
The Brand-First Technical Audit: Why Your Entity Health Is a Technical SEO Problem
 David Carrasco Pamies
David Carrasco Pamies
Published June 16, 2026
This week, we welcome back David Carrasco Pamies who shows how the crawl you already run surfaces brand and entity-health problems most audits miss. He reveals seven crawl signals that map to entity damage, which Sitebulb reports highlight them, and what to do to fix them.
Picture two meetings happening in the same company on the same afternoon. In one, a technical SEO is working through a few hundred crawl issues: redirect chains, a cluster of soft 404s, some render-blocking scripts. In the other, the marketing team is trying to work out why ChatGPT keeps recommending a competitor when someone asks for the best provider in their category, and why the brand's own name pulls up a half-empty Knowledge Panel with a logo from two rebrands ago.
Those two rooms rarely talk to each other. The crawl belongs to one team, the brand conversation to another, and the working assumption on both sides is that they are looking at separate problems.
I'm less sure about that than I used to be.
When Ahrefs looked at 75,000 brands to see what correlated with appearing in Google's AI Overviews, the strongest signal was not backlinks and not domain rating. It was branded web mentions, at a correlation of 0.664, against 0.218 for backlinks. Correlation is not causation, and Ahrefs say so themselves. But the direction is hard to ignore: the things that move AI visibility look a lot more like "is this a recognised entity" than "how many links point at this page."
The audit does not change. The questions you ask of it do. The same crawl that surfaces a broken redirect also surfaces a broken entity signal, once you know to look for it.
Contents:
A coherence problem hiding in plain sight
Those broken entity signals usually share a root. I keep coming back to the same name for it: most sites carry identity debt. It is what accumulates when that gap stays open for years: every decision the brand made was a signal, and the inconsistent ones turned into noise that search and AI systems now read back. Like technical debt, it accrues quietly. A rebrand here, an abandoned social profile there, a Schema block copied from an old template, and the machine-readable version of the company slowly drifts away from the real one.
You can watch this happen in real time. Ask ChatGPT what Pompeii is and, at least when I tried it, you get the Roman city buried by Vesuvius, not the Spanish footwear brand. Ask Gemini about Factorial and you may get a maths lesson before it reaches the Spanish HR software company. Closer to home for this audience, search Google for MozCon, Moz's SEO conference, and you may be told you meant Amazon in the US, or shown a small European bird in Spain, before it gets to the conference itself. The brands exist. The systems just can't resolve the entity, so they default to the better-known one.
That gap, between who the brand is and who the machine thinks it is, is identity debt you can see.
The clearest public example I can point to is WooCommerce. In October 2023 the company rebranded to "Woo" and migrated from WooCommerce.com to Woo.com. After the March 2024 core update hit its organic traffic, it reverted the domain back to WooCommerce.com on April 9, 2024, keeping "Woo" as the name. Automattic's own post is candid about why: moving to Woo.com made WooCommerce harder to find in Google, a problem the March update made worse. The WooCommerce developer blog named the domain change as a contributing factor to the decline in organic traffic.
Editor’s note: This Woo rebrand “failure” is also discussed in Sitebulb’s website migrations training series.
A company with that much engineering talent still managed to sever its own entity from the name people search for. If it can happen to WooCommerce, in public, with a documented reversal, it is happening on a lot of smaller sites that will never write a post about it.
WooCommerce shows identity debt arriving through a rename. I saw a quieter version on a project of my own, where the debt came not from a name change but from how authority flowed through the site: a European brand in the health-education space whose real business is a handful of paid products. On paper it had what Google says it rewards: a founder with real credentials, an in-house team of specialists, a loyal audience. In the crawl, none of that was where it needed to be. The ten product pages that pay the bills pulled under 4% of the site's internal authority, while the blog took more than three-quarters of it.
Organic traffic told a similar story, landing on editorial rather than the product pages at a ratio of roughly eight to one. So Google did the logical thing: it read the entity as a health blog that happened to sell a few products, and ranked it like one. That didn't need a brand workshop to surface. It was sitting in the crawl. The structured data said the same: thousands of BlogPosting and author Person entities, and nothing marking up the products that are the actual business.
Internal authority by page type, summed from the site's Sitebulb URL Rank (indexable HTML pages only). Original graphic by the author based on real audit data.
This is a different metric from the roughly 8:1 editorial-to-product split in organic traffic noted above.
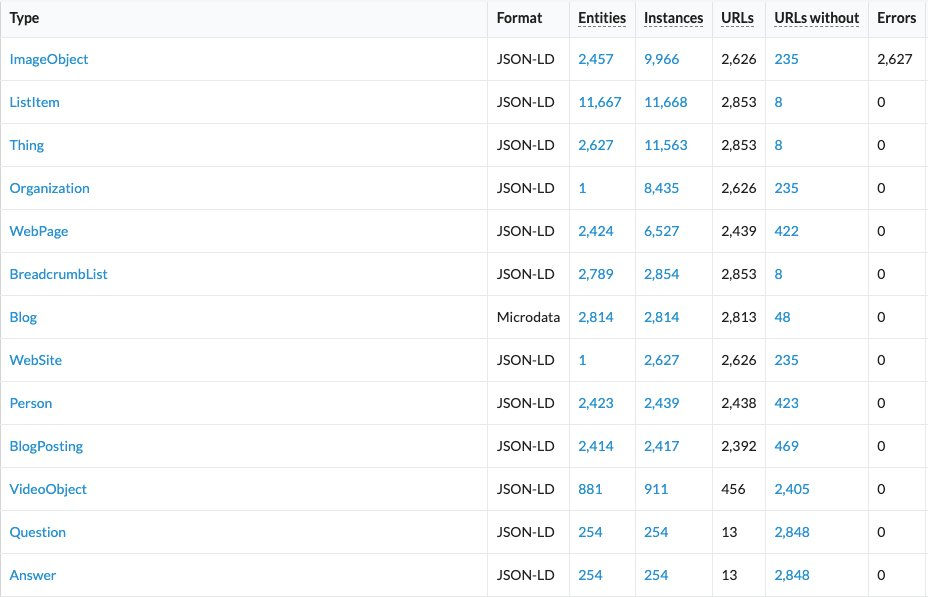
Sitebulb Schema Entities report from the same audit: the structured data reads like a publisher, thousands of BlogPosting and author Person entities and not one Product type.
Identity debt is not invisible. It leaves traces in the crawl. A renamed entity shows up as redirect chains, orphaned pages, and Schema that still references the old name. You do not need a brand-tracking platform to catch the first signs. You need the crawl you already run.
What Google says, and what it stops short of saying
If identity debt is the disease, Google has been unusually clear about the symptoms it cares about.
Start with the people Google pays to evaluate search quality. The Search Quality Rater Guidelines (September 2025 section 3.4 on E-E-A-T) tell raters to judge a site's trustworthiness not only by what it says about itself but by what independent, reliable sources say about it. Reputation, in Google's own framework, is something others confer on you, not something you assert.
That principle has teeth. As Google began enforcing its site reputation abuse policy, Forbes Advisor became the textbook case: by BuzzStream's analysis, the manual action wiped out close to 20 million monthly visits as affiliate content riding on Forbes' authority was cut loose from it. The point underneath that is about entity boundaries: Google decided the "Forbes Advisor" content was not really Forbes, and acted on the distinction.
Then there is the quieter tell. In November 2025 Google added a branded queries filter to Search Console, so you can separate searches that include your brand name from everything else. Google built a feature to measure brand demand. When the search engine itself starts instrumenting brand, it is worth noticing.
And John Mueller, posting on Bluesky in November 2025, put it about as plainly as he ever has: "Consistency is the biggest technical SEO factor." He meant the boring kind of consistency, where links, canonicals, and structured data all agree with each other. That is exactly where entity signals live.
So if consistency and independent reputation are what is being rewarded, the fair question is what we are sending in their place, and where we are breaking it without noticing.
Seven crawl signals that map to entity damage
What follows are seven things a normal crawl surfaces that I have learned to read as entity damage rather than ordinary SEO hygiene.
None of them are new findings. They are the same reports you open every week, with a different question attached. I have written each one in two halves: the analysis (what the crawl shows, the specific Sitebulb report that surfaces it, and why it counts as entity damage rather than hygiene) and the fix (a concrete remediation you can confirm on the next crawl). Diagnosing without fixing is just complaining with data, so every signal closes with something to do.
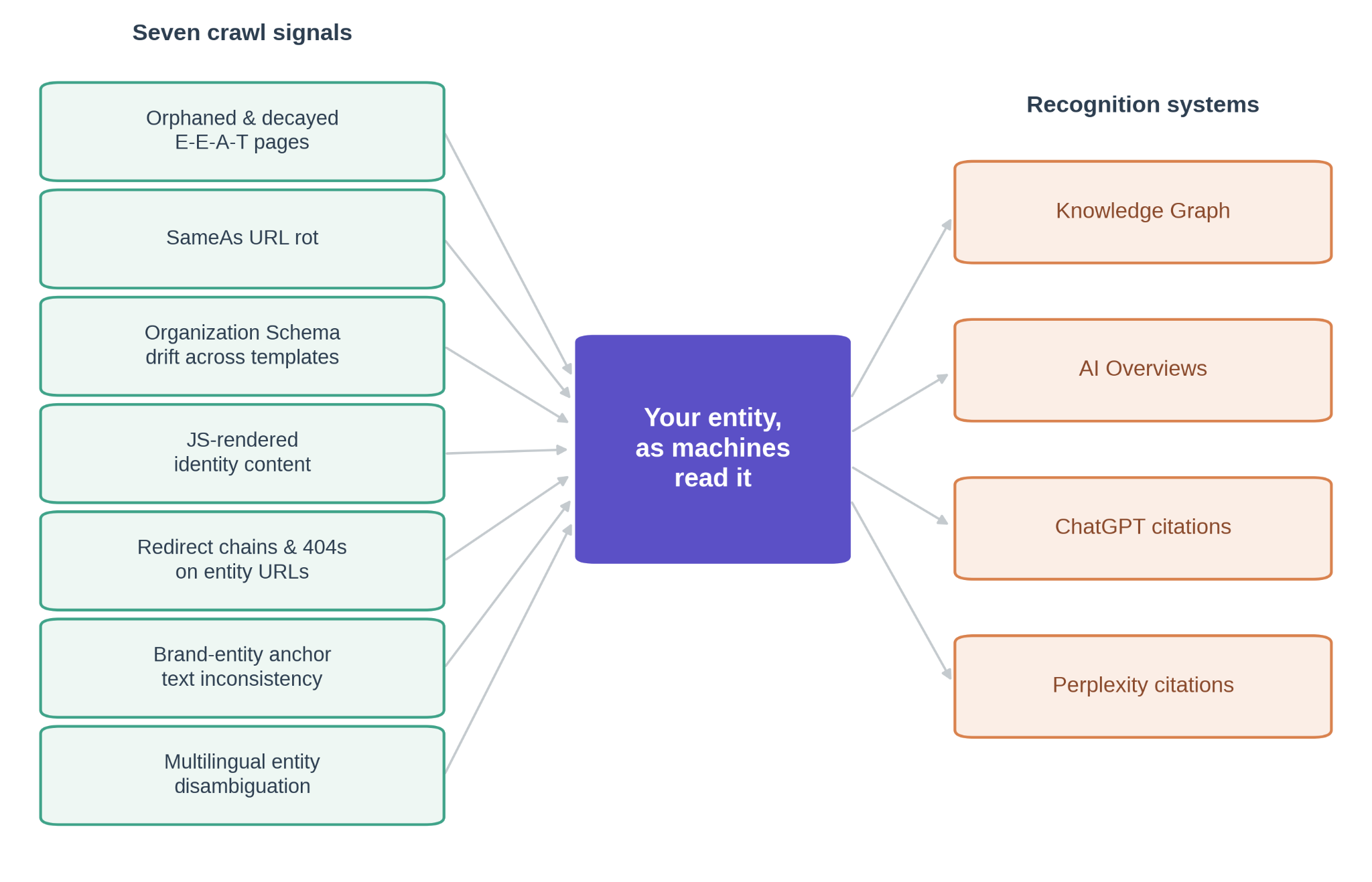
Original graphic by the author — illustrative diagram.
1. Orphaned and decayed E-E-A-T entity pages
Your About, Team, Contact, and author bio pages are not filler. The Quality Rater Guidelines (sections 2.5.2 and 2.5.3) treat them as primary reputation signals, the pages a rater uses to work out who is behind a site. So when those pages sit at crawl depth six, or are not linked from anywhere at all, you are burying the exact pages Google uses to identify the entity.
Sitebulb's Orphan Pages, Crawl Depth, and Internal Links to URL reports make this visible immediately. Sort your trust pages by crawl depth and internal link count and the neglect tends to jump out: an author bio with one internal link, a team page nobody links to, a contact page three clicks further out than it should be.
This is also where URL Rank earns its keep. Comparing the internal authority your site passes to its trust pages against what it pours into commercial pages usually tells an uncomfortable story.
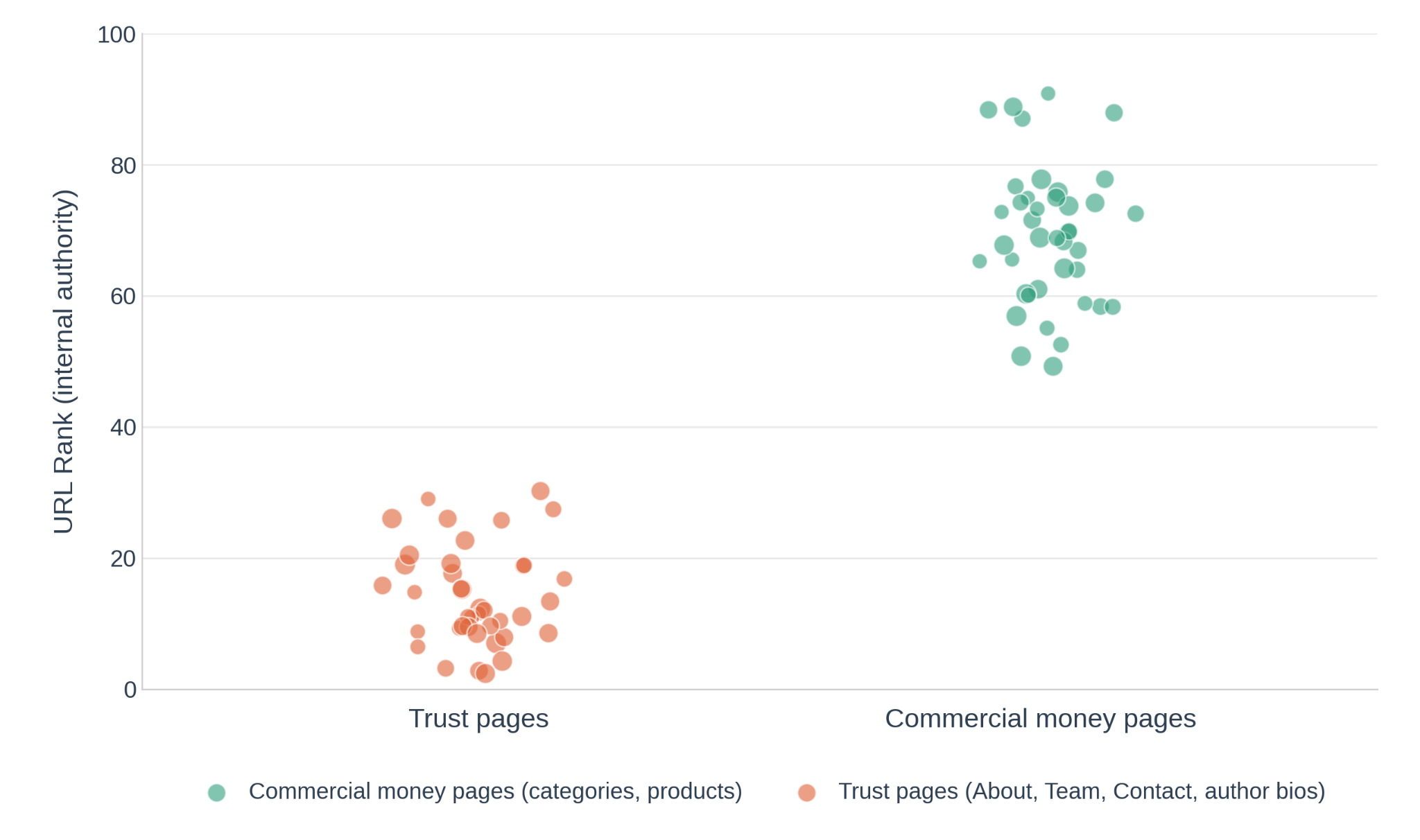
Original graphic by the author — illustrative diagram based on real audit data.
This is not abstract for me. One of the clearest cases I have worked on was a private cardiology clinic in a large Spanish city, on a low three-figure monthly budget. It had the classic problem: real medical expertise, none of it legible. Service and diagnostic pages were thin, authorship was invisible, there were no review signals or update dates, and it all sat on a creaking technical base. In a YMYL category, that reads less like a content gap and more like a trust gap, and trust is most of what is being ranked in the first place.
We rebuilt E-E-A-T as a system rather than a checklist: medical authorship, clinical review, sources, update governance, structured data where it mattered. Over the year, Top 10 keywords grew by nearly half and the clinic went from zero to more than 200 citations in AI Overviews. AccuraCast's December 2025 study of around 9,000 AI-cited sources found Person schema on 70.4% of the sources ChatGPT cited, which is the industry-level echo of the same point.
The fix:
Re-link trust and author pages into the main navigation or the relevant topical hubs so they sit a click or two from the homepage, then confirm on the next crawl that their depth has dropped and their internal link count has gone up. It is unglamorous work, and it puts the pages Google reads for identity back within reach.
2. SameAs URL rot
Your Organization Schema's sameAs array is meant to tell Google "this is us, across the web," pointing at your LinkedIn, your Crunchbase, your Wikidata entry, your verified social profiles. The trouble is that those links rot. A LinkedIn handle changes, a Crunchbase profile disappears, an X account gets reassigned, a Wikidata Q-ID redirects. Every dead sameAs is a weakened connection between your site and the entity graph it is trying to join.
You can catch this with the Broken Outbound Links report cross-referenced against the JSON-LD that the Schema Entities report extracts. Pull the sameAs URLs out of your structured data, check them against the broken-link list, and the rot shows up.
Andrea Volpini of WordLift, who wrote the Web Almanac's structured data chapter, frames a well-implemented sameAs as an entity fingerprint, the thing that lets search engines tell one entity from another. I have started treating an entity's identifiers the way I treat domain names. You would not let a domain quietly expire, and a sameAs pointing at a dead profile is the same kind of lapse, just less visible.
The fix:
Replace each dead sameAs with the current canonical destination for that entity, then verify two things: that the URL resolves, and that it actually belongs to the current entity rather than a renamed subsidiary or an abandoned account. Re-check on the next crawl.
3. Organization entity drift across templates
This one is easy to miss because no single page looks wrong. The header Schema gives one legalName, the footer gives another. The homepage Organization markup has a logo and a foundingDate; the rest of the site carries a thinner version with a different @id. Desktop and any alternate variants disagree. Individually, each is valid. Collectively, you are presenting several slightly different organisations and asking Google to reconcile them.
Jono Alderson has been vocal about why Search Console will not save you here: its structured data reporting is page-centric, counting valid items page by page, while entity coherence is a property of the whole graph. A site can pass every per-page check and still be incoherent as an entity.
Sitebulb’s Schema Entities report, with custom JSON-LD extraction, is built for exactly this. Extract Organization markup across every template and line it up. Per the Web Almanac's 2024 structured data chapter, links to authoritative identity sources are rare: Wikidata appears on roughly 0.17% of pages and Wikipedia on 0.13%, with even the most common single target, Facebook, on just 4.53%. Most sites are leaving entity reconciliation to chance rather than governing it.
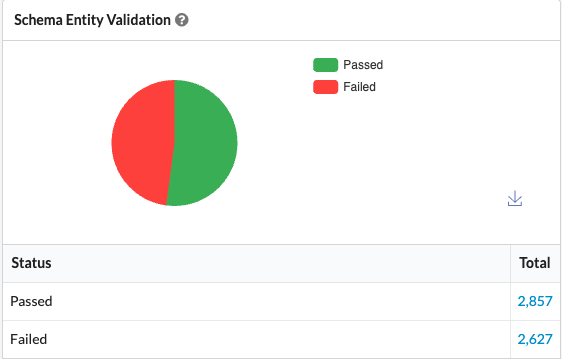
Sitebulb's schema validation on a different client audit: close to half of all structured-data entities fail, driven by ImageObject errors (missing creator and license properties, invalid width) across thousands of URLs, including the image schema that feeds the Organization logo.
The fix:
Treat this as a governance job, not a code job. Unify Organization markup against a single source of truth (one @id, one canonical legalName, one logo URL) applied across every template, then re-extract Schema across all templates on the next crawl to confirm they agree.
4. JS-rendered identity content
Here is a failure mode that barely existed a couple of years ago. Testing through 2024 and 2025, by Vercel and MERJ and by practitioners like Glenn Gabe, has found that the bots feeding the major AI systems have generally not executed JavaScript. GPTBot, ClaudeBot, and PerplexityBot tend to fetch your raw HTML response and move on, rendering little or none of it. If your identity content, the Organization Schema, the About copy, the author bylines, only appears after client-side rendering, those crawlers risk never seeing it at all.
Even Google, which does render, pays a tax for it. Onely's experiment found Google needed 9x more time to crawl JavaScript pages than equivalent HTML. Most non-Google crawlers skip that rendering step, so for them the gap is not 9x. It is closer to all or nothing.
Sitebulb's Response vs Render comparison is the report for this. Run it against the homepage and your trust pages and look at the gap: anything present in Rendered but missing from Response is invisible to AI crawlers.
The fix:
Server-side render or pre-render your homepage and identity pages so the key properties (the H1, the Schema, breadcrumbs) sit in the raw HTML, then verify by re-running Response vs Render and confirming those properties now appear in the Response column.
Editor’s Note: We have a ton of resources about JavaScript SEO, rendering and AI visibility here.
5. Redirect chains and 404s on entity-critical URLs
A redirect chain on a product page is a crawl-efficiency note. The same chain on /about, /leadership, or /press is something else: friction on the pages that establish who you are. Worse are 404s on URLs that external sources point at, the website field on your LinkedIn company page, the link in your Crunchbase profile, the official site recorded in Wikidata. When those break, you are severing connections the entity graph relies on, and you usually cannot see it from inside your own site.
The Redirect Chains, Inbound Links to URL, and Broken Internal Links reports cover the internal side. This is the same audit logic from the WooCommerce case, applied to a different set of URLs: a domain or path change that is not cleaned up end to end leaves exactly these traces.
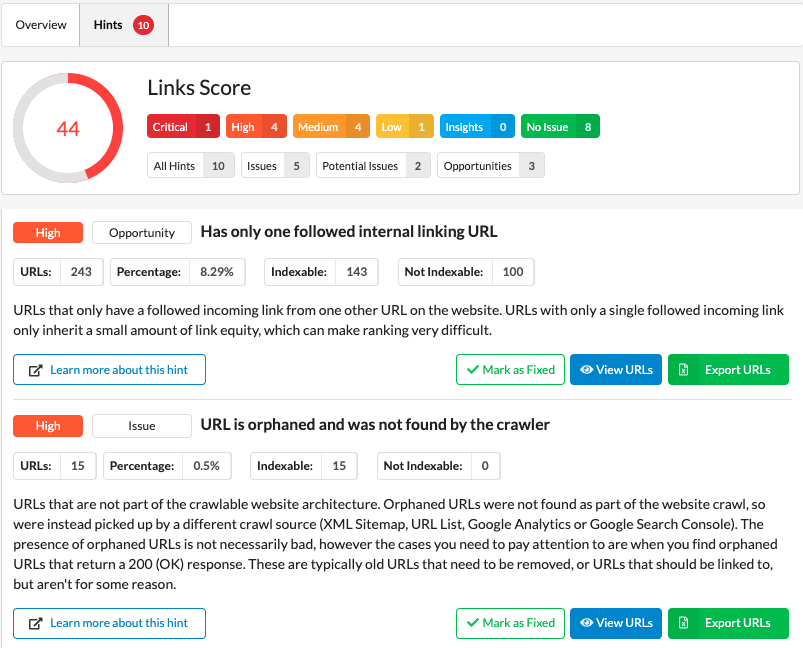
Sitebulb's Links hints from another client audit: 243 URLs (8.29%) have only one followed internal link, 143 of them indexable, and another 15 are orphaned, the structural pattern that strands trust and author pages.
I saw the same logic on a hotel group migration. The brand was effectively running two competing sites, a desktop version and an old m. mobile subdomain, with device-based redirects misfiring and the two cannibalising each other in the index. Mapping every legacy URL from both into one clean responsive structure recovered the lost visibility and, in one property, lifted direct bookings by 306%.
The fix:
Collapse the chains to a single 301, and restore any 404'd entity URLs to their canonical destinations. Where an external knowledge base (Wikidata, Crunchbase, a directory) points at a dead URL, update the reference at the source too, then verify the chains are gone on the next crawl.
6. Brand-entity anchor text inconsistency
I am less sure of this one than the other six, because it cuts against advice I have given for years.Cyrus Shepard's Zyppy 50-site case study found that sites which lost traffic through recent Google updates tended to have more internal anchor text variation per page, not less, with internal anchors per page correlating at –0.337 against traffic change.
It is a small sample, and as Shepard is careful to say, correlation is not causation. But it is a genuinely awkward finding, not least because it cuts against his own larger 23-million-link study across 1,800 sites, which found more internal anchor variety tracking with more traffic. I read the two as context-dependent rather than contradictory: the 50-site cut looked specifically at sites caught by recent updates, where the thing being corrected is often over-optimisation around a handful of money pages.
The reading I find plausible is narrower than "varied anchor text is bad." It is that when you are linking to your own brand-entity pages, the homepage, the About page, the core product pages, ten different anchors for the same destination dilute the reinforcement rather than strengthen it. Consistency, again.
Sitebulb's Internal Link Anchor Text and Outgoing Internal Links to URL reports let you isolate the anchors pointing at those specific URLs.
The fix:
Tighten the anchor patterns around the canonical brand name for your most important entity pages, then re-check the anchor-text variance for the homepage on the next crawl. I would treat this as a careful adjustment on the pages that define the entity, not a sitewide rule.
7. Multilingual entity disambiguation
For a single-country brand this does not apply. For a multinational, it can fragment the entity. When alternateName diverges across hreflang clusters, when legalName drifts between country sites, when each market keeps its own set of sameAs links that never reconcile to one Wikidata Q-ID, you stop being one organisation in several languages and become several organisations Google has to disambiguate.
The way to see it is to cross-reference the Hreflang Map with Schema extraction, cluster by cluster. Pull the Organization markup for each hreflang group and compare names, identifiers, and sameAs sets side by side.
The fix:
Following the same principle as signal three, scaled across languages, unify Organization markup so every cluster resolves to one parent Wikidata Q-ID, one canonical legalName, and a consistent sameAs set, while leaving genuinely local details (a local phone number, a regional address) intact. Verify by re-extracting Schema per cluster on the next crawl. This is enterprise-grade governance, the kind Volpini argues for, and it is where the gap between a tidy single-site audit and a real multinational one shows up most.
The other half of the audit: how the entity is perceived
Everything so far looks at what the site sends into the graph. There is a second half, and it is the one the marketing team in the opening was already staring at: what comes back. Borrowing a frame I use in talks, call it the perception gap: the distance between how a brand sees itself and how the systems that sit between it and its customer actually describe it. Identity debt, from the start of this piece, is what that gap leaves behind when it stays open. The gap is the state; the debt is what accrues.
The crawl tells you what you are sending. The SERP and the AI answer tell you what landed. A brand-name search that returns a half-empty Knowledge Panel with an old logo, an own-name query where a competitor sits above you, an assistant that reaches for a better-known namesake when asked who you are: these are the readouts, not vanity checks. And they are auditable in the same disciplined way as a crawl.
Search the brand name and read the panel. Ask the main assistants to describe the brand and note whether they recognise it or resolve it to something else. Where the answer is wrong, trace it back to one of the seven signals: a rotted sameAs, drifting Organization markup, identity content stranded behind JavaScript. Each of those is something you can pull straight from the audit: the Schema Entities extraction for the sameAs and the Organization markup, Response vs Render for anything stranded behind JavaScript.
There is another perception metric: Branded search demand, now filterable in Search Console, is the clearest single sign of whether the entity is landing with real people. When it climbs, recognition is working. When it flatlines while everything else grows, the site is doing the traffic but not the recognition.
Perception is not only recognition, though. It is trust, and trust is built in stages.
Watching the queries people actually use, I keep seeing them fall into the four stages of Ayush Poddar's trust architecture: recognition ("what is magnesium good for"), credibility ("natural versus synthetic magnesium"), risk reduction ("is it safe to take magnesium every day"), and commitment ("buy a sleep supplement"). Mapping those stages onto search intent is my own habit, but the ladder is his. Most sites pour content into the first and the last and starve the middle, the risk-reduction questions, which in my projects is exactly where a person decides whether to trust you. For a technical SEO, that gap is not soft at all. It is a content-coverage hole you can map by intent across your URLs, sitting right next to the trust pages from signal one.
Put the two halves together and the thesis is simple. The symptom shows up as SEO. The cause is usually coherence, between who the brand is, what it says, and how the machines that stand between it and its customer read it. The crawl is where you catch what you send. Perception is where you see what arrived. Which raises a fair challenge: is any of this worth the extra attention right now?
The case for running this audit now
I want to keep this short, because stacking studies is its own kind of dishonesty. A couple of data points carry the argument.
The strongest is the one from the opening. Ahrefs' 75,000-brand study found branded web mentions correlated with AI search visibility at 0.664, against 0.218 for backlinks. The signals that predict AI visibility are brand-shaped, not link-shaped. It shows up in citation behaviour too: SE Ranking's study of 129,000 domains found that sites with profiles on review platforms like G2, Trustpilot, and Capterra earned roughly three times more ChatGPT citations than sites without them.
Now the honest caveat, because I would rather you trust the framing than oversell it. SE Ranking's AI Mode research found AI Mode results overlapping with themselves only about 9.2% on same-day re-runs, and Profound has reported that 70 to 90% of cited domains churn out within six months. This is a snapshot, not a stable ranking model. Chasing this week's citations is a losing game. But the diagnostic holds regardless of the volatility. A coherent entity is the thing that survives the noise.
What this changes in the audit conversation
Building that coherence does not turn you into a brand strategist. It asks you to read the crawl you already have with the entity in mind, and to notice which findings cross from hygiene into identity.
A redirect chain on a product page is a line in the crawl-efficiency section of the report. A redirect chain on the About page is the start of a conversation about entity stability, the kind a CMO actually wants to have. A broken sameAs is a broken link until you connect it to a Knowledge Panel showing the wrong logo, and then to a competitor outranking the brand for its own name. Same finding, different stakes, and a very different meeting.
That is really the whole shift. The two rooms from the opening, the technical SEO with the crawler and the marketing team arguing about ChatGPT, were looking at the same problem the entire time. The data was already sitting in the crawl. What was missing was the lens.

David Carrasco is an international SEO consultant and speaker based in Barcelona. He works with brands on search visibility across traditional and AI-driven discovery channels.
Related Articles
 SEO & UX: Organic Growth via “The Retention Ladder”
SEO & UX: Organic Growth via “The Retention Ladder”


 AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean
AI Search, RAG, Agents and Crawl Bots: A Plain-English Guide to What They Mean

 What AI Agents See: The Accessibility Tree Is an SEO Surface
What AI Agents See: The Accessibility Tree Is an SEO Surface
 Sitebulb Desktop
Sitebulb Desktop
Find, fix and communicate technical issues with easy visuals, in-depth insights, & prioritized recommendations across 300+ SEO issues.
- Ideal for SEO professionals, consultants & marketing agencies.
 Sitebulb Cloud
Sitebulb Cloud
Get all the capability of Sitebulb Desktop, accessible via your web browser. Crawl at scale without project, crawl credit, or machine limits.
- Perfect for collaboration, remote teams & extreme scale.