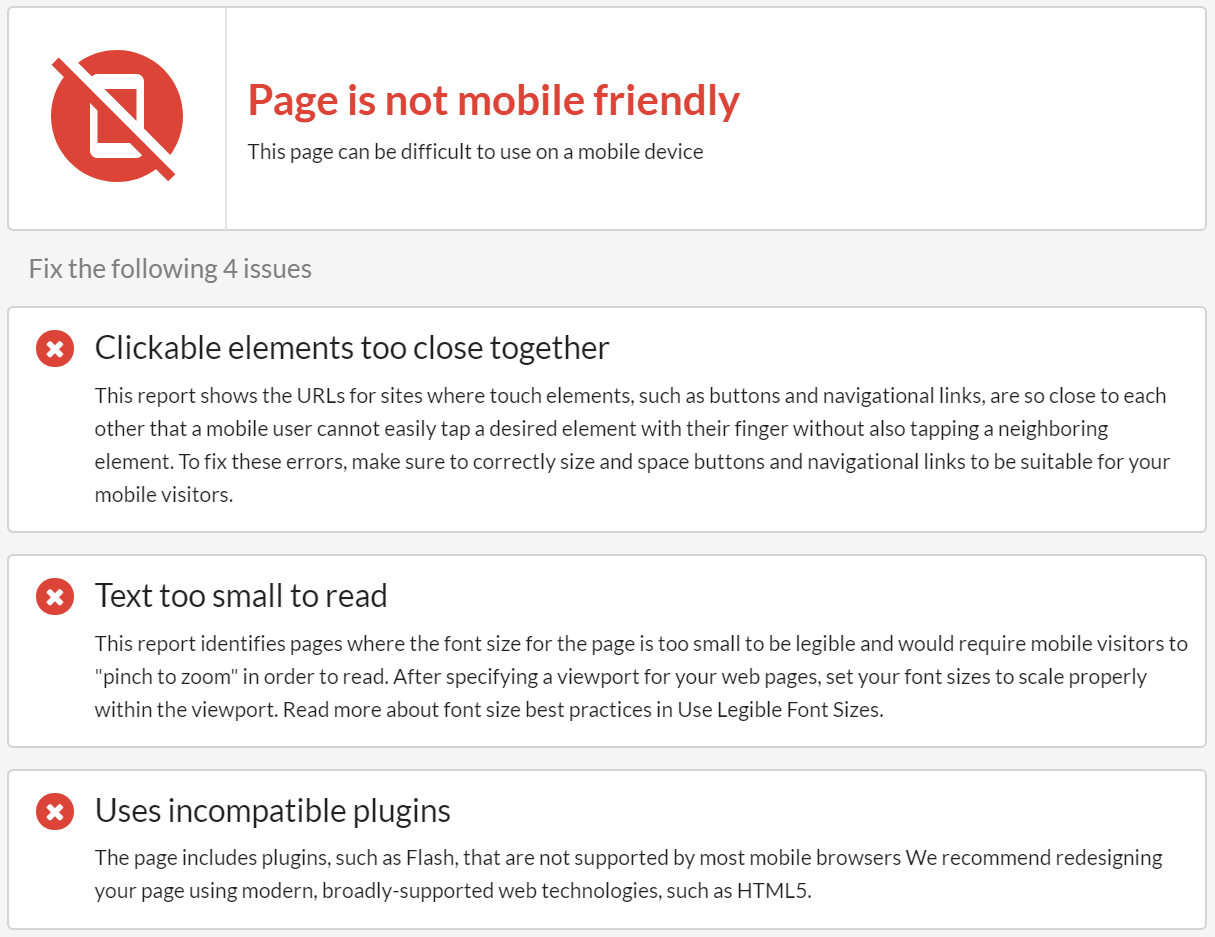
Another self-explanatory one, the Mobile Friendly Test offers quick access to Google's Mobile Friendly test tool. Enter a URL and Sitebulb will run the page through Google's Mobile Friendly API, to check if the page is mobile friendly. If not, it will list out the rendering issues that need to be resolved.
And yes, there are still plenty of sites out there that are STILL not mobile friendly. Check out this horror show.
Woof.
Upgraded rendering engine to Chromium 79
As per our v3.0 promise to keep Chromium 'evergreen', in line with Google, we've upgraded our headless Chrome to version 79, which was publicly released the other day.
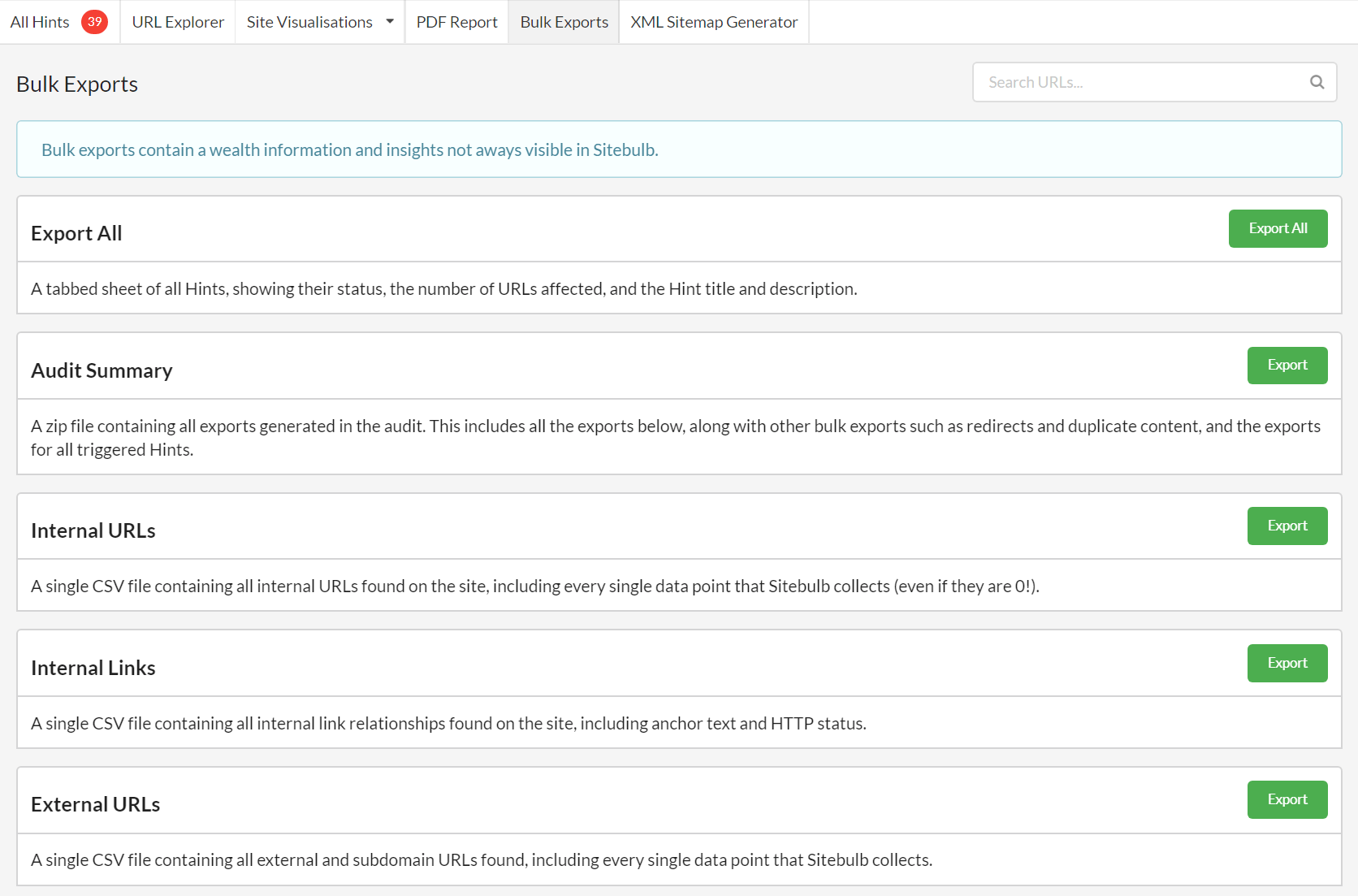
Bulk Exports are back
Occasionally we do an update and get pushback from users like 'why the f did you change that, I was using that?' Then we have to frantically undo our previous work to fix the unfix.
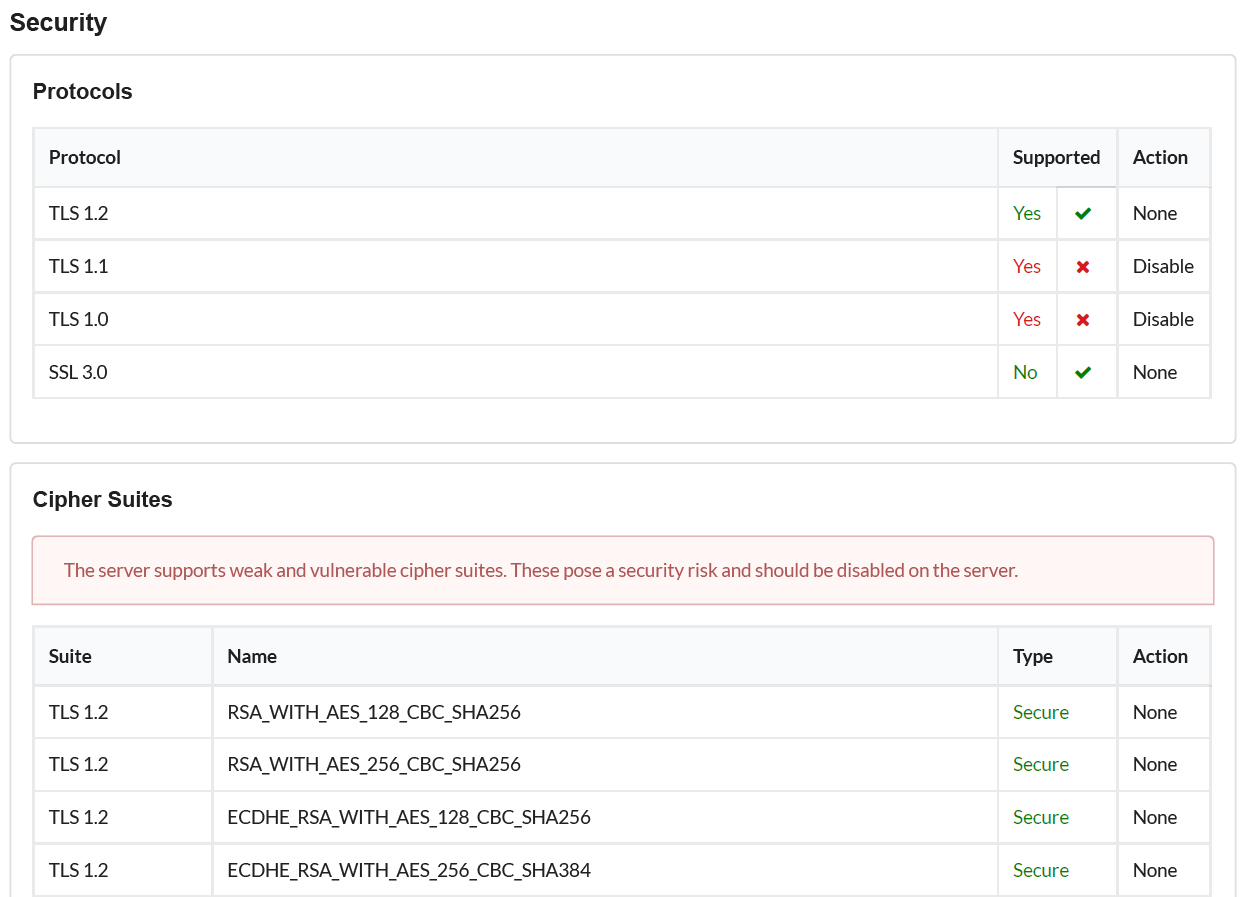
Certificate data added to Security PDF
We recently added server and certificate SSL checks, but this data wasn't being printed onto the PDF report. We've added this in now.
Fixes
- Cleaned up some small UI issues with dark mode when viewing Site Visualisations.
- In URL Lists, the little triple dot column menu was broken.
- When URLs had commas in the path, this was causing issues when exporting to csv.
- Subdomains of the start URL were not being excluded, when entered in the global exclusion list.
- Incoming link counts missing for external URLs, on the URL Details page. You will need to re-audit in order to see this fix.
- Hint: 'Page resource URL redirects back to itself' not exporting or showing up when clicking show URLs
- Removed 'Save' and 'Save and Close' buttons in export XML Sitemap modal (as they are redundant).
- Mac users were seeing inaccurate certificate issues on the new Security page.
- Removed the phrase 'click on chart segment' within PDF reports to avoid reader confusion.
- 'Loads offscreen images that appear below the fold' view link was not returning the correct number of images.
- Some URL Lists were not applying filters to exports.
- Sitebulb was not including brotli compression as a compressed asset, so we have added Brotli compression detection.
- Security PDF - was not including the new server/certificate data.
- Sitebulb was incorrectly firing the Hint: 'Missing HTML lang attribute'.
- Sitebulb was counting meta descriptions that are Empty and Too Short as the same thing.
- This Hint was not working correctly: 'Has outgoing hreflang annotation to multiple URLs'.
Version 3.1.1
Released on 20th November 2019
Fixes
- The Security report navigation was not working correctly on audits carried out on old versions.
- There was a small issue with a menu UI element in Dark Mode.
- There was a small issues with the Directory graphs, where some extra nodes were being included.
Version 3.1
Released on 18th November 2019
Updates
#1 Crawl Maps have some new friends
True innovation is rare. When we launched Sitebulb in late 2017, our Crawl Maps caught the imagination of the search industry, and a year later they won the US Search Award for 'Best Software Innovation.' Our innovation was of course inspired by Ian Lurie's exploration of using force-directed diagrams in SEO, way back in 2014.
Since our launch, we noticed a slew of other crawler companies similarly 'innovate', with startlingly familiar interpretations. In some cases, they improved upon our development, innovating on the innovation, so to speak.
It's fair to say that the Jones' needed catching up with, and since our laurels were well and truly rested on, we revisited the topic of site visualisations to see what we could come up with.
Quick sample of what to expect, and to break up this unyielding wall of text. Introducing our new 'Crawl Radial':
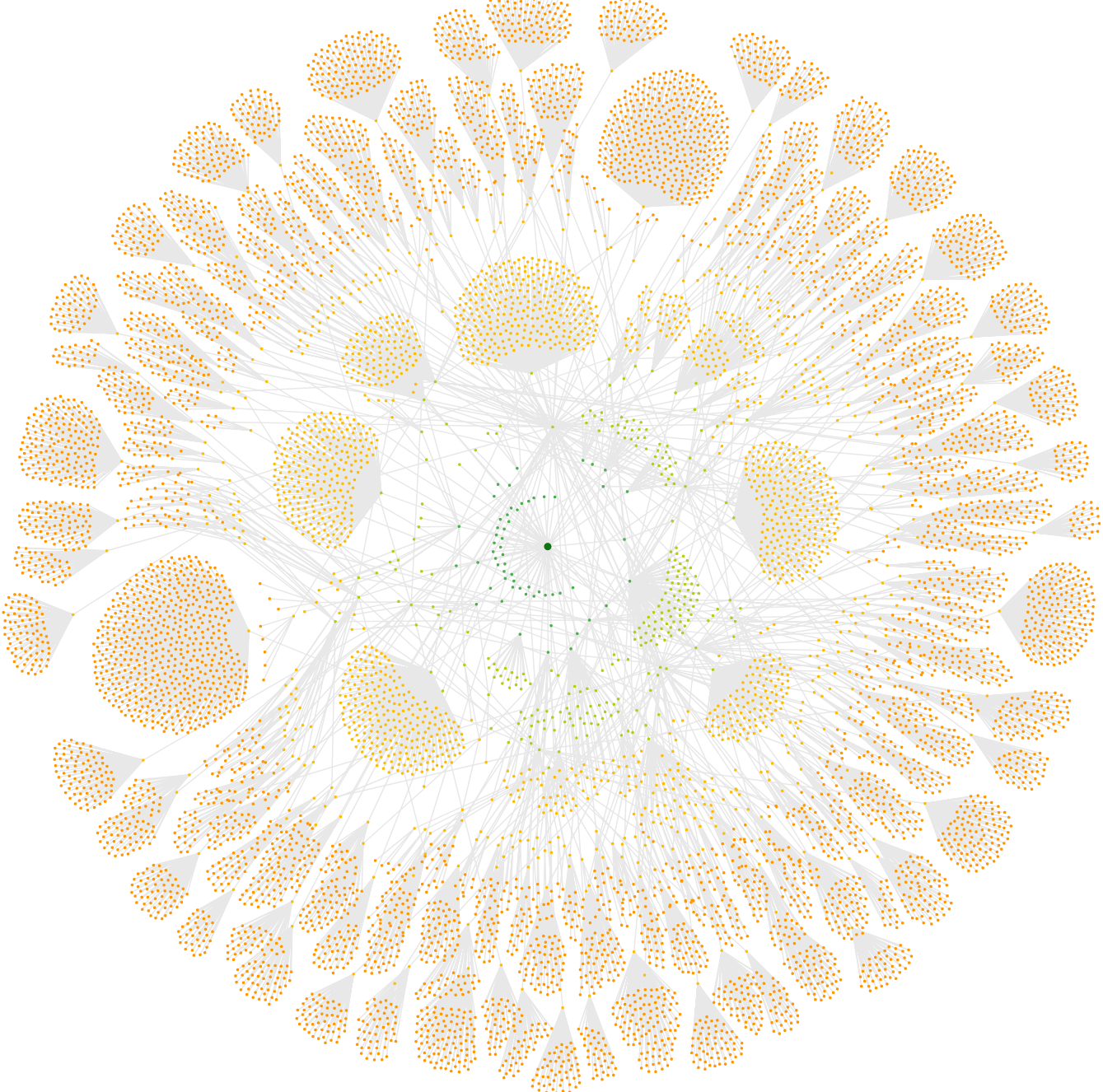
In total we now have 6 visualisation options, which are based on 2 different ways to map the data, and 3 different visual styles (and 2 x 3 = 6 people).
