Sitebulb has an 'Advanced Settings' option which includes a number of options for limiting your crawl.
I know what SEOs are like though: 'I want to crawl all the pages, I want ALL THE DATA.'
While you can get away with the 'all the data' approach on smaller sites, as soon as you start trying to crawl large sites, you are going to start running into problems.
For example, I crawled an ecommerce site with 50,000 pages indexed in Google. The faceted navigation spawned so many parametrized pages that the total crawled URLs was over 800,000.
This is the obvious benefit of limiting the crawl - by only crawling the URLs you want to crawl you can save a lot of time. But it also means the reports will be cleaner. For example, the Indexation report won't be over-run with canonicals for all the parametrized URLs, making it easier to see the 'real' data you want to look at.
In the example below, the site is not particularly large, but it serves as an example as to how even small sites can bloat an audit and make it more difficult to differentiate the meaningful data. The 'audit limiting' methodology outlined below becomes a lot more useful when dealing with really massive sites.
We'll work though an example from start to finish. Say EE was my client, and I wanted to Audit their online store, I might start by just doing a vanilla Audit, to see what I get.
First things first, we can see that there are quite a few external links:
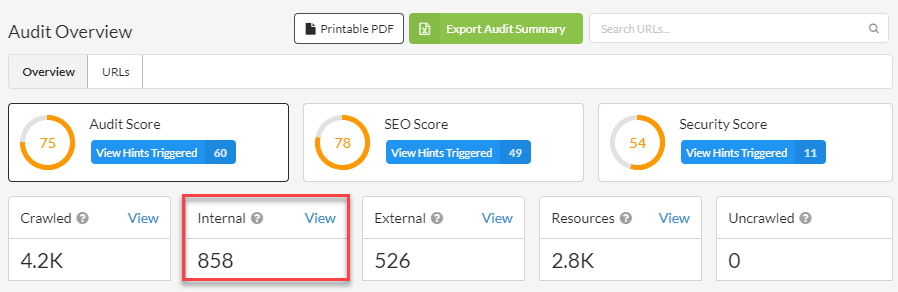
On closer inspection, lots of these are subdomain URLs (which makes a lot of sense in this instance):
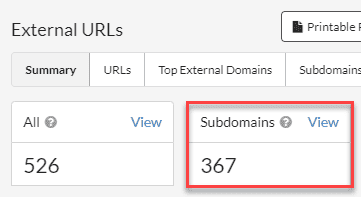
So we might want to adjust the crawl settings to avoid these URLs.
Since we're looking at an ecommerce store, it's not surprising to find lots of parametrized URLs. To find these, we just head over to the URL Explorer and add an Advanced Filter as below:
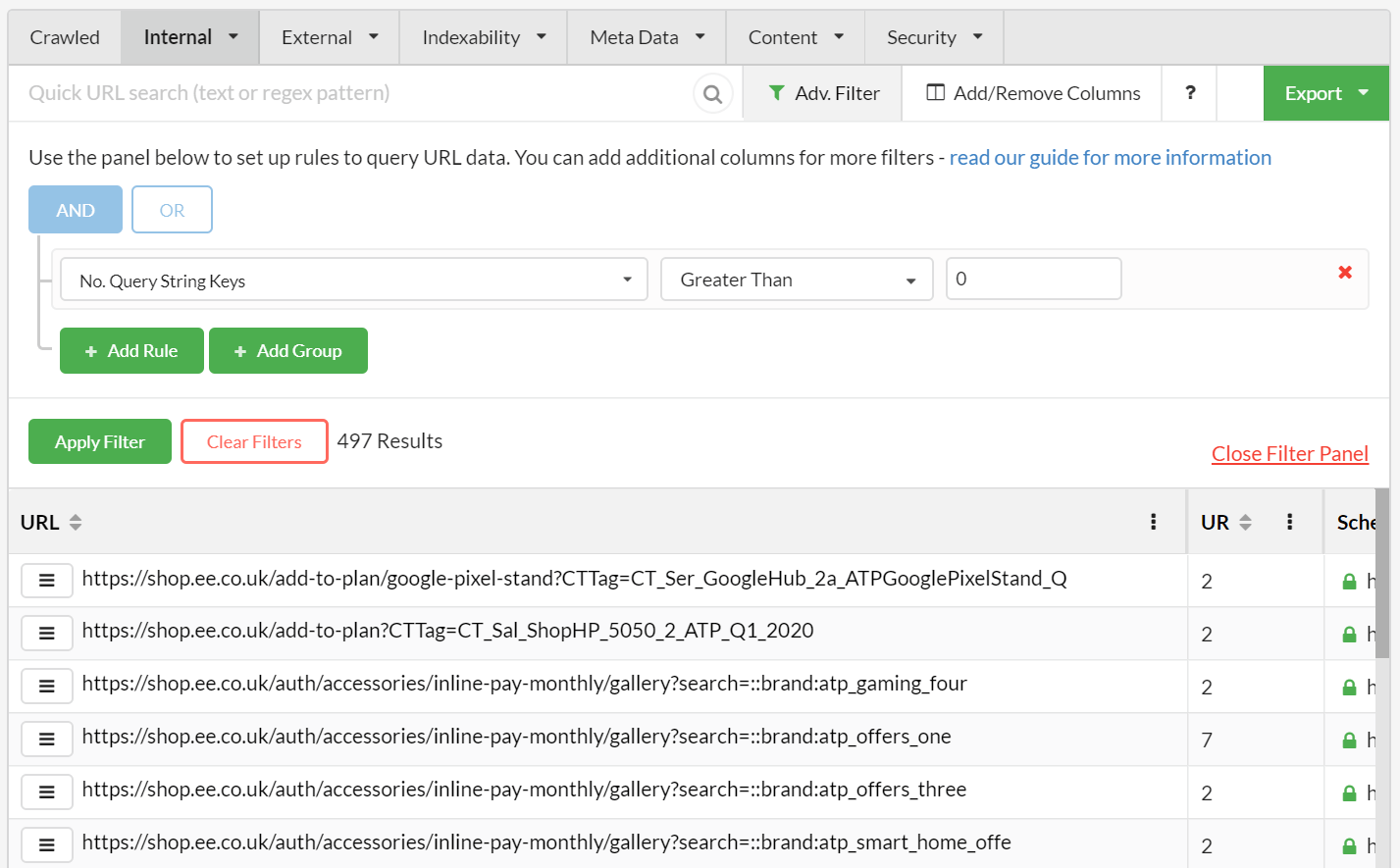
From a total of 1090 internal HTML URLs, 497 of them contain a query string.
These are caused by a typical faceted navigation, where every 'refinement' option down the left spawns more new URLs, which are picked up and crawled by Sitebulb.
Aside: when auditing, it is actually useful that these URLs have been crawled, since you would want to check if canonicals are in place and/or suggest to the client that these variations should be blocked in robots.txt.
For the sake of this article, we'll assume that canonicals are in place and you simply want to exclude them from future audits (see further below for instructions on how to put the limits in place).
In addition to parameterized URLs, we can also find other patterns which are causing extra pages to be crawled.
Often on ecommerce stores these might be things like /basket/ or /cart/ URLs, that all just 302 to a login page. The EE site handles this stuff pretty well, but for the sake of argument, let's assume that their /add-to-cart/ pages have this problem:
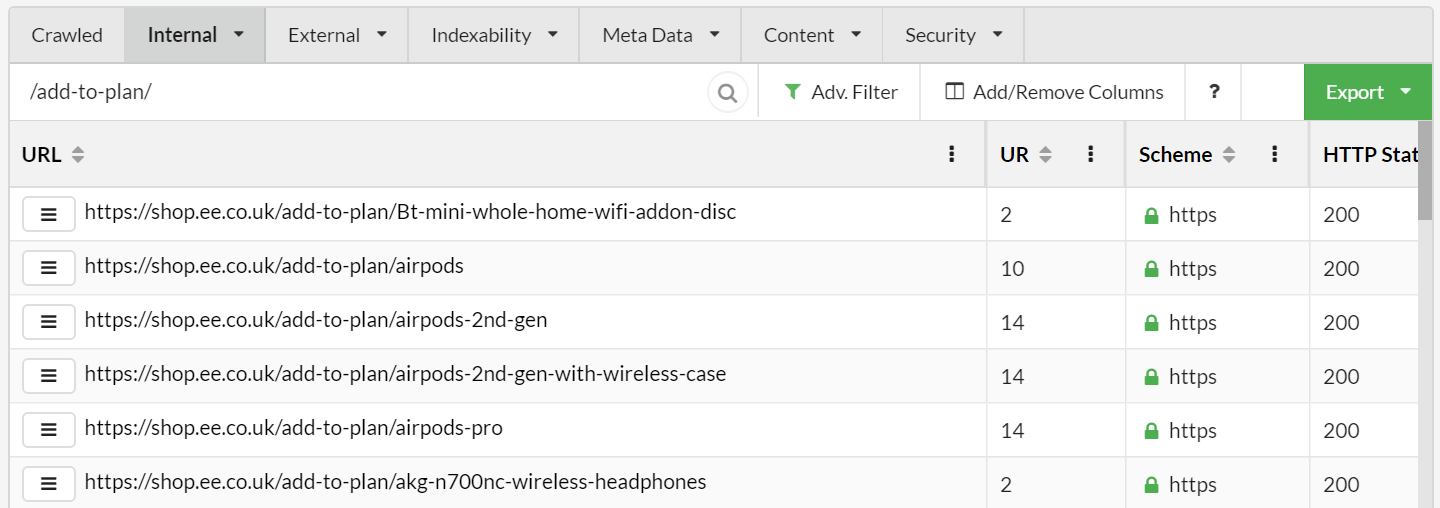
Since these sort of links can end up on every single product page, this can inflate total crawl numbers massