

 Patrick Hathaway
Patrick Hathaway
Most people working in digital marketing are familiar with the concept of structured data by now. It is reasonably straightforward to understand the basic concepts, and there are numerous structured data generators that can provide a head-start when actually writing the code.
This article is about taking the next step, beyond disparate structured data entities and towards one of the true goals of The Semantic Web: linked data.
"The Semantic Web isn't just about putting data on the web. It is about making links, so that a person or machine can explore the web of data. With linked data, when you have some of it, you can find other, related, data."
Tim Berners-Lee, Linked Data - Design Issues
As we will see, node identifiers are a fundamental part of making data interconnected.
What is a node?
We can't throw terms like 'node identifier' around without explaining what the language means, so we'll take a brief detour and return to first principles: graph theory.
We are already familiar with graphs as part of common digital marketing parlance - Google's Knowledge Graph, or Facebook's Open Graph, for example.
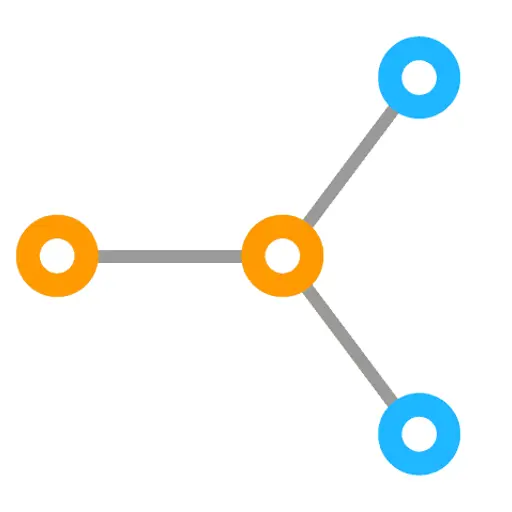
Graph theory is a mathematical structure used to describe the relationship between objects. In graph theory, graphs are made up of nodes (also known as 'vertices') which are connected by edges (also known as 'links').
One of the simplest graphs we can create shows two nodes connected by an edge:

In this example, the arrow indicates that this is a directed graph, rather than an undirected graph, which you get from a simple line with no arrowhead.
The directed edge means that the edge has an orientation associated with it. When it comes to structured data, we use directed graphs to describe relationships. For example:

So the 'Patrick Hathaway' (moi!) node is linked to the Sitebulb node via the 'founder' relationship (co-founder really, don't tell Gareth I said that!).
Let's look at a simple example of structured data that we might find on a web page like this:
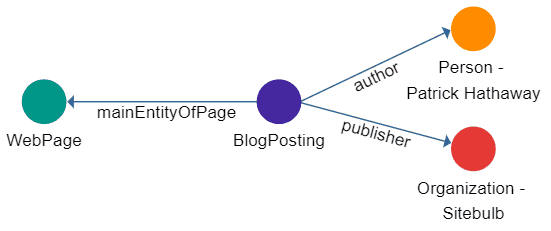
Here, we have named the entities and relationships in a way that has a consistent meaning through a shared vocabulary (Schema.org);
- BlogPosting is linked to WebPage via the mainEntityofPage relationship.
- BlogPosting is linked to the Organization 'Sitebulb' via the publisher relationship.
- BlogPosting is linked to the Person 'Patrick Hathaway' via the author relationship.
So the nodes represent entities, and the directed edges describe the relationship between the entities.
While this graphical representation is helpful for us mere humans to understand what's going on, the important thing is that this data can be mapped to a matrix in a machine-readable format.
And, by using node identifiers, we can interconnect this data with other structured data on the web.
Now that we understand what a node is in terms of structured data, we can move onto node identifiers themselves.
What is a node identifier?
Simply put, a node identifier is a unique 'name' for an entity, which is publicly accessible and can be looked up or linked to.
"Entities need to be uniquely identifiable. There must be a one to-one correspondence between each entity identifier (ID) and the (real-world or fictional) object it represents (i.e., within a given entity catalog; the same entity may exist under different identifiers in other catalogs)."
Krisztian Balog, Entity-Oriented Search
By using node identifiers, we can reference multiple, otherwise disparate, blocks of structured markup, so that they are linked together such that a machine can understand the context of the relationship.
There are 3 major formats for Schema.org: JSON-LD, Microdata and RDFa, and the node identifier attribute is different for each;
- JSON-LD - @id
- Microdata - itemid
- RDFA - resource
Google has put it's weight behind JSON-LD as the recommended notation, and it is fast becoming the 'de facto', so the examples we explore below will focus on JSON-LD - however it is important to note that the same functionality can be achieved with the other formats.
The 'value' of the @id property is typically a URI (Uniform Resource Identifier) - a URL with a fragment identifier - for example https://example.com#website. The URL identifies the page, and the fragment identifier (hash mark #) points to the subordinate resource.
Node identifier property in JSON-LD
JSON-LD is a JavaScript notation embedded in a <script> tag, within the page's <head> or <body>. JSON stands for JavaScript Object Notation and the LD bit stands for Linked Data.
The node identifier property in JSON-LD is @id, so let's take a look at it in a simple example:
For simplicity, we've included minimal properties here, we could of course include an address, logo, a telephone number, even a fax number (as if we're still in the mid-90s...). And we've used @id to identify the Organization node, along with all its associated properties.
Now, if we wanted to reference the Organization again, we can make use of this @id, thus establishing a link between the two nodes. Let's say we wanted to mark up our page as a BlogPosting, and set the Sitebulb Organization as the publisher;
As we can see, the only property we needed to use for publisher was the @id. This establishes a meaningful relationship between the Organization as the publisher of the BlogPosting, where all the properties of the Organization are understood.
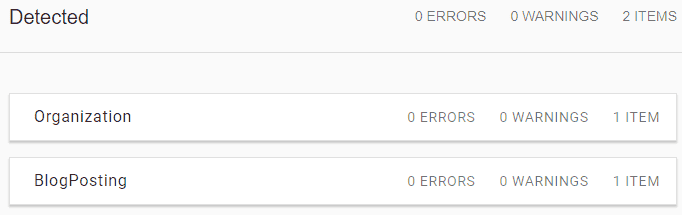
We can use Google's Structured Data Testing Tool to demonstrate how Google interprets the code with and without the @id.
First, let's try the markup without using @id, which recognizes 2 distinct, individual items:
Then, we have the markup with the @id, like in the example above, which recognizes 1 single connected item;
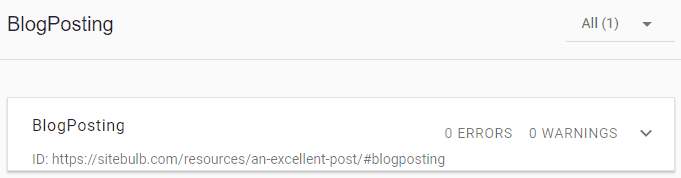
We could have established the same meaning by nesting all the Organization properties underneath publisher, but this would have caused unnecessary duplication of code.
The benefits of using node identifiers
Now we understand what a node identifier is and how it can be used, we're going to explore why we should be using node identifiers.
In bullet point format, node identifiers allow us to;
- Avoid duplicating data
- Unambiguously identify a node
- Enable external references
We'll unpack these a little further:
Avoid duplicating data
We have a ready-made example of this, in the section above. By using the @id, we did not need to repeat all the Organization properties again when we called it via publisher. This is of course convenient, as it is more efficient in terms of processing the code.
The other way you can assign the relationship context between multiple entities on a page is by properly nesting the structured data markup. However, deeply nested markup can be hard to read (e.g. if you need to fix validation issues), and sometimes it is by necessity that you end up with multiple disparate blocks of markup, and using @id allows you to stitch them all together.
Unambiguously identify a node
SO much of structured data is to do with disambiguation. With normal HTML data, we spend a long time on keyword research and on-page SEO to help enable search engines to 'take a good guess' at the meaning of our content. Structured data works almost the opposite to this, it gives us an opportunity to be extremely specific about how we describe our content.
And a node identifier is an exemplar of this. It allows us to say, for instance, "I have a LocalBusiness with the same business name (e.g. 'Patrick's Teabags') in two different locations. Here is the unique reference for the one in Sheffield, rather than the one in London." Although they may have lots of shared properties (e.g. website, social handles) they also have lots of different ones (e.g. address, phone number).
The node identifier allows us to uniquely identify each, without ambiguity.
Side-story
My family (on my mother's side - the Joyces) heralds from the west coast of Ireland (hence 'Patrick'...).
Last summer we were over there for a Joyce family reunion, which was great craic (look it up). The Joyce family name is common in these parts, and Catholic first-naming-conventions are not exactly known for being... idiosyncratic (i.e. Bible or bust).
One afternoon, we were sat around drinking tea, and a couple of my relatives were having a conversation, where they performed disambiguation, Irish-style:
Tom: Michael is coming down later.
Mary: Michael O'Brien? Will he stay for some tea?
Tom: Michael Joyce
Mary: Michael Joyce Galway?
Tom: No, Michael Joyce Dublin
Mary: Ah, well it'll be nice to see him. He'll stay for some tea, so he will.
Enable external references
I've buried the lede to some degree, as this is the real biggie. This is the thing that really enables Linked Data.
By creating node identifiers for the entities we mark up on a single web page, we can then cross-reference these same entities by referencing the node identifier on other pages on the same website.
Moreover, by utilising node identifiers, we enable other website owners to establish a relationship with entities we have described on our site. This enhances disambiguation - any two websites can identify a thing as being the same. But it also provides that link between disparate sets of semantic data, so a machine can truly explore a 'web' of data.
And this bit is the whole entire point of Linked Data in the first place - an application or machine can start at one piece of structured data, then follow links to other pieces of structured data that are hosted on other sites across the web.
Reprising our example from earlier, let's say I write a guest blog post for our friends at Traffic Think Tank. If I mark up my own author data using @id on our site, they could, theoretically, cross-link my author data on their blog post to the author data on a post on this website, by also referencing my @id.
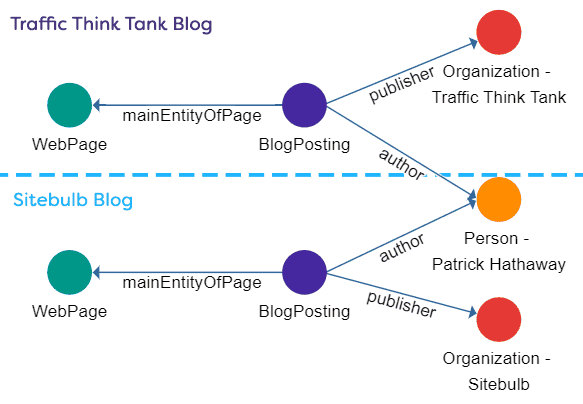
This allows Traffic Think Tank to unambiguously identify the writer as the same person who writes for Sitebulb. And it allows machines to follow the link and develop a clear understanding not only that the two webpages are linked, but also how they are linked. Well, that is the theory anyway...
Current limitations
As we have seen, referencing a node identifier on another webpage can establish a clear, contextual relationship between the entities described on two different web pages. Since we have used a vocabulary to describe the relationship, this is more powerful than a 'normal' <a href> link between two pages.
So Google must be using this right?
Well, as far as we can tell right now, they are not. They understand the utilisation of node identifiers on different chunks of structured data within the same page, but they don't yet offer cross-page support.
This might be because the practice of using node identifiers has yet to receive widespread adoption, so they can't yet trust the signal.
Google have at least taken a baby step in this direction, including a recommendation to use @id to link together individual items on a page, which appeared on their General structured data guidelines page in July 2020:
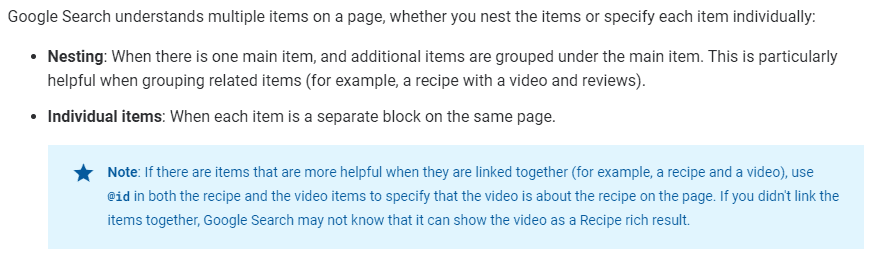
If there is even a chance that cross-page @id linking becomes something that Google support, it is almost definitely worth implementing.
However, right now, the upshot is that in order to pass Google Search Feature validation, we do need to include all relevant chunks of markup on a page - we cannot just reference @ids on other pages and expect Google to follow the link and piece it all together themselves. At least not yet.
How to use node identifiers
Much of the article up to this point has been theoretical, so in this section we will address some practical concerns.
Adding node identifiers to structured data
The most common method to create node identifiers is to create URIs by appending a fragment at the end of a URL, as per the examples already explored in this post.
This method fits our needs as the URI acts as the unique identifier of the resource, and the URL itself (without the fragment) contains markup which describes the resource.
So a computer system could discover a relationship defined via a node identifier (e.g. https://sitebulb.com/about/#organization), then follow this link to discover the node, and all the properties associated with the node.
In a practical example, considering markup on a fictional page https://sitebulb.com/great-post/, we could use @id to define a node identifier for every different @type on the page:
As we can see, BlogPosting and WebPage use the URL itself for the @id (+ corresponding fragments) whereas Person, Organization and ImageObject all use different URLs (+ fragments) for the identifier. The important thing is that the URL used for each is the URL which describes the resource. In some cases these will be the URL you are placing the markup on (e.g. for WebPage) and in others these will be the same URL across the whole site, regardless of which page you are placing the markup (e.g. for Organization).
How to create node identifiers
A common way to get started with writing Schema.org markup is to use one of the many structured data markup generators that exist across the web. However, these almost always do not include a node identifier.
Using a sensible and consistent rubric, we can design a system to add it manually ourselves, similar to the example above.
- Start with the URL of the page we are adding the @type to.
- Add the # fragment for the @type, hyphenate or remove spaces, and use a consistent case (@ids are case sensitive!).
Now we have set this up, this is our globally unique identifier for this object on this page, and across the site. Then, if we need to reference this entity on other pages, we should utilize the same @id consistently across the website.
Example, we want to set up Organization markup on our about page:
- We start with the 'about' URL: https://sitebulb.com/about/
- We add the # fragment for the @type, in lower case: https://sitebulb.com/about/#organization
Now, if I write a blog post and want to reference this Organization as the publisher, I would do it using:
"@id": "https://sitebulb.com/about/#organization"To really take advantage of the structured data opportunity, we should be looking to roll this out at scale across the entire website, utilizing consistent naming conventions for the node identifiers in the process.
How this works in practice will differ from site to site, however Yoast have done an excellent job documenting a comprehensive specification for building the Schema graphs that they use in their WordPress SEO plugin, which could absolutely be applied to sites not running on WordPress (in particular, this page explains their methodology for constructing node identifier fragments).
Using node identifiers to differentiate the page about the thing
One of the other ways that node identifiers can help in terms of disambiguation is that they allow us to differentiate between the 'actual thing' and the 'page about the thing'. This is more easily understood with an example, so let's take a look at some of the markup on Apple's homepage.
Apple define the organization;
...then they define the website;
...then they define the webpage;
Note that these all have the name 'Apple', however they are 3 separate 'thing's, and they all have unique @ids. This means we can make statements that unambiguously reference exactly the thing we want to reference:
- I like Apple (the organization)
- I like Apple (the website)
- I like Apple (the homepage web page)
Each of these statements has a fundamentally different meaning, and through the use of node identifiers we are able to explicitly define which meaning is intended. As such, it is considered good practice to include markup which allows us to differentiate between the page and the thing.
Using absolute vs relative URIs
It is entirely valid to utilise relative URIs on pages where the @id will use the URL of the page itself. For example:
In many cases, this may turn out to be the path of least resistance to getting it implemented, and there is nothing inherently wrong with it. However, all the same arguments stand for instead using absolute URLs that we have for normal anchor links and canonicals etc...
Quite simply, with absolute URIs, there is less room for error. Error in terms of internal implementation, but also in terms of how external sites might reference the node, which we want to be as consistent as possible.
Should we use node identifiers for literally everything?
As with most things in SEO...'it depends.'
While there is no downside to marking up every entity you describe with a unique node identifier, it may not be necessary for all forms of markup on every website. For example, a breadcrumb is a thing we would never need to reference from a different page. Reviews would be similar - the review applies only to one entity on one page, so would not need to be called externally. However, identifying all the exceptions is possibly more hassle than just building out a system that marks up everything.
Conclusion
The primary intention of this article is to educate; to act as a bridge between 'putting structured data on a page' to 'developing an interconnected graph of linked data.' Whilst the concept is certainly non-trivial, and takes a little while to get your head around, the implementation itself is not overwhelmingly complex.
The secondary goal of this article is to convince you that using node identifiers in a consistent and pervasive manner is entirely the right course of action, and something you should be implementing right away.
Linked data is about more than just gaining some review stars in the search results. It's about presenting your data to machines in a meaningful way, so they can understand not just what your content is, but also how it relates to other content - and other known entities - both on the internet and in the real world.
Whether you like it or not, Google, along with the other digital giants, will be trying to figure this stuff out for themselves anyway. Implementing linked data gives you the opportunity to control the narrative. I suggest you take it.
Examples & resources
- An SEO’s Guide to Writing Structured Data (JSON-LD) - A really fantastic primer for structured data, which also explains how @id works in practice.
- Annotated JSON-LD Structured Data Examples - Structured data examples with code (and heavy use of @id).
- Classy Schema Visualisation Tool - Build and visualise your own Schema.org markup in graph format.
- Linked Data - Design Issues - Some of the original thinking on Linked Data, by the main man Tim Berners-Lee himself.

Patrick spends most of his time trying to keep the documentation up to speed with Gareth's non-stop development. When he's not doing that, he can usually be found abusing Sitebulb customers in his beloved release notes.
Related Articles
 When Website Migrations Go Wrong: A Practical Guide to Disaster Recovery
When Website Migrations Go Wrong: A Practical Guide to Disaster Recovery

 Beyond Keywords: Designing Empathy-Based Ecommerce Architectures
Beyond Keywords: Designing Empathy-Based Ecommerce Architectures

 Sh*t, The Migration Is in 2 Days/Weeks: Mark Williams-Cook's Emergency Protocol
Sh*t, The Migration Is in 2 Days/Weeks: Mark Williams-Cook's Emergency Protocol
 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.