2 different ways to map the data:
- Crawl - maps URLs out based on where they were first discovered by the crawler.
- Directory - maps URLs based on the directory that a URL 'lives in', determined by its URL path.
3 different visual styles:
- Map - the classic 'force-directed' design, which spreads out the nodes to fill the canvas.
- Tree - a hierarchical design, where content is displayed in levels, like the branches and leaves of a tree.
- Radial – like the tree map, but pushed into a radial design - so it still shows the hierarchy.
So we end up with 3 'crawl' graphs: Crawl Map, Crawl Tree, Crawl Radial
And 3 'directory' graphs: Directory Map, Directory Tree and Directory Radial
The core difference betwen Crawl and Directory is that the Crawl graphs are mapping actual link relationships that were found by the crawler, whereas the Directory graphs are simply showing the hierarchy of the folder structure, and the connecting lines don't represent links.
I'll give an example of each one in turn, below:
Crawl Map
You should be familiar with this one. The visual style has changed slightly, but it is essentially the same as what we've been doing for years. Itmaps URLs out based on where they were first discovered by the crawler. It only includes the first discovered link location, so although this graph can be considered a representation of the site structure, it is not a link map.
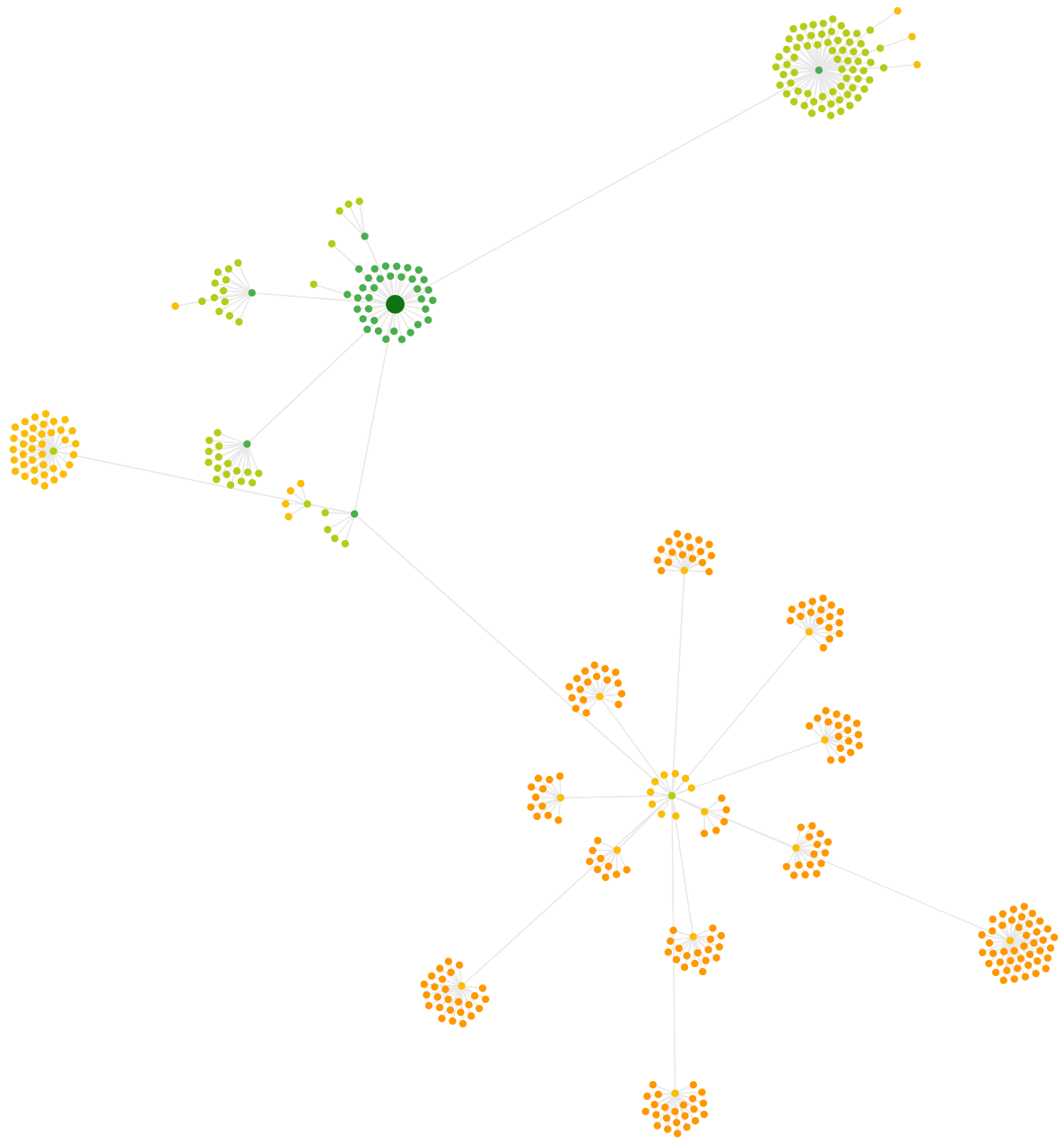
Crawl Tree
As this is a 'Crawl' type, again it maps URLs out based on where they were first discovered by the crawler. The tree structure allows you to see how child URLs sit ‘underneath’ their parent URL, and offers a visualisation of how content is grouped in the eyes of the crawler.
On big ones like this (steady on) you really need to zoom in to get the fidelity to make sense of the data. But the wide angle view is quite pretty. Oh Christmas tree...
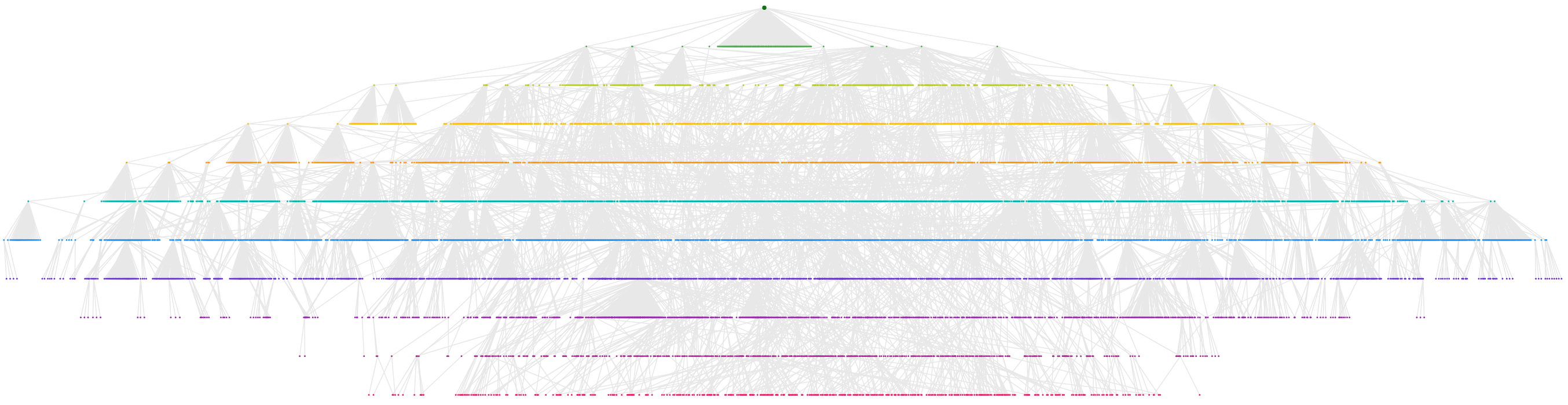
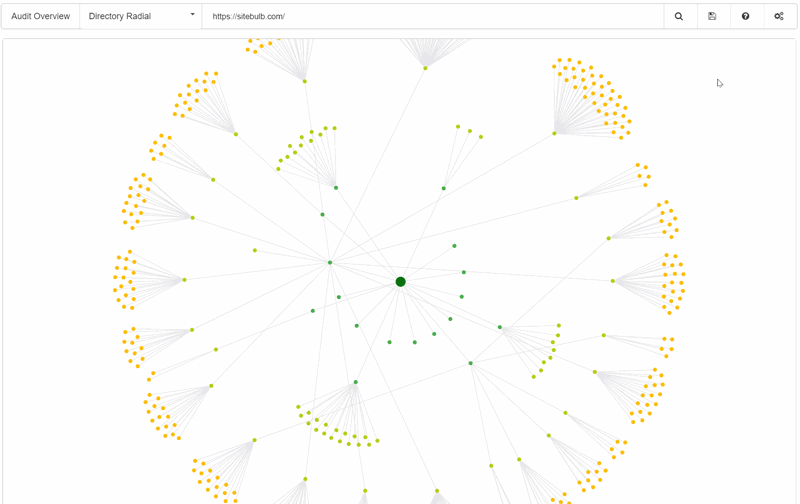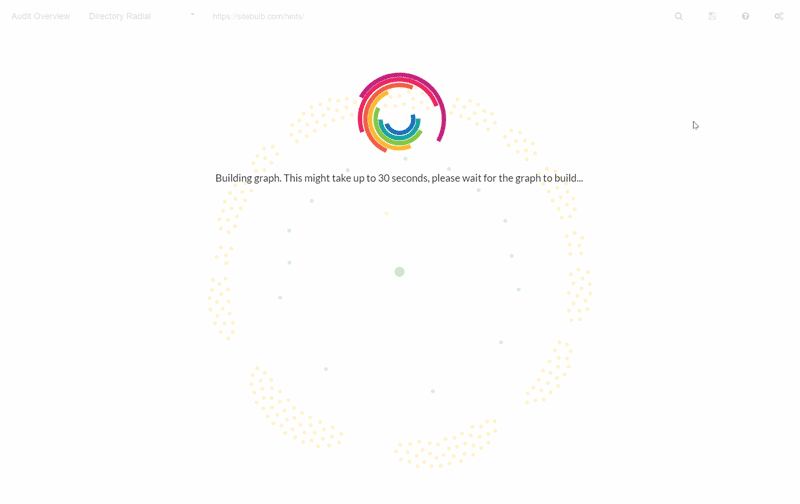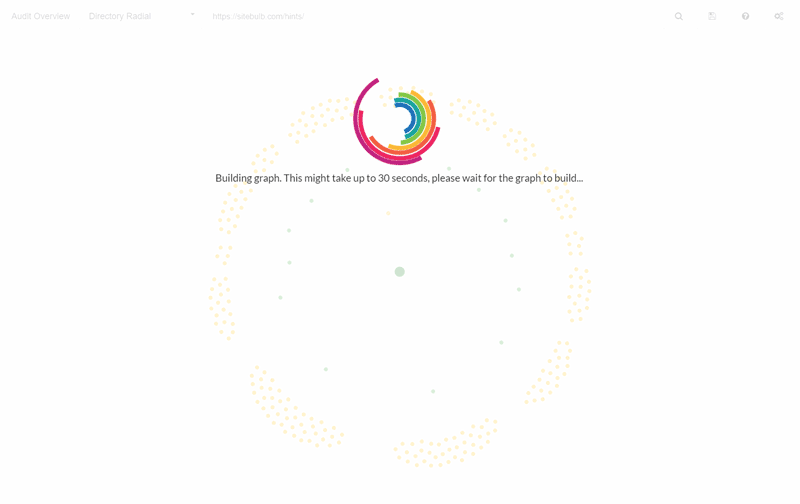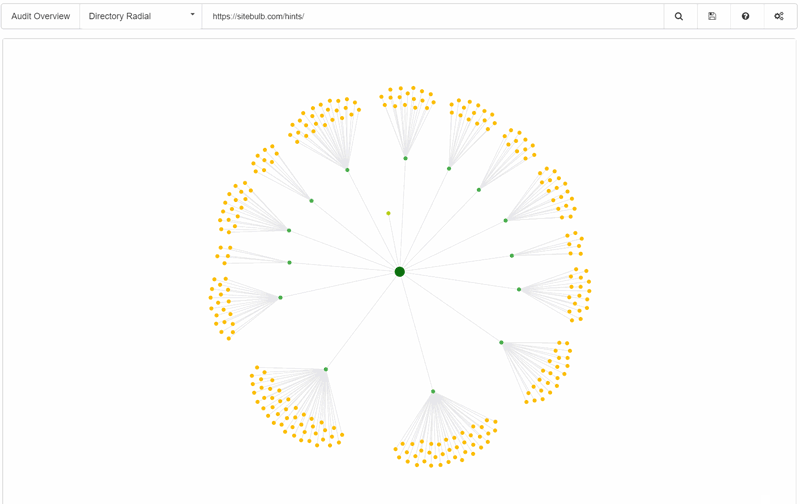
Crawl Radial
Again this is mapping URLs based on where they were first discovered by the crawler. The radial structure allows you to see the hierarchy of the site and how content sits at different levels.
We had an example of this at the top of the page. Here is another one, this is taken from the same audit as the Crawl Tree above:
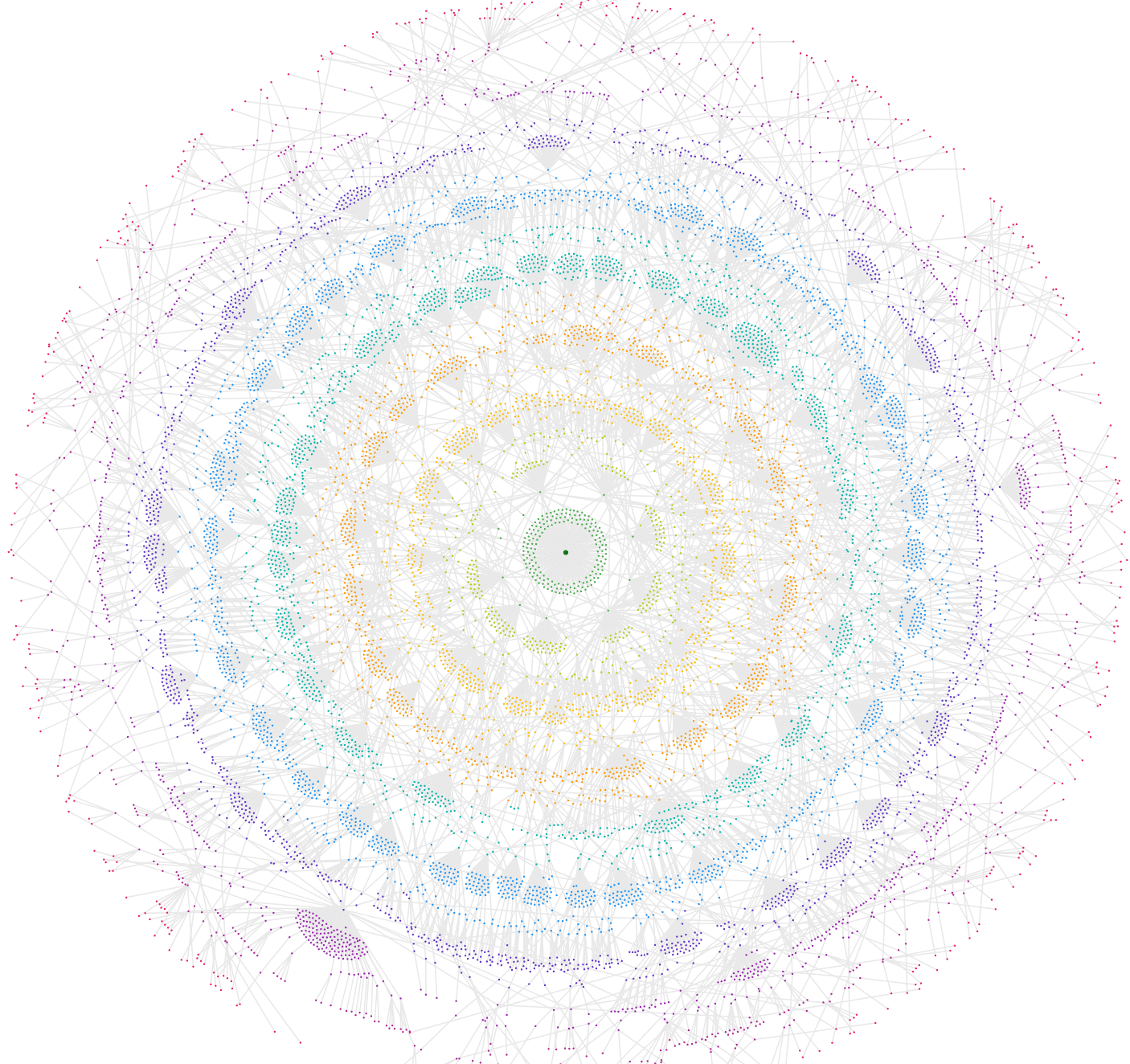
Directory Map
So this is the first directory type we're looking at. This graph shows how the website is structured based on the directory that a URL 'lives in' based on its URL path. For example, the URL https://example.com/blog/post-1 is in the directory: https://example.com/blog/
The Directory Map is a representation of how content has been clustered by design, and will often show topical clusters with more clarity than the Crawl Map. However, it can include nodes that do not resolve (or ‘exist’ as real URLs) but are necessary for the directory grouping.
They will often reveal some odd looking patterns, like this example where almost all of the content sits under a single directory:
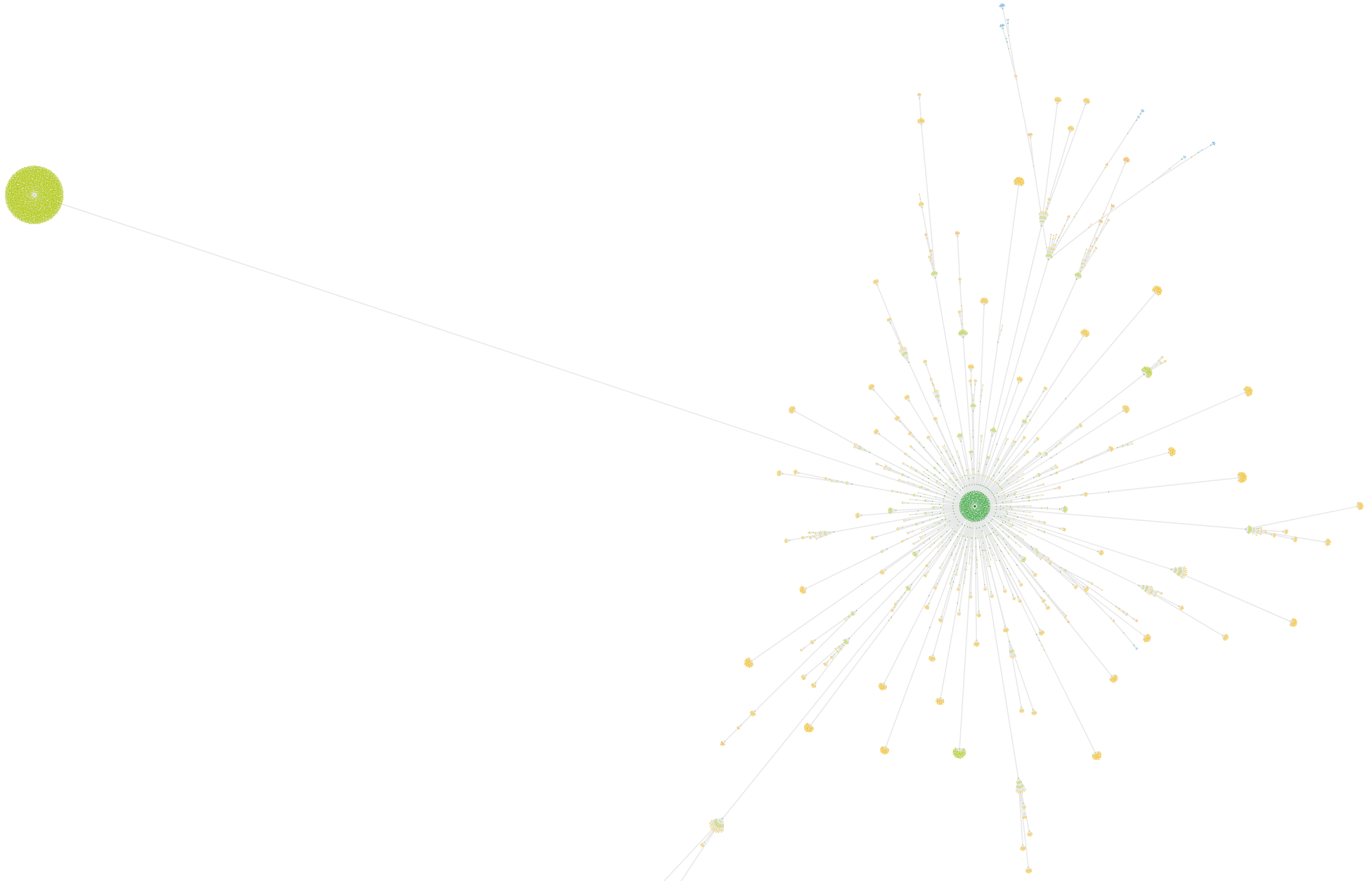
Directory Tree
Another directory type, so nodes are organized based on the directory that a URL 'lives in'.
The tree structure allows you to see how child URLs sit 'underneath' their parent URL, where the parent URL is a directory on the website. It is also worth noting that sites which do not use any kind of hierarchical folder structure (e.g. everything sites in the root) then all of the directory graphs are nigh on useless!
Directory Radial
The final variation, and this is another directory type, but this time with the radial design - which allows you to see the hierarchy of the site and how different topical clusters are grouped together by folder. It is possibly the most useful graph for understanding/communicating the way in which content is grouped together on a website.

#2 Customise site visualisations
The first thing to note is that the site visualisations now live in a new neighbourhood in the West Village:
You can navigate directly to the visualization of your choice, and then navigate between the different graphs easily from the interface. There are a range of new features that we could not do with our previous Crawl Maps, that now apply across all the visualisations:
Right click for context menu
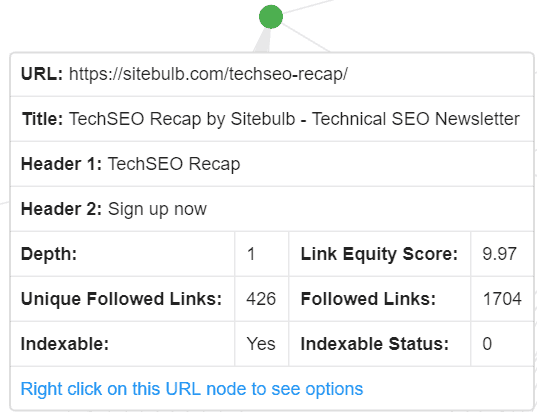
If you hover over any node your will see details of the URL including some link and meta data:
Right-click on the node will bring up a context menu with some futher options:
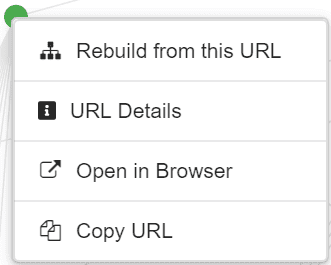
Where 'Open in Browser' and 'Copy URL' are self explanatory. 'URL Details' will slide out the complete URL Details panel for that URL, so you can dig into the details, view the crawl path, export data etc... as normal.
'Rebuild from this URL' is perhaps less intuitive, if you select this then the entire graph will build out again, using this specific node as the starting point. The same result can be achieved by...
Enter URL in 'browser bar' to rebuild from URL
Type in a URL, or select from the dropdown, and Sitebulb will rebuild the visualisation as if this URL is the start URL. Like this:
Left-click zoom to focus
If you want to zoom in on any particular node, just left click and the graph will focus in:
Settings menu on top right
The signature 'settings cog' will open up a panel where various elements of the graph can be configured:
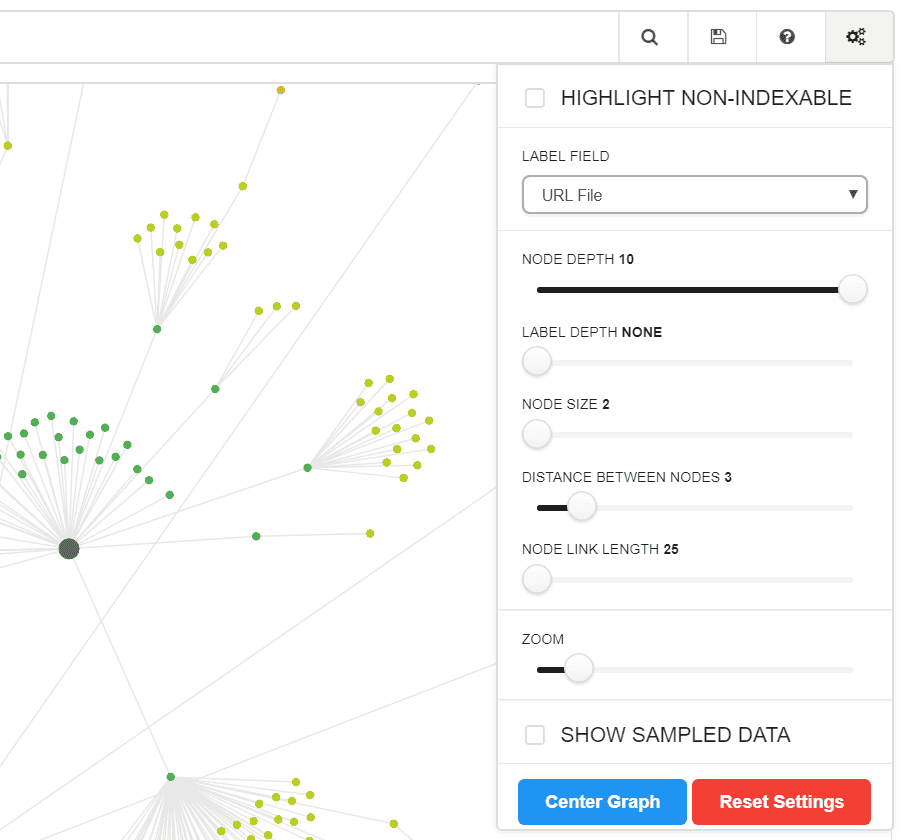
Adjusting these elements will alter the graph 'live', so you can customise and toggle with the sizes to your heart's content.
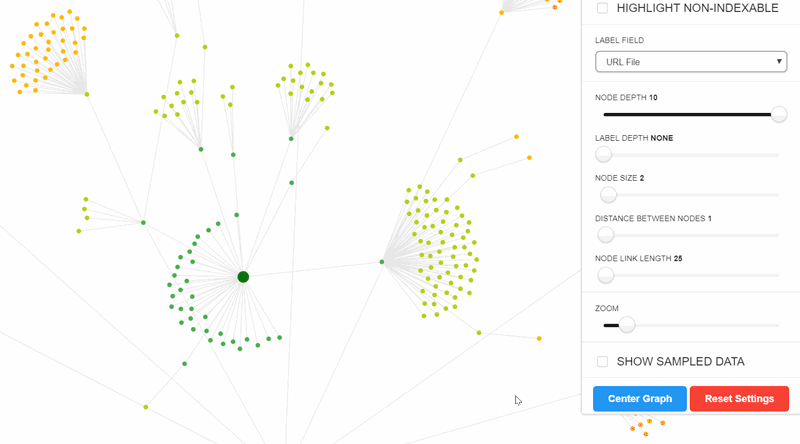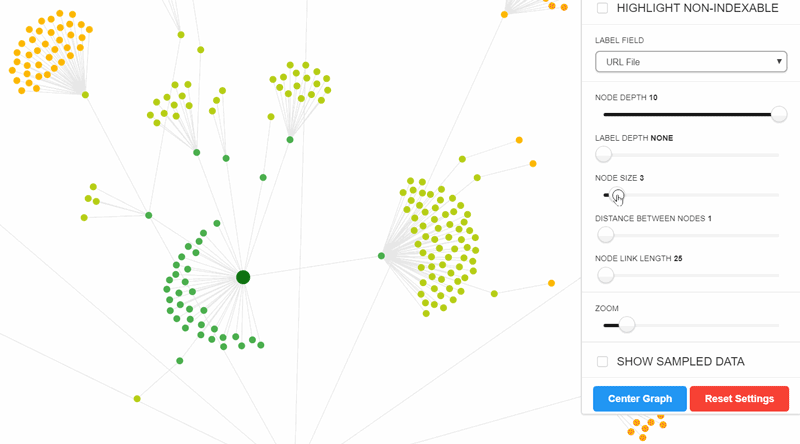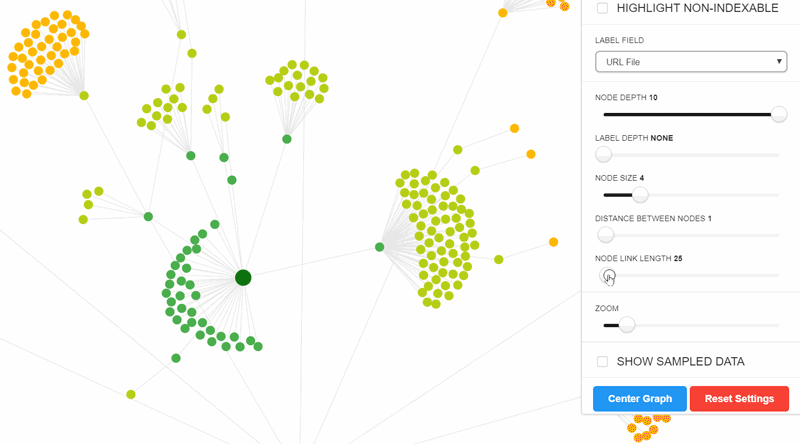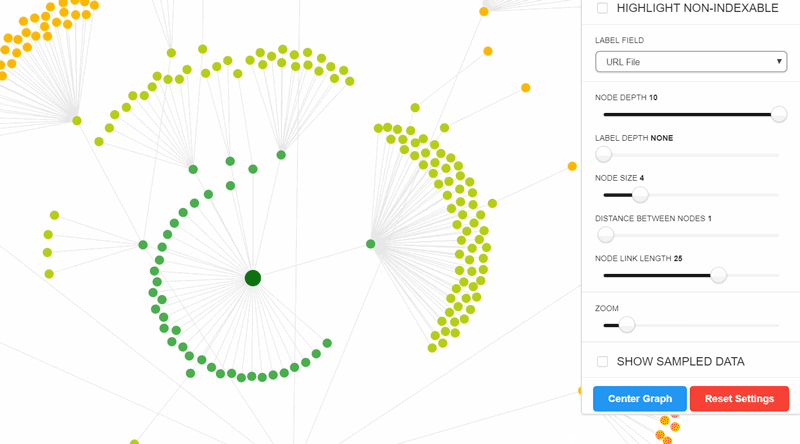
Highlight non-indexable URLs
In their new incarnation, all the site visualisations map both indexable and non-indexable URLs (up to a maximum of 10,000 URLs). There is a toggle at the top of the settings menu to highlight non-indexable URLs.
On some sites this won't make any difference, but on others it can complete change your understanding of the website.
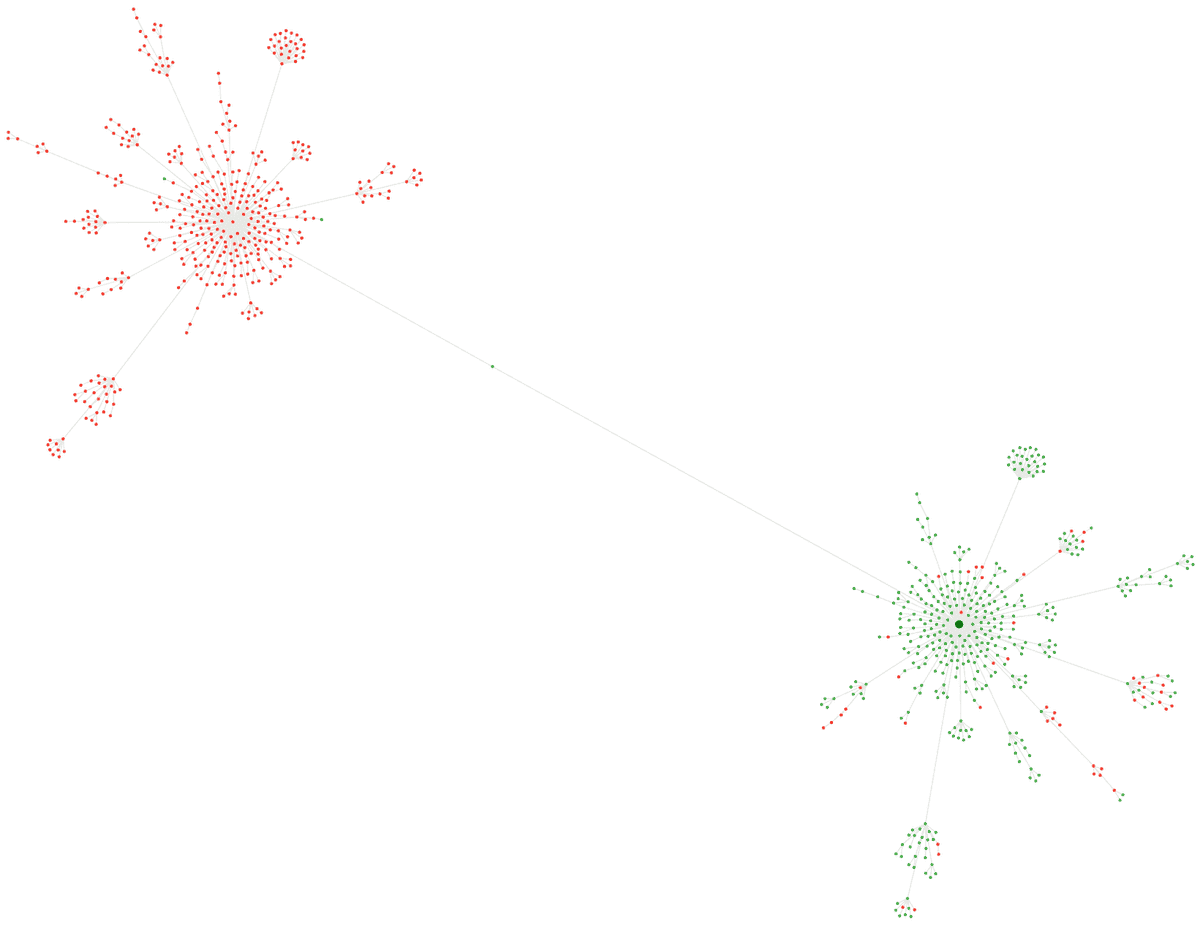
Consider this example, what looks on the surface a relatively normal Crawl Map:

Toggle non-indexable and BAM, you can see that half the map is red (non-indexable) which is due to a massive issue with canonicals:
#3 Added XML Sitemap Generator
Pick an audit, any audit, and when you open it up you should see a new menut option in the upper-right corner, 'Tools.'
Yes, we know this isn't accurately named, but 'Tool' sounds stupid, so we'll stick with this for now. The only option currently is to open up the XML Sitemap Generator.
As one might expect, this function allows you to generate an XML Sitemap using crawl data.
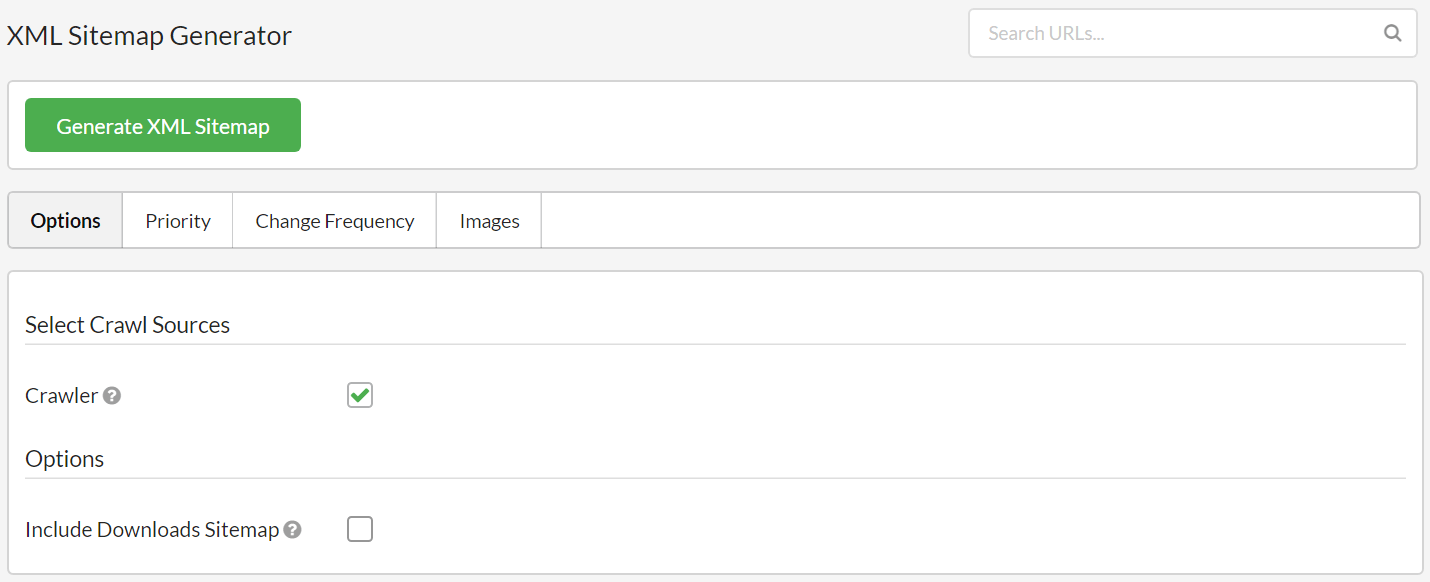
The default settings are such that most of the time you'll just need to press the big green button. It doesn't include noindex URLs or anything daft like that, so default settings should work fine unless you want to do something specific.
There are a range of options to customise however:
- Include different crawl sources: Crawler/URL List/Google Analytics/Google Search Console/XML Sitemaps (meta af)
- Include a separate sitemap for download files (i.e. PDFs, exes, Word Docs etc...)
- Include images in the sitemap
- Add/customise priority and change frequency
Sitebulb will automatically split large datasets into multiple sitemap files, and automatically build a sitemap index.
#4 New Advanced Setting: URL Rewriting
I'm not gonna lie, when we first built Sitebulb we snooped around all the other crawlers to check what advanced settings/controls they offered. We made ourselves a little laundry list of things we needed to build to offer lots of flexibility.
Sometimes we were like 'what is that for? Does anyone even use it?' In such cases we'd try not to include these settings, in an effort to avoid developing a massively bloated settings area that was impossible to navigate.
The problem is, the web is full of so much weird shit, and our settings area has inevitably grown over time. Like a flower. Or a mushroom. Or a guinea pig. Or a vine. Or a sponge. Or bigotry...or a banana.
URL Rewriting is one of those settings that is simply not required for 99.9%** of sites (**data may not actually be accurate). It is most useful when you have a site that appends parameters to URLs in order to track things like the click path. Typically these URLs are canonicalized to the 'non-parameterized' version, which really just completely fucks up your audit...unless you use URL rewriting.
You use URL Rewriting to strip parameters, so for example:
- https://example.com/category/?ut_path=megamenu
Can become:
- https://example.com/category/
And you end up with 'clean' URLs in your audit. To use URL Rewriting, in the Advanced Settings go to URLs -> URL Rewriting. Enter any parameters (or alternatively click to remove all parameters) and test your settings at the bottom by entering example URLs.
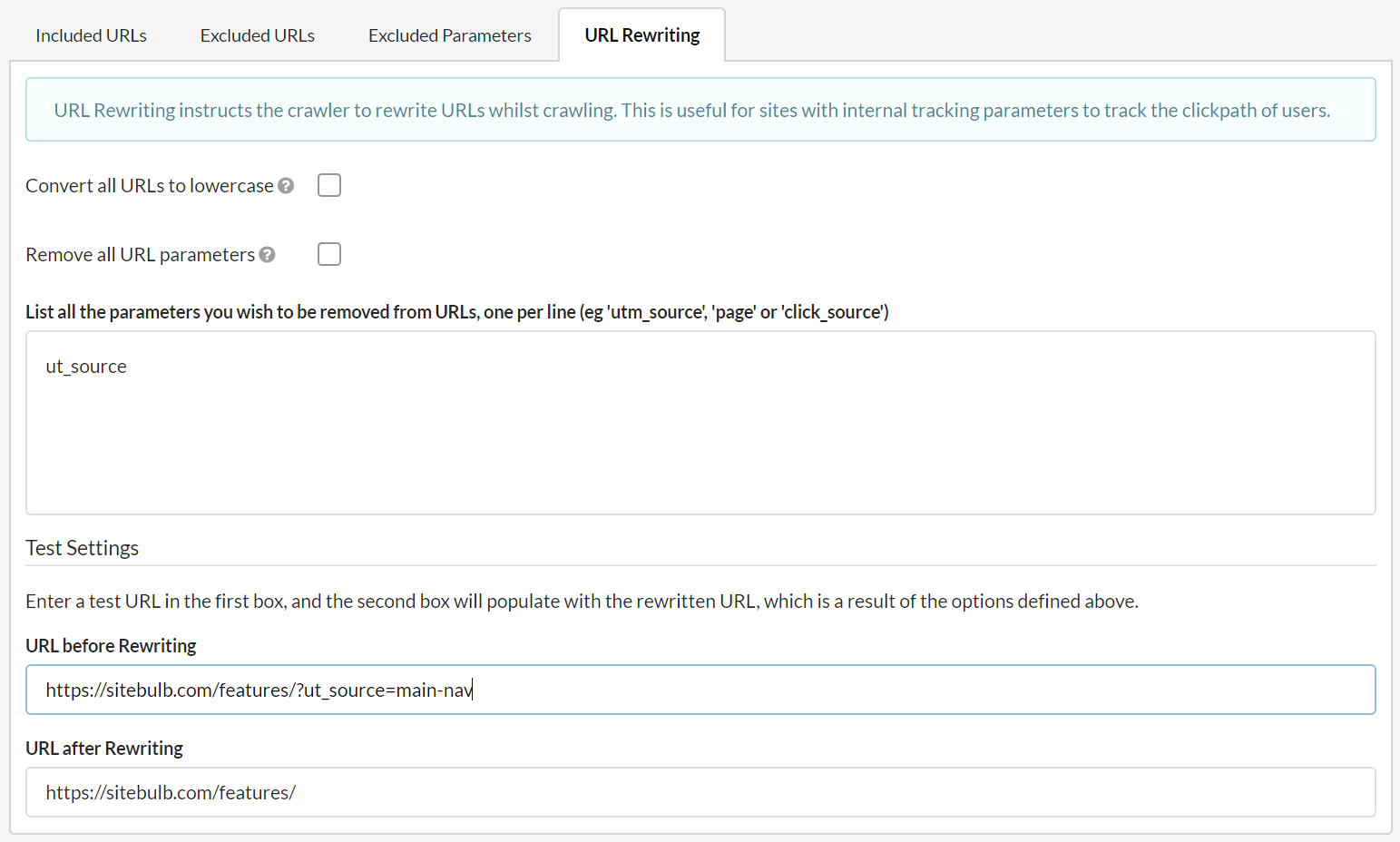
#5 You can now continue an audit that has been stopped early
You know what it's like, you're crawling a big site and it's taking ages because the site is massive, and you know you really should have done the audit several days earlier but you couldn't because you were busy on Twitter defending 'SEO isn't dead' and fell into an argument about the best Avenger and then got lost watching a bizarre boxing match, and then YouTube had you.
So you finally started it, but you haven't got time for the whole thing to complete, so you stop it early to see if you can work with half the data. Within minutes of looking at the audit, you realise your poor time management and easily distractable nature have cost you big... you really need to see the entire audit with all the data.
Well now you can! That's right, in anticipation of further ineptitude on your part, we've added the ability to undo that awful decision* to stop the audit early - you can continue any audits that have been stopped and still have some 'uncrawled' URLs. Simply press the green button.
 *Please note that Sitebulb only allows you to undo awful decisions relating to stopping crawls early, and makes no claims about any of the other horrendous decisions that inevitably pepper your everyday life.
*Please note that Sitebulb only allows you to undo awful decisions relating to stopping crawls early, and makes no claims about any of the other horrendous decisions that inevitably pepper your everyday life.
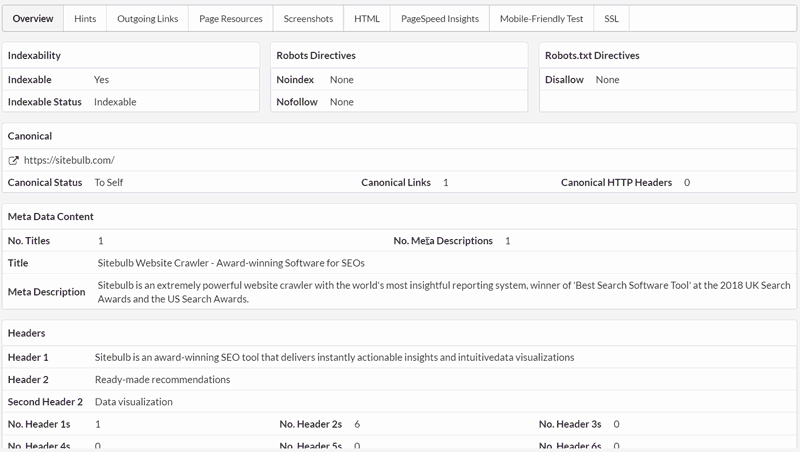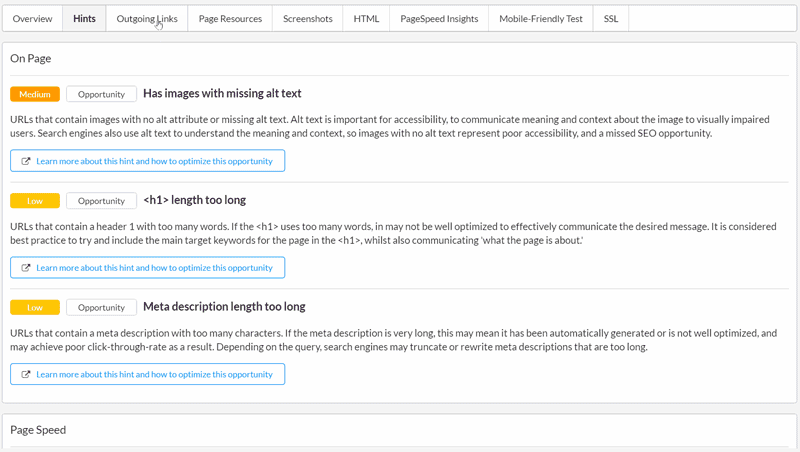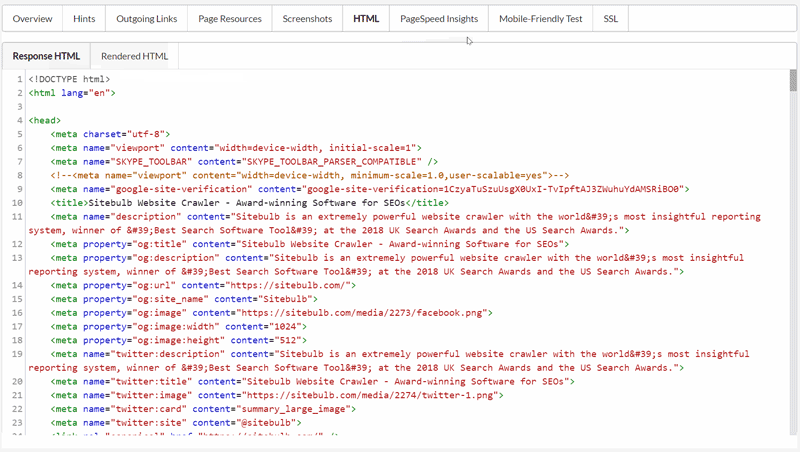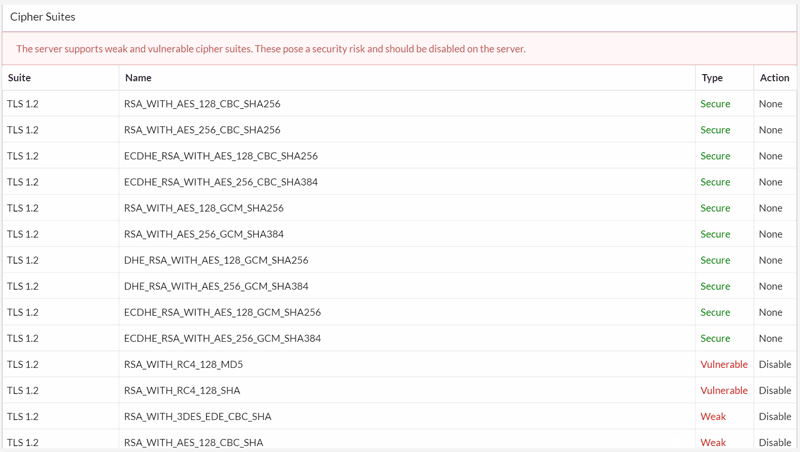
#6 Added sitewide hint for insecure SSL/TLS versions
I...don't know how to put this, but, security is kind of a big deal. Google have been pushing it, and will push it even further in 2020 with the release of Chome 81, when they will be removing support for legacy TLS versions.
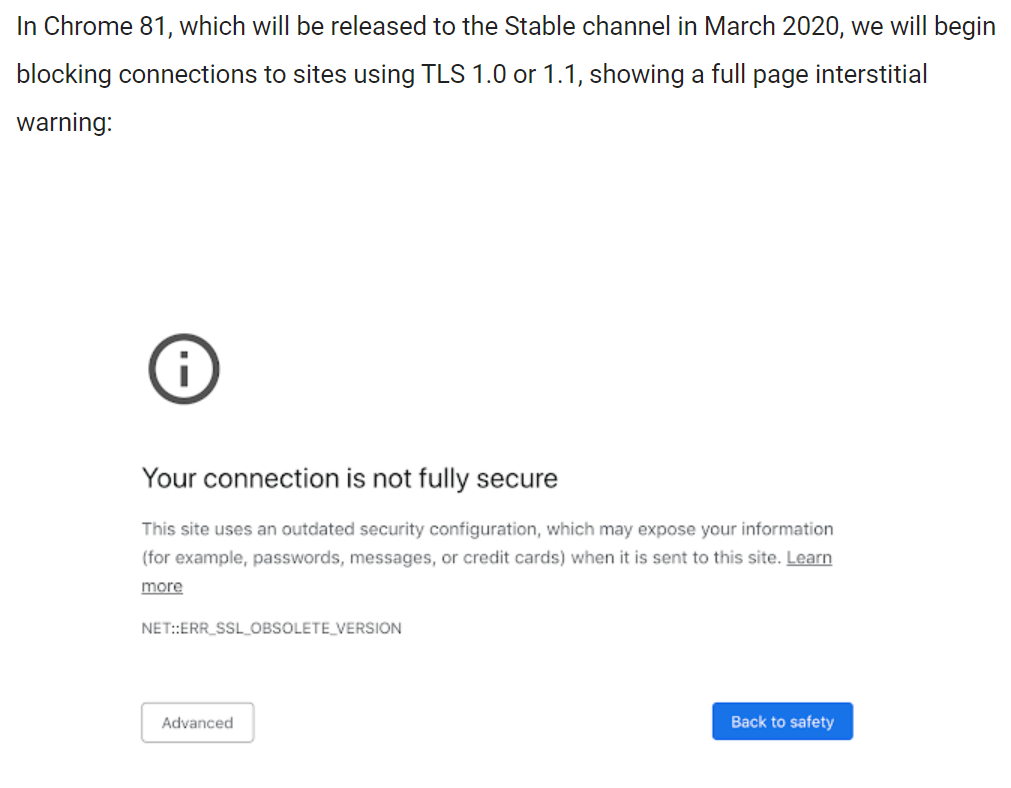
This is a big deal for two reasons, the second perhaps less obvious than the first:
- If you do not support modern TLS versions (v1.2/1.3), visitors browsing to your site using Chrome will see the above message, and will likely not continue on to your site.
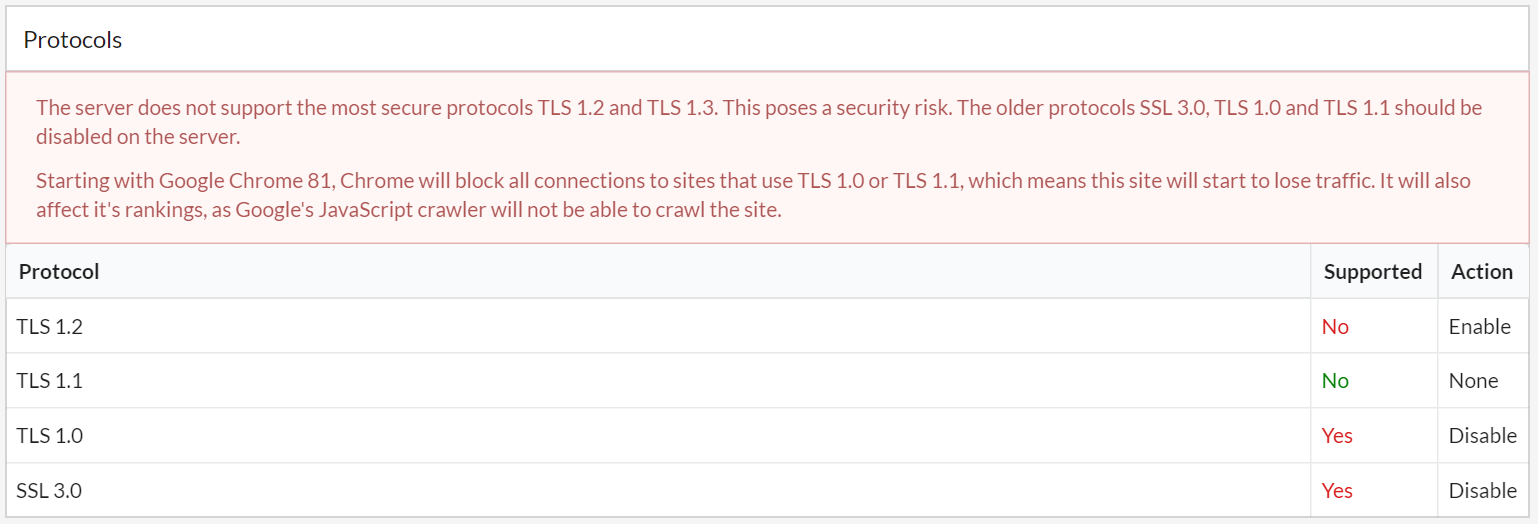
- Since Googlebot now uses an evergreen Chromium as its rendering engine, this also means that Googlebot will not be able to access your page content, and rankings may suffer.
To help ward off such nasties, Sitebulb will now warn you if a site has SSL or certificate issues, via the Security report:
To ensure you don't miss it, we've also added a new warning to the audit overview, which will take you directly to the report above:

If you want to learn more about how browser changes in 2020 will affect search, I suggest you check out Tom Anthony's recent SearchLove presentation.
#7 Improved pre-audit scanning for canonicals
With v3.0 we implemented a pre-audit check for when the start URL itself is canonicalized. But the implementation meant you had to abandon your current project and start a brand new one using the new URL. An inelegent solution indeed.
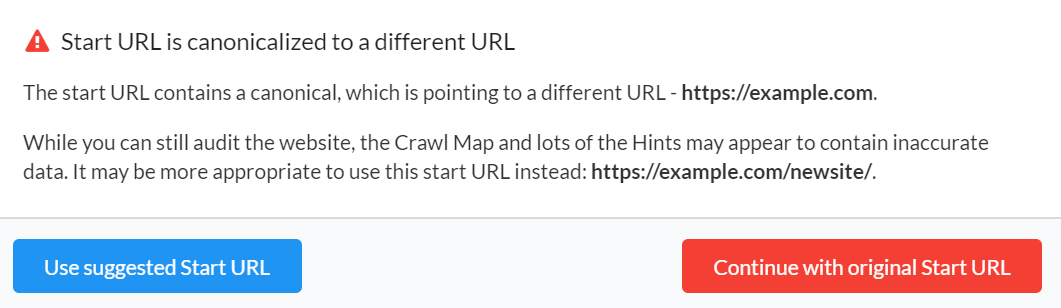
You can thank the brilliant Arnout Hellemans for this one. He paused between oysters to let us know how we only done half the job.
#8 Now storing second titles and second h1, plus first two h2s
We had a number of users request this - they wanted the additional data to better understand keyword targeting. You can get this data for any URL by viewing the URL Details -> On Page:
#9 Now storing second GA/GTM codes
Obvs this only comes into play when there are 2 Google Analytics (or Tag Manager) codes. But if this is the case on your site, you are now in luck, as Sitebulb will tell you the second code as well as the first. Lucky you!
#10 Now checking external links on URLs from XML Sitemap and URL List
Previously Sitebulb was set up so that it would only check external URLs if they were found via the crawler. Some users came to us wanting to do specific tasks, such as 'check broken external links only on Sitemap URLs' and Sitebulb could not deliver this data. Now it can.
#11 Added detection for lazy loading images
- Now checks image URLs that are found in the data-src attribute
- Now checks image URLs that are found in the data-srcset attribute
- Stops the reporting of hidden and offscreen images that are lazy loaded
- Stops the reporting of duplicate placeholder images
- New column in URL data called "No. Images Lazy Loaded"
I know what you're screaming..."Oh my god, this is great".
Fixes
- On the PDF reports, if you ticked 'SEO' this did not print anything. Curiously enough, this was not by design.
- Issue where h1s and titles were not always being correctly collected.
- Issue where some pages wer returning as 'HTML is empty' when there was blatantly HTML on the page.
- 'Live View' on the URL Details page was occasionally spilling outside the frame on first load.
- Click through to check the images referenced by the Hint 'Total combined image content size is too big (over 1MB)' would cause infinite spinny spinner of death.
- A slew of other shit that would be meaningless to almost everyone and utterly tedious to waste your time reading.
Version 3.0.11
Released on 4th November 2019
Before we get into the release notes proper, we have a small announcement to make. These Release Notes are now officially 'award-winning', having just scooped the Penguin Award for 'Best Software Release Notes.'
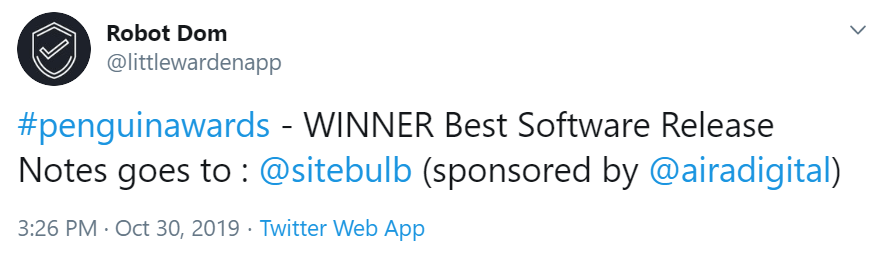
I'm not one for speeches, but...ahem:
"I'd like to thank all the fans who voted for Sitebulb's Release Notes, we couldn't have done it without you. You complete me. This award is for you! [PAUSE FOR ROUND OF APPLAUSE].
I'd also like to thank Mr Dom Hodgson, who runs the Penguin Awards single handedly. He doesn't do it for the fame, the glory, or the copious backhanders, he does it to support a charity close to his heart - Martin House - a hospice for children and young people with life-limiting conditions. In addition to the Penguin Awards, this year he also arranged a ridiculous sponsored race to Brighton via Paris in banged up old cars, and has ran approximately 27 half marathons dressed like a twat.
In a world where most of us think 'I could do a little more', this man just goes and does it. [WIPE TEAR AWAY]
He's a fucking hero. [POINT AT DOM TO STAND UP TO RAPTUROUS APPLAUSE]
Don't applaud him, he doesn't want your affirmation. Get your wallet out and give the man a well earned fucking donation." [MIC DROP]
Fixes
Image and keyword exports were coming out as blank spreadsheets
Development meeting transcript:
Me: "You know the new export we made for images that now includes every image reference and all the alt text, that everyone was asking us for?"
Gareth: "Yep. It's a good one isn't it? Do the people love it? Do they? Do they really love it? Oh I do so hope they love it."
Me: "Well..."
Gareth: "WHAT?? What is it? Don't do that. Just say it already."
Me: "It's completely broken."
Gareth: "What do you mean? No it's not, it's fine. We tested that thing to death."
Me:
Gareth: "Aw sheeeeeeeeeeeeeeet."
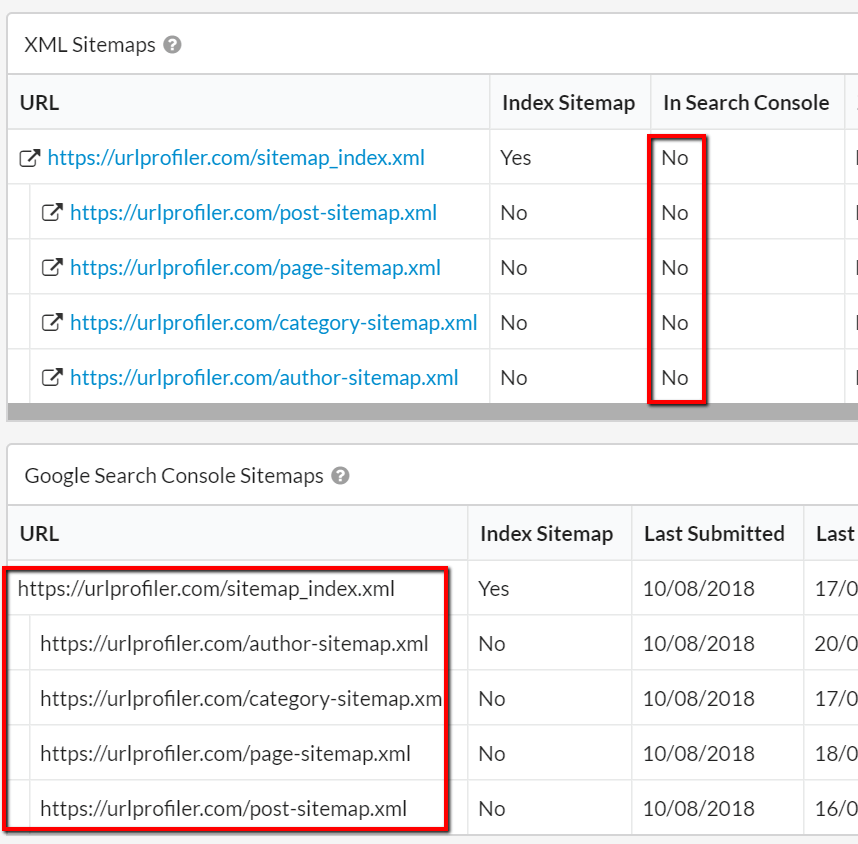
XML sitemaps reported as being 'not in GSC' when they blatently were
These two tables are vertically adjacent, yet they were completed contradictory. One says 'No these sitemaps are not in Google Search Console' and the other one says 'Check out all these Sitemaps I found in Google Search Console!'.
We cannot tolerate this kind of outright duplicity.
As a bonus sitemap fix, we also stopped that annoying message from showing all the time: "There were no submitted XML Sitemaps in that Google Search Console account." It would show even if you didn't connect Google Search Console in the first place!
James Bond mode looking a bit shit
Although everyone else has now copied our revolutionary 'dark mode', let it be known that we did it first. It is written.
Turns out that when we did our recent big update (version 3, pay attention) we mucked around with the UI quite a lot, and may have 'overlooked' some of the dark mode elements.
Example of said shit UI:
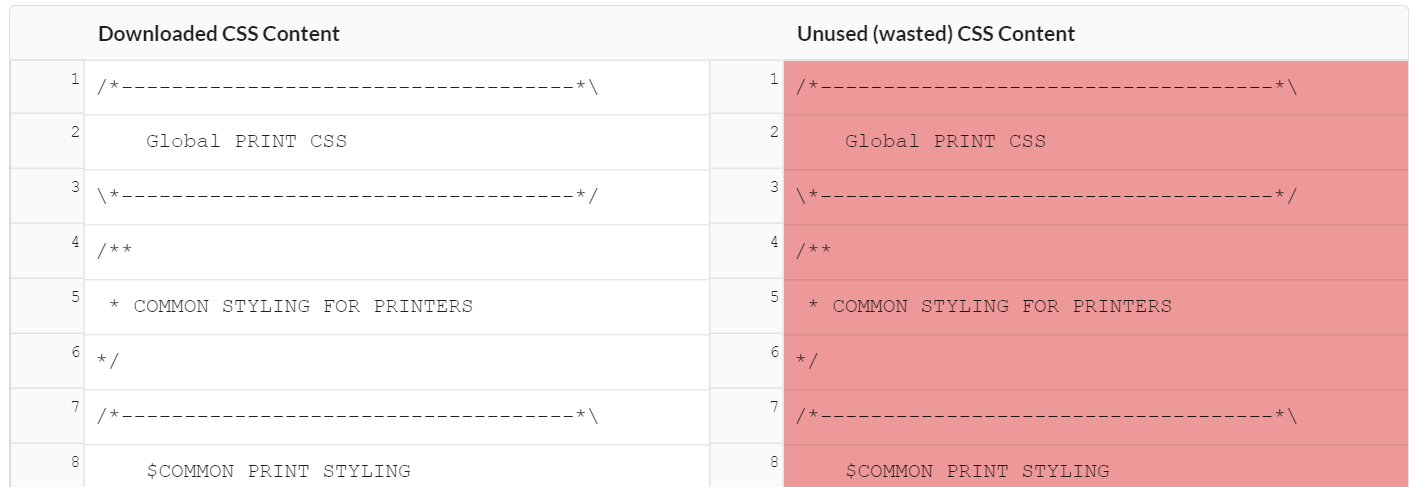
Code Coverage: When wastage was 100%, none of it was showing
This is in situations where the code coverage was reported as 100% wasted for a particular script or file. As in, the website was not using any of it at all. Sitebulb should be displaying this as everything white on the left, and everything red on the right, per the image below. Previously it was showing both as white, which is the equivalent of 0% wastage instead of 100%. Doh!
International Hint not firing - Mismatched hreflang and HTML lang declarations
This Hint was not firing, when it should have been, but it is now. That is all.
Version 3.0.10
Released on 18th October 2019
Updates
Scoring system tweaked
We had some feedback from a number of users that they thought our scoring system was a bit off.
Specifically they felt:
- Overall audit score and SEO score was too high
- Pagespeed score was too low (and impossible to get high)
During beta I actually had noticed that the SEO score was always high, but I figured that's just because I'm wicked good at SEO (it turns out the score was just rewarding inadequacy, much like most of western politics...).
So we re-visited our scoring algorithm and changed some of the weightings, the scores should now better represent what the audit uncovered. With existing audits, the new scores will retroactively be applied on the fly - so you don't need to crawl any sites again.
We also tweaked the colour scheme so you don't get a nice happy green unless the score is over 90, which makes it easier to spot areas that require attention.
Fixes
Export broken links button not working on Mac
This is the button I'm referring to, in the SEO report:
Now, I have in the past opined that Mac users are doing life wrong.
This tweet received 24 likes, so it's fair to say the internet agrees. However, in this instance, it appears that the shoddy Mac operating system and underpowered hardware are not to blame. We just forgot to wire the export up.
URLs with encoded characters reported as having no HTML
It's like, just because it has %20 in the URL, Sitebulb pretended it didn't matter. We did not raise you to be a fascist, Sitebulb.
Wildly insignificant search bug that has basically no impact to anyone
User complaint email:
"On 'All Hints', if you are searching for a Hint but make a typo you have to delete the whole phrase rather than being able to delete the part you've put in wrong."
Just don't make typos in the first place and it isn't even a problem, amirite?
EDIT: I deliberately made this fix anonymous so as not to shame the pedant that reported it. I guess I should not be surprised that he insisted I credit him: Adam Brown, a really tremendous, tremendous SEO (unfortunately he was unable to secure the singular version of his vanity domain, let's all pretend we didn't spot the 's' at the end).
All Hints -> Filtering Hints was not hiding empty sections
This is one of those bugs that sounds like a load of bollocks when you read the email. Then you look at the screenshot and agree that it looks wank and needs to be fixed immediately.
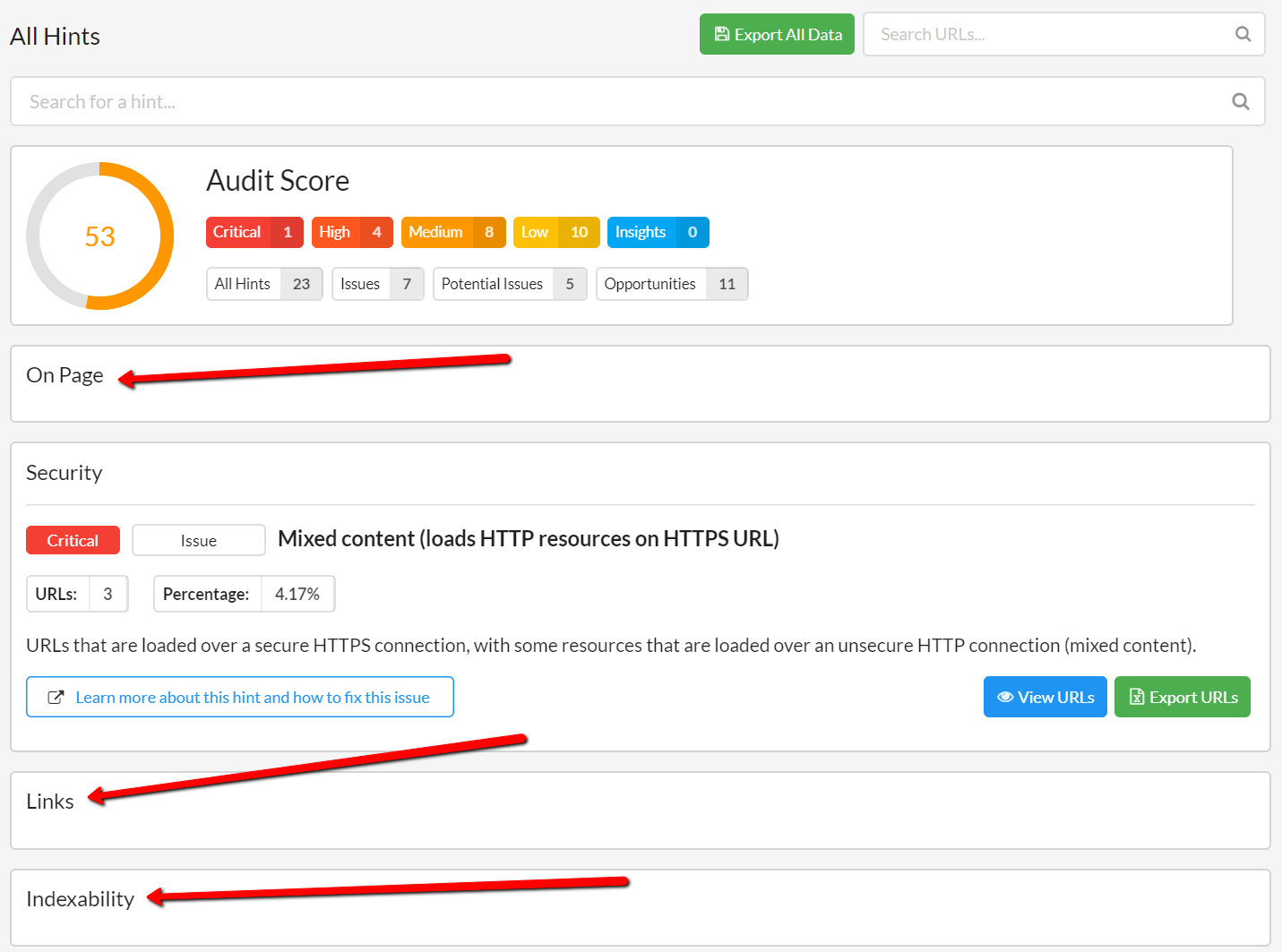
Told you.
SEO reports -> the domain resolution test results copy was using the same copy as the Not found(404) test results
This one was of course deliberate, purely as a test to make sure you were paying attention.
Uncrawled URLs formatting was whack
We changed this export to CSV format a few months back, and fucked up our separators:
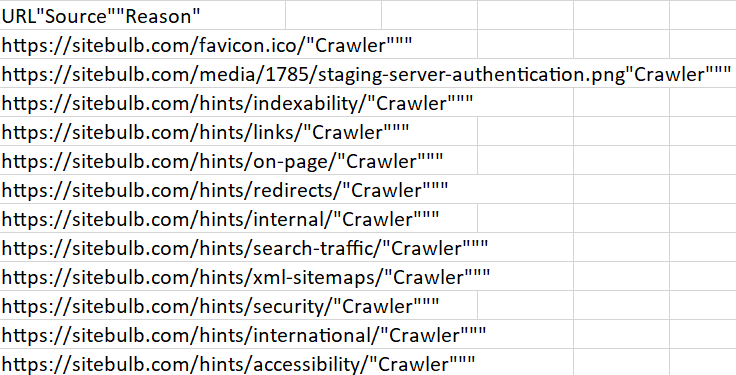
No one actually reported this issue, which maybe makes me think that folks don't know it exists. So, for the record, the Uncrawled URLs export is on the Audit Overview:
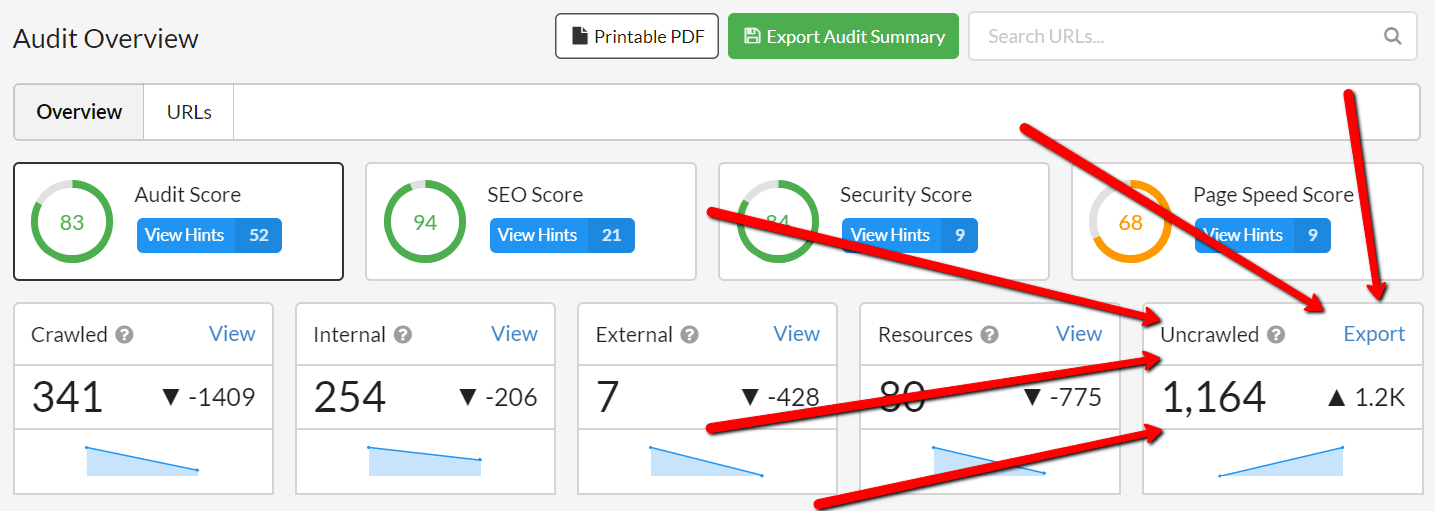
It's useful when you have stopped an audit early, or hit a crawl limit, and want to investigate all the URLs that were left in the queue. Good for diagnosis if you are watching the crawl progress and seeing Sitebulb go round in circles crawling a bunch of bullshit pages that will take forever to complete.
Technologies not showing up all the time
If you crawl using the Chrome Crawler, Sitebulb very helpfully shows the different web technologies found across the site.

Pretty nifty, eh? Well, not so much if we don't bother to show you them, as we had be doing - unless you happened to tick 'Page Speed, Mobile Friendly & Front-end' in the audit setup. Doh!
Version 3.0.9
Released on 14th October 2019
Fixes
macOS Catalina users can use Sitebulb again
In a deliberate effort to twart us, Apple decided to release a macOS update ('Catalina') right at the same time as we released v3.0. At a point in time when we should have been popping champagne, we were instead receiving reports of this...
Mother. Fucker.
Apple have included new security measures in Catalina, which meant that software from 3rd party developers (such as ourselves) had to get our software tested (for malware and suchlike) and 'notarized' by Apple when we built it.
In our frenzy to get v3.0 out the door, we forgot that we needed to do this for Catalina.
I know what you're thinking, all Mac users should really just upgrade to Windows, but in an effort to be more inclusive, we've done as Apple wanted and done the notarizing thing in this version.
macOS Catalina users no longer get storage message
Noticing a theme developing yet? Another security feature Apple added in Catalina is the partition of System files on the hard disk. This meant that the handy 'low disk' space message that Sitebulb shows when you have low disk space... would also show even when you don't have low disk space.

In order to determine whether it needs to show this warning, Sitebulb checks to see how much space is left. Since this partition change it Catalina, it had been looking in the wrong place.
By the way, if you think that we've been fucked over by this update, check out what happens when you view data in Excel:
That's right, backwards and upside down.
Let me know if you want recommendations on where to buy a nice new shiny Windows PC.
Version 3.0.8
Released on 9th October 2019
This update has been a looooong time coming, as a result, a ton of stuff has changed.
We have a cool 'version 3' page which explains all the features succinctly. This page is the verbose (wordy) version of the same thing. So if you want to know all the details, read on below.
If you just want to get the update already, download using the links above.
Alternatively, if you want to learn about the new features but only have only 1 minute and 47 seconds to spare, watch the video:
Hint Priorities & Scores
Up to now, we've only differentiated Hints as being 'Issue' or 'Advisory', and for a lot of our users, that wasn't helpful enough.
Now, every Hint is classified as either Critical, High, Medium, Low or 'Insight'. They are also cross-classified as either Issue, Potential Issue or Opportunity.
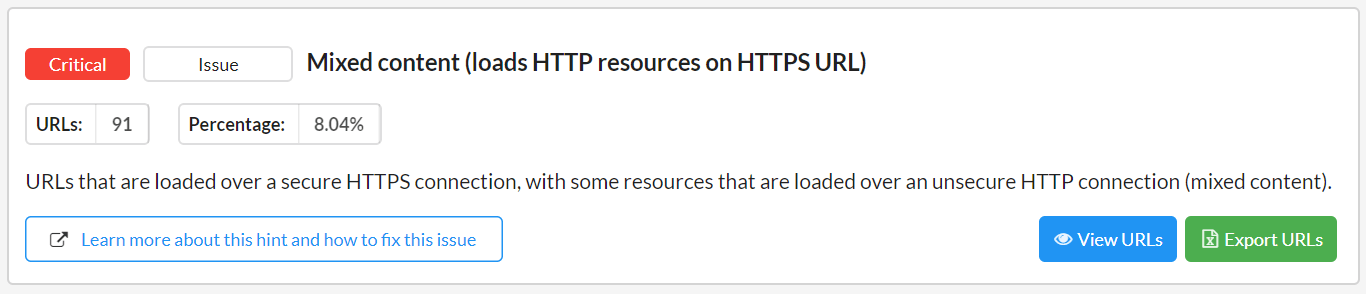
As you can see in the visual presentation, we are also now showing the Hint description and Learn More link by default, along with a new datapoint: 'Percentage', which basically means 'Percentage of URLs affected.'
The idea is that you can use the classifiers along with the percentage of URLs affected to gauge how important each Hint is, with a bit more context than previously.
Take this example above - it's a Critical Issue and applies to 8% of URLs on the site. So it's not an absolute disaster, but you would still recommend that the issue is fixed as a pretty high priority (of course it also depends on the state of the rest of the audit!).
Using these individual Hint scores and the percentage of URLs affected, we have also now come up with a score for each report, to show you how well optimised a particular section is. Or not, as may be the case:
As you would expect, the score gets more negatively affected if you have lots of 'Critical' or 'High' level issues, whereas 'Medium' and 'Low' have a much smaller impact on the score.
In addition to a score for each individual report, there is also an Overall Audit Score, an SEO Score, a Security Score and a Page Speed Score. These are all visible on the Audit Overview:
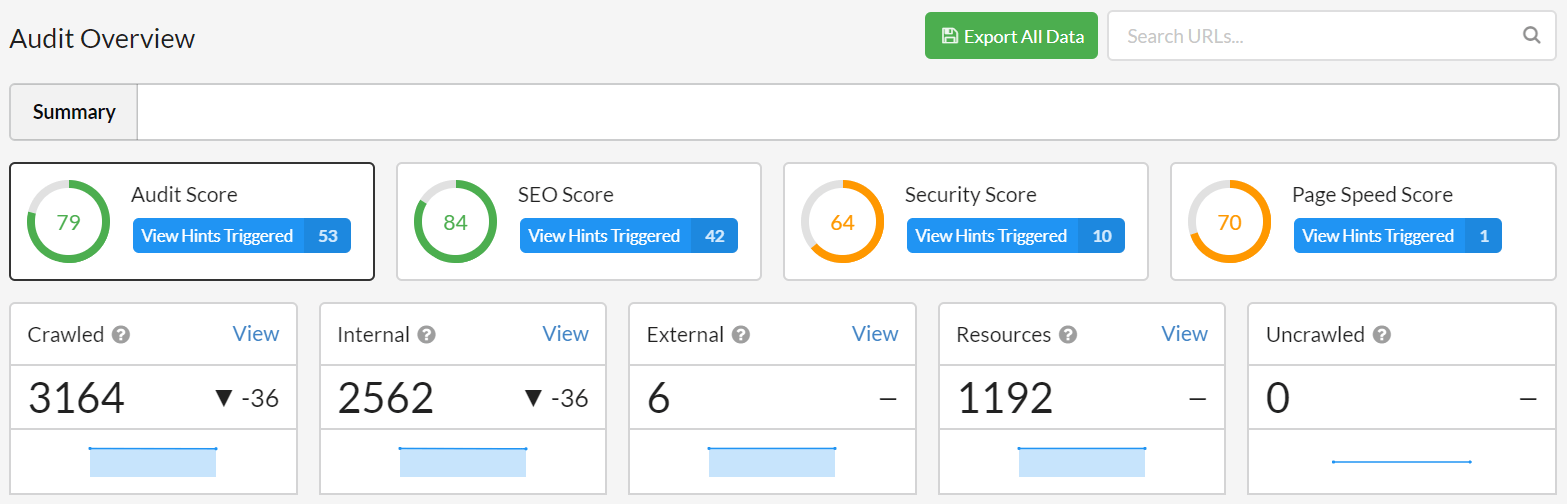
These give a high level picture of how well the site performed during the audit. They are, however, conditional on the selections made when setting up the Project. So if you run the exact same audit twice in a row, you will get a like-for-like comparison, but if you change some of the audit options, this would not end up like-for-like, and may get skewed up or down.
The audit scores relate to:
- Audit Score - this is based on every Hint/report that was analysed across the entire audit..
- SEO Score - this only relates to the SEO reports (Internal, Links, Indexability, Redirects, On Page and Duplicate Content).
- Security Score - this is just based on the Security report.
- Page Speed Score - this is just based on the Page Speed report.
The idea of the scores is to provide metrics which give you an overall impression of the state of the website, and may be the sort of thing you can report to C-levels, or on a summary report.
The idea of the Hint scoring is to help surface the most important issues, so you know what should be investigated first, and to help build a set of recommendations for your clients when doing site audits.
Please have a play with the new scoring and let us know what you think.
Improved Reporting
To go along with the new Hint priorities and scoring, we have also made the reporting options much more flexible.
For a start, you can now produce a PDF report for any single section, by clicking the Printable PDF button in the top right:
You can also customise which data will be shown on the report, so you can set up the reports exactly as you want them:
As you would expect, we've also improved the main audit reporting, which is now super flexible in terms of what data options are displayed, but also which reports are included:
This gives you the freedom to produce exactly the audit report you want for your specific use case.
We are sure you guys will have some further ideas for how this system could be improved further, so please let us know what you think!
New audit change history
With all the new, rich data we have added to the Hints, the old trendlines were causing the interface to look very cluttered. So we removed the trendlines from Hints, and introduced a new pop-over modal, which actually provides a lot more clarity on changes from one audit to the next.
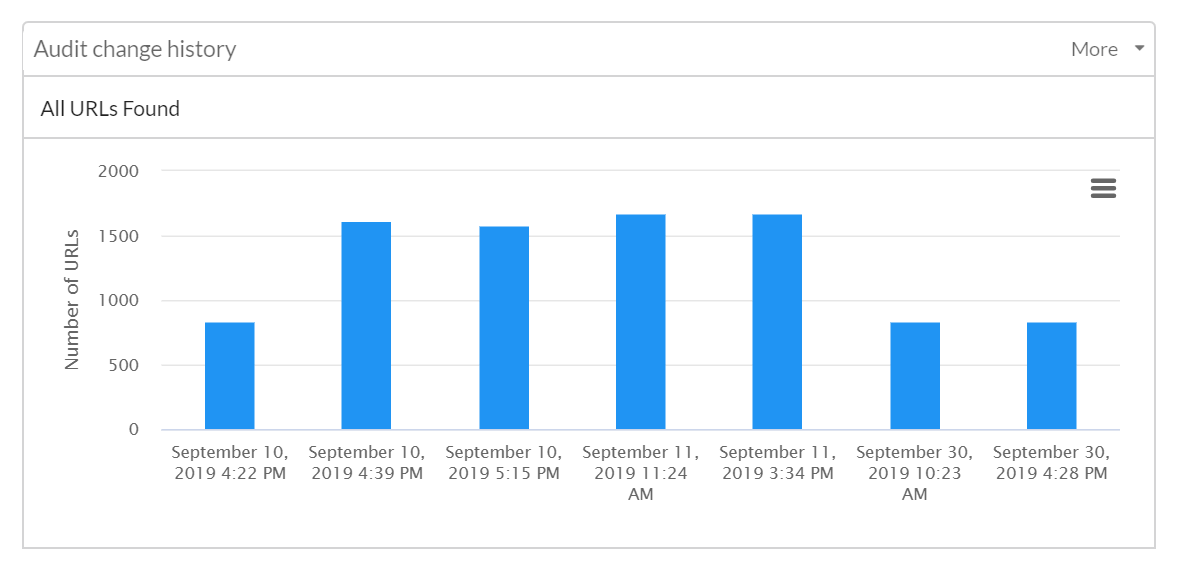
You can bring up this chart for any Hint, by clicking the URLs box:
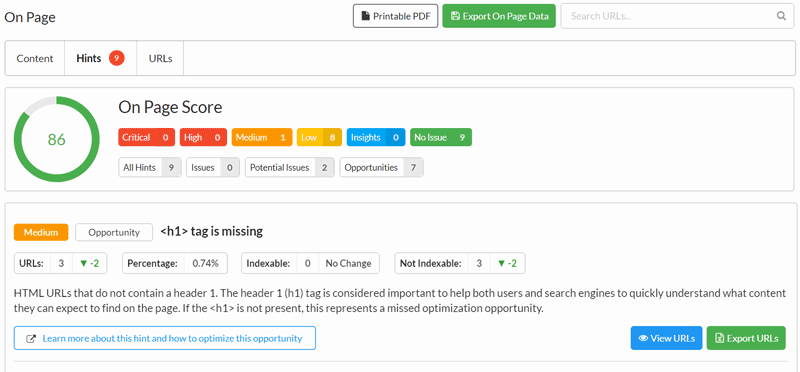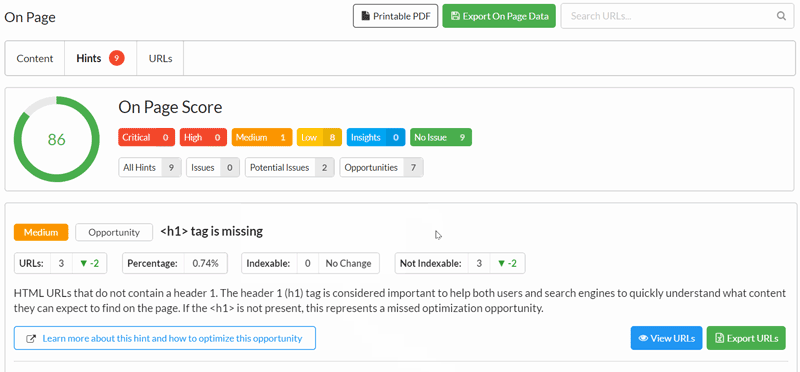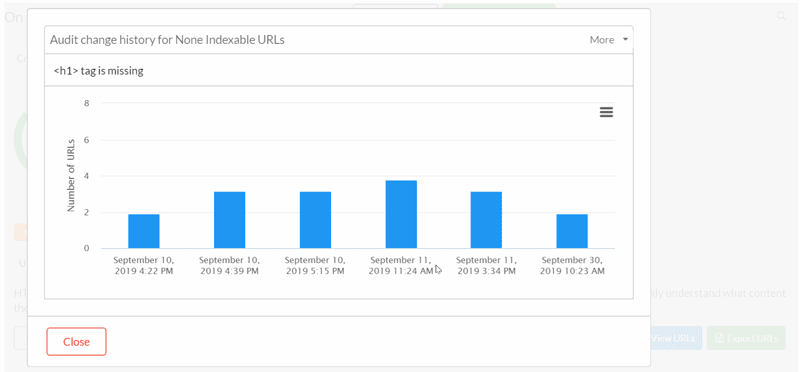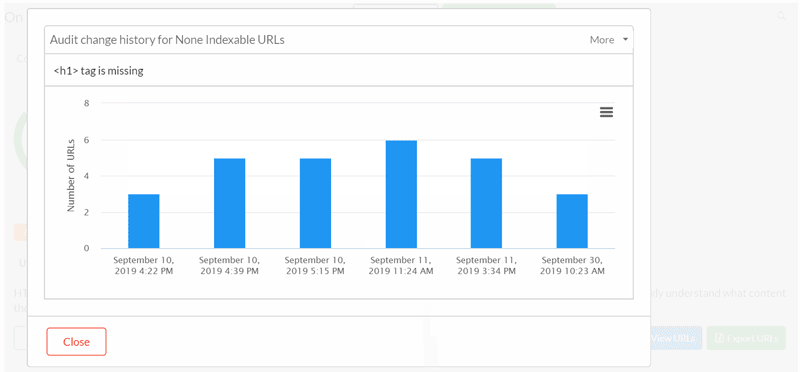
You can also trigger the history window by clicking any trendline (which are still present throughout the rest of the audit, just no longer on Hints).
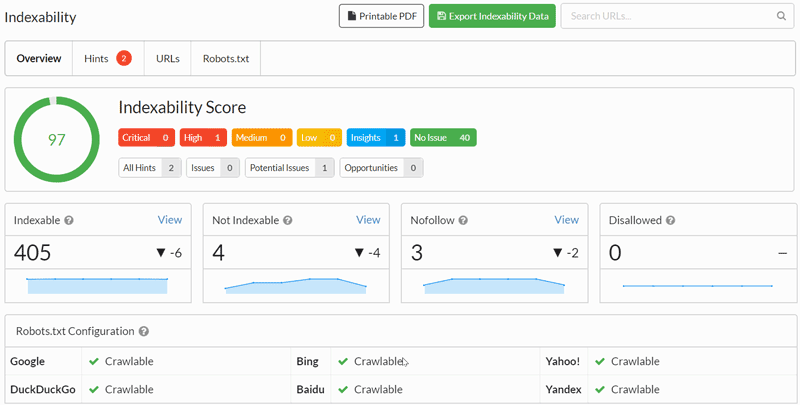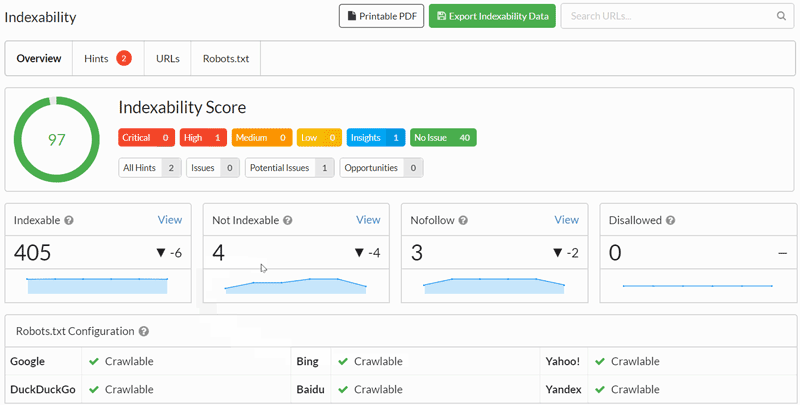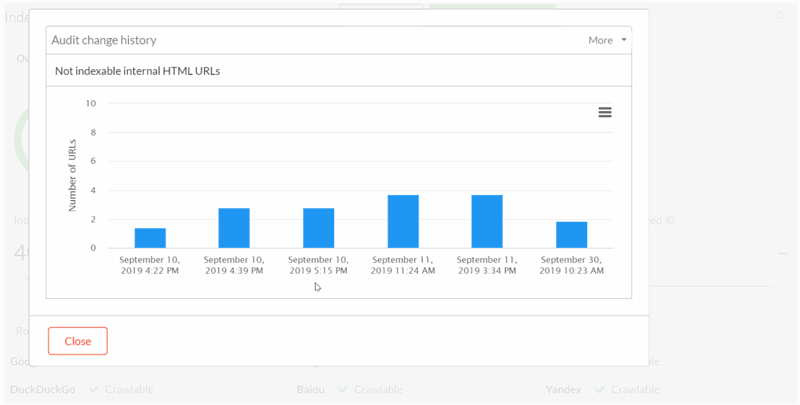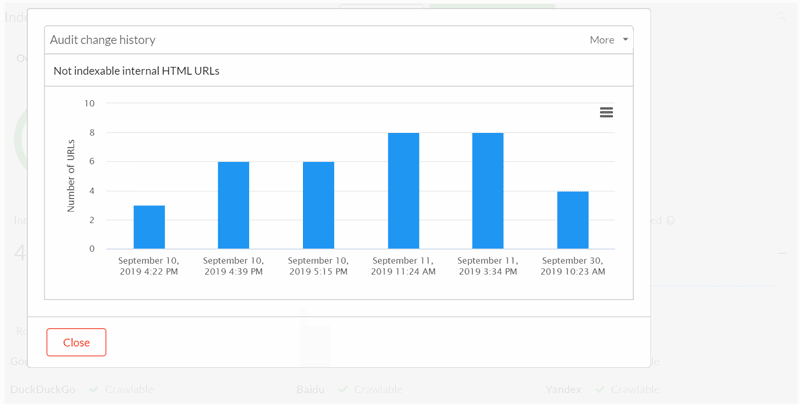
Right click context menu
Right click on any row and up pops a little context menu, which allows you to do specific things related to that URL. Quick, convenient and familiar.
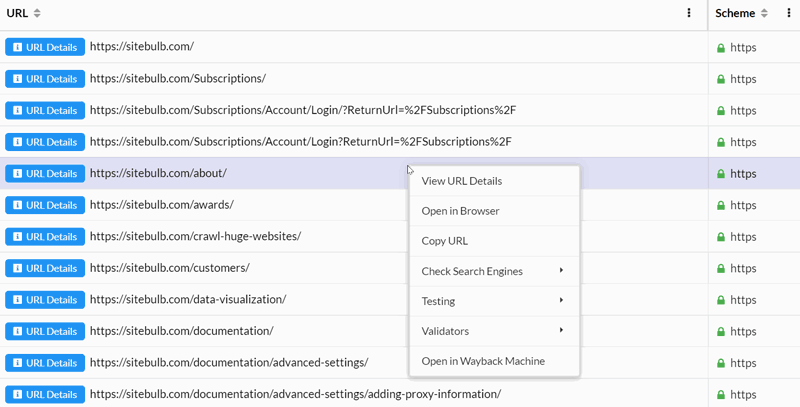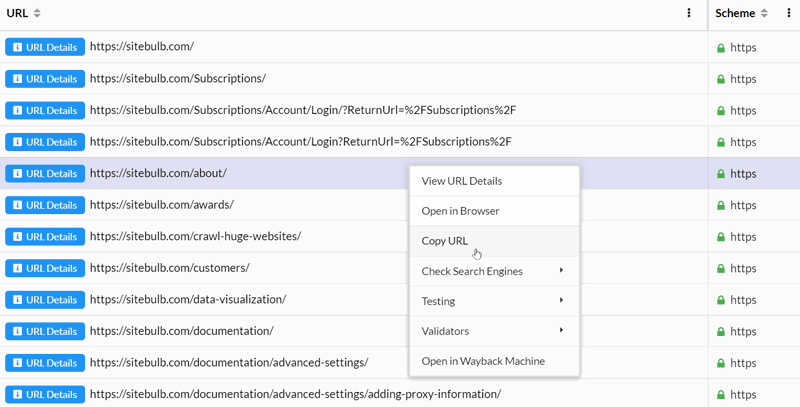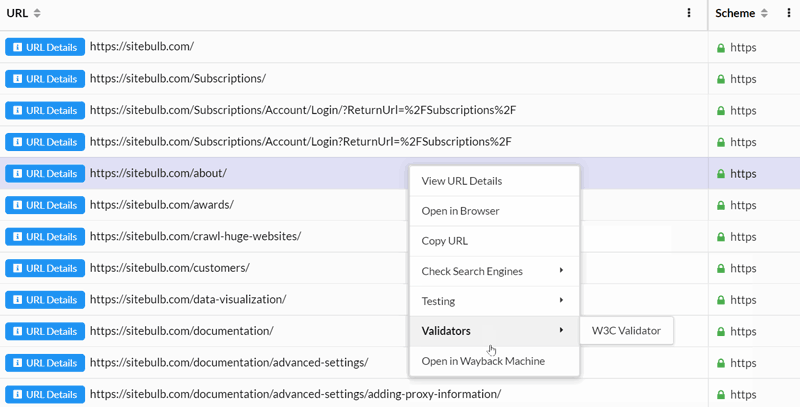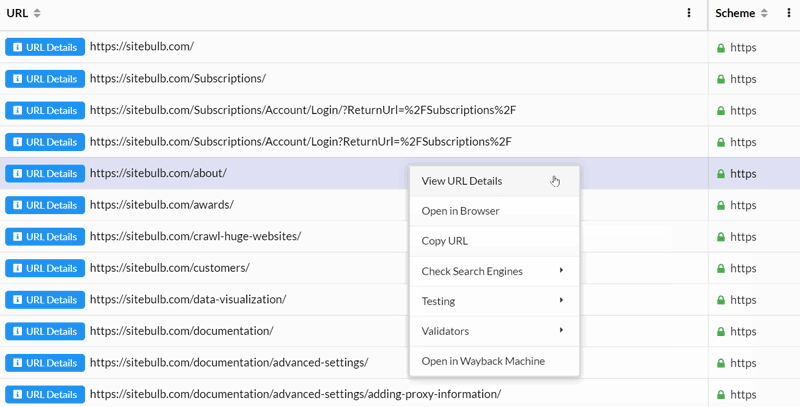
Retry failed URLs
Lots of you have asked for this one - if you've fixed a bunch of 404s, you can now request that Sitebulb recrawl just these 'failed' URLs, and update the report accordingly. This is particularly useful when you're working with bigger sites, and recrawling the entire site is a pain in the backside.
As is our wont, we haven't simply built a solution to 'respider' a single URL - instead, at a push of a button, you can recrawl every broken URL found during an audit. Not only that, but Sitebulb will rebuild all the reports and update the original audit, taking into account any data found on URLs that are now status 200, which were previously broken.
To make the magic happen, head to the Overview and hit the Re-Audit Failed URLs button.
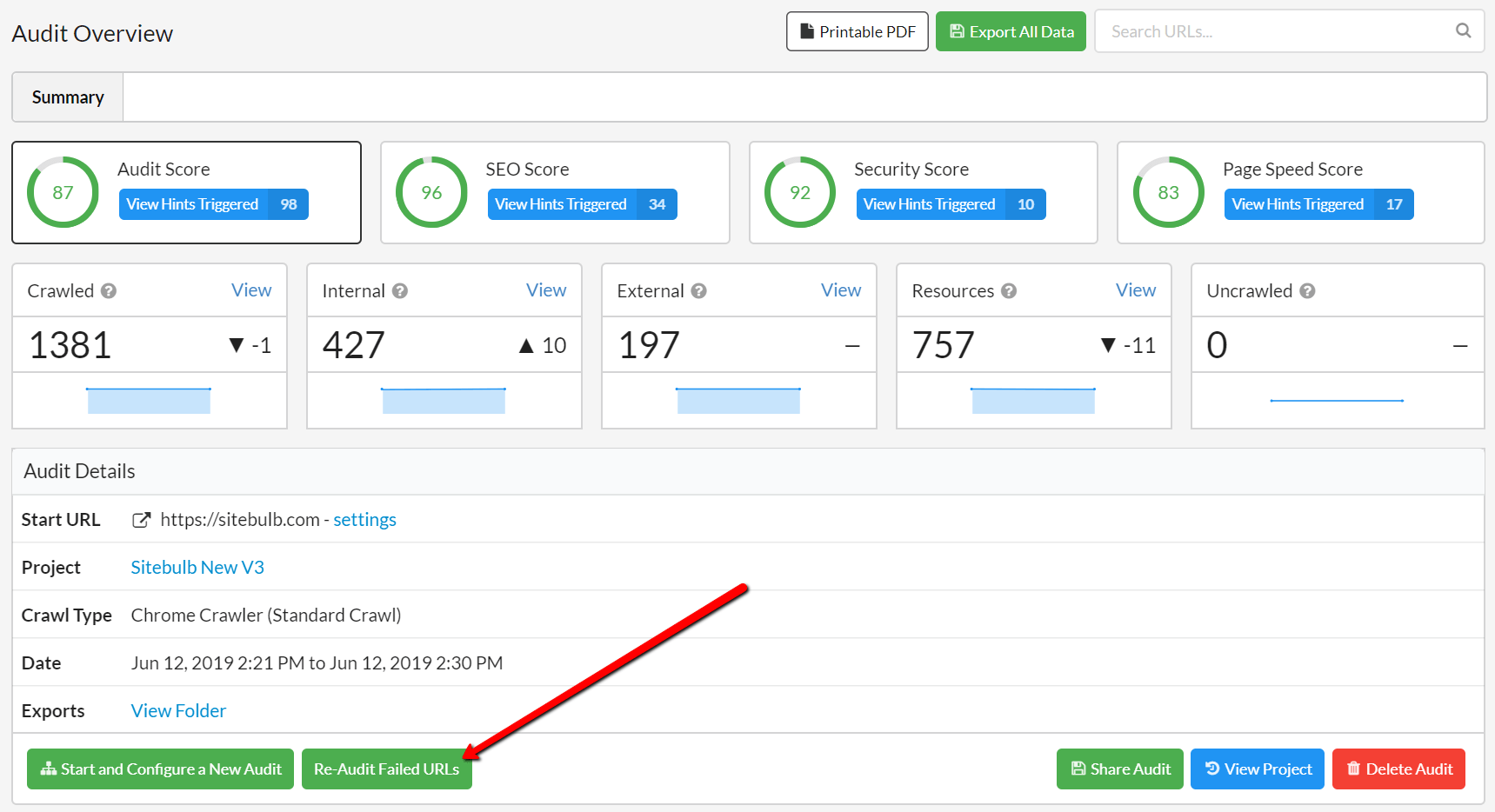
Once you confirm to go ahead with this, you will see the familiar crawl progress screen, but only the failed URLs will be scheduled and crawled.
Once this completes crawling, it will rebuild all the reports, and bring you back to your original audit - but now, any URLs that are no longer broken will not be reported as broken, and all the other data, reports and Hints will be updated in lock-step: On Page, Indexability, Duplicate Content etc...
Crawl password protected websites
Sitebulb has always supported HTTP authentication, which means that most staging sites have been accessible to the crawler. However, sites which included a login form on the page were not accessible, and Sitebulb could not crawl them. Until now.
Now, if a site requires a login, all you need to do is tick this box:
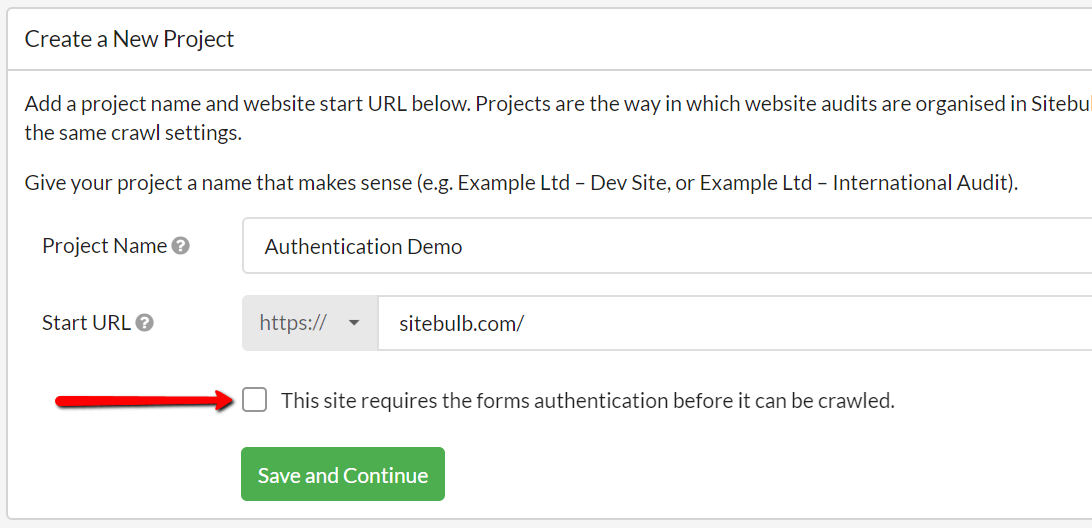
This will open up a modal window which loads in the start URL and render the page. You then need to enter the username and password on the page, and click Add Authentication at the bottom right.
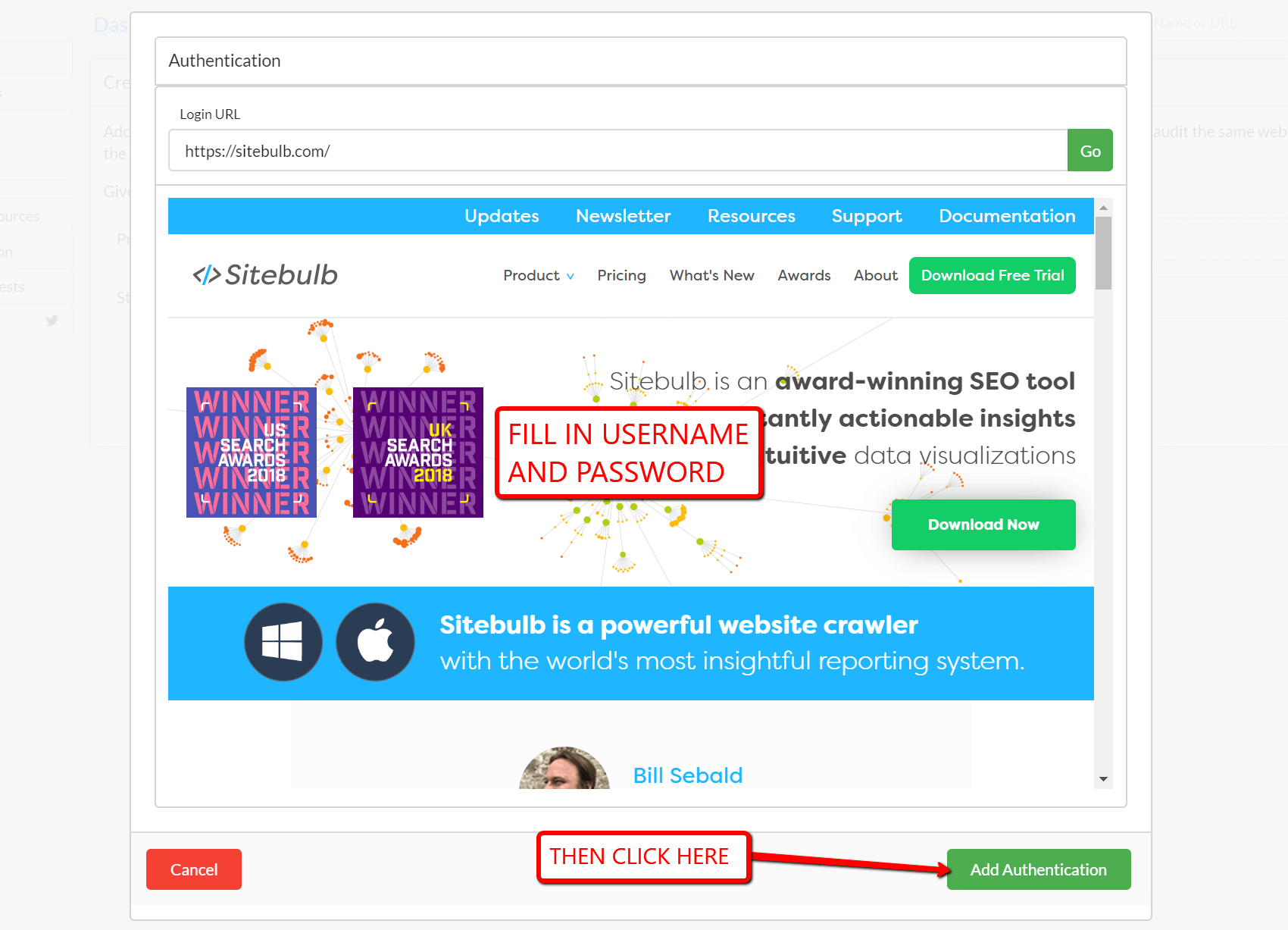
This will trigger the pre-audit as normal, and Sitebulb will be able to crawl the website. You will need to re-authenticate when performing a re-audit, or an action like pause/resume, as the authentication cookies will have expired.
Important: Make sure you do not login with admin credentials, as Sitebulb can and will follow any links it finds - including 'log out', 'delete', etc...
Identify similar content
A new addition to the 'duplicate content' report (also a new Hint), this could also be referred to as 'near duplicate content', and it identifies situations where most of the HTML content on the pages is the same - without the content being identical.
This will trigger for any internal, indexable URL which has big chunks of text content in the
that are identical to another indexable URL.
Some of Sitebulb Hints pages on our website actually trigger the Hint - when Hints themselves are checking for substantially similar things, the 'Learn More' pages inevitably end up very similar as well. Consider the Hints pages below for 'DOM depth exceeds recommended 32 nodes deep' and 'DOM width exceeds recommended 60 nodes wide', these pages get flagged as 'Similar Content', and you can see from the image below that they have large chunks of content that is exactly the same:
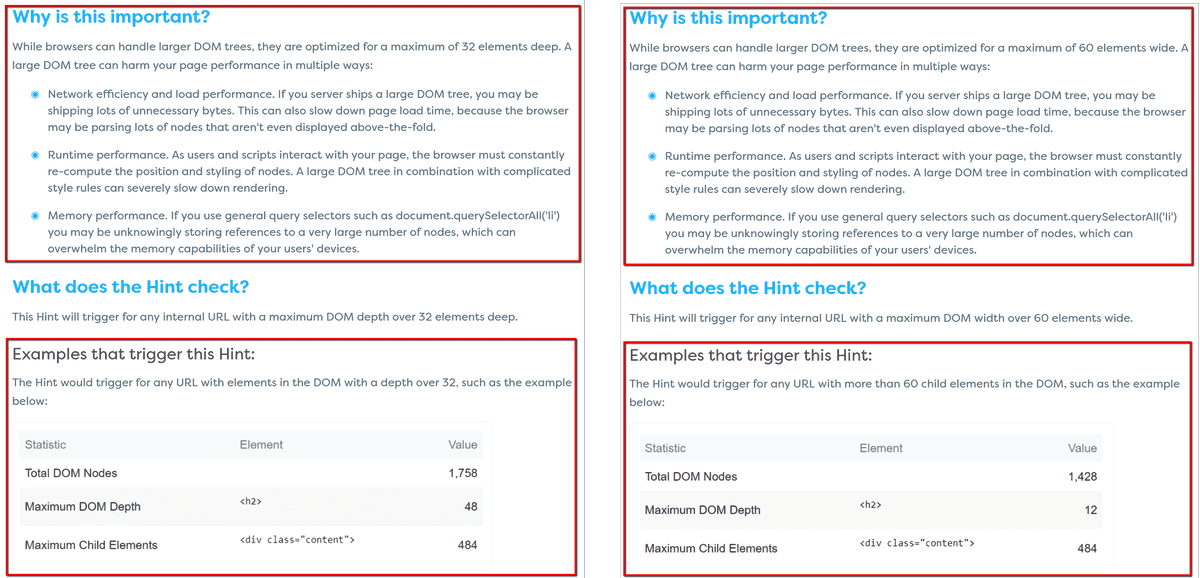
Performance Improvements
We've made some changes to how data is accessed, which has made the UI a lot snappier. We've also adjusted all of the processes while the crawl is in progress, which massively reduces the overhead in terms of CPU and RAM.
Most significantly, perhaps, we've found a way to allows users to make use of more threads when crawling. And if you've been following along on our journey so far, more threads = faster crawling.
At this stage, you can access double the number of threads you could previously. So where 4 logical processors previously restricted you to 4 threads, you can now access as many as 8.
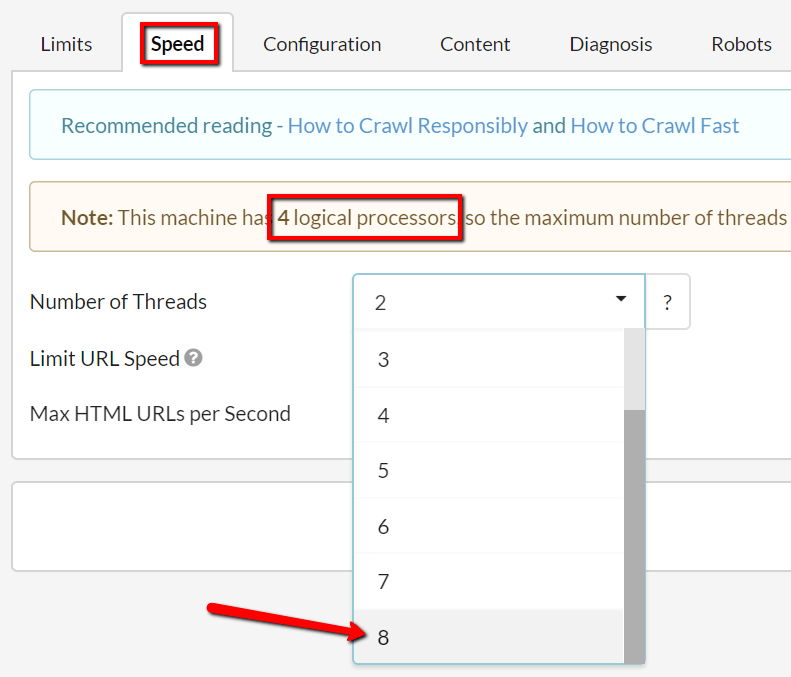
Note that this does not over-ride the default settings, but go to Advanced Settings -> Speed to make the change yourself.
Evergreen Chromium
At Google I/O this year, they announced that from now on they will be using an 'evergreen Chromium' as their renderer.
Here is how they describe what this means:
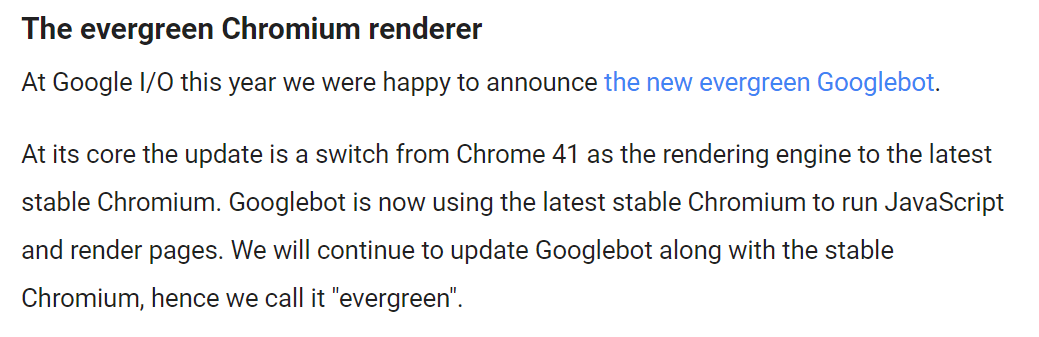
Since Sitebulb already uses Chromium to render for JavaScript crawling (we have historically called this our 'Chrome Crawler') we will now follow Google's lead and keep Chromium up to date and 'evergreen.'
This means that when you use Sitebulb and crawl with the Chromium Crawler, you can be sure it reflects exactly what Googlebot sees.
Exports overhaul
A bunch of folks asked us to change the Excel exports to CSVs to make them more accessible in other programs, so we did - over 95% of all exports are now in CSV format. This also enabled us to offer a couple of link exports that we've been asked for loads:
#1 Export all internal links
In the Links report, you can now export every link relationship into CSV format. We couldn't do this previously because we had no easy way to handle link exports that exceed Excel's capabilities (around ~1 million rows).
But now we can, so now you can enjoy ALL the data!
#2 Export all broken links
For much the same reasons as above, we did not allow you previously to export every broken link relationship. You can do this too now, via a section on the new 'SEO' report.
Some other cool shit
I can't be bothered to write full descriptions of these smaller things, so you'll have to make do with bullet points instead:
- On the URL Details, there is a new 'Crawl Path' tab, so you can see exactly how Sitebulb found a particular URL.
- When a URL is part of a redirect chain, the full chain will be listed on the URL Details page.
Archives
Access the archives of Sitebulb's Release Notes, to explore the development of this precocious young upstart:
- The Beta Notes (January-September 2017)
- Version 1 (September 2017 - March 2018)
- Version 2 (April 2018 - May 2019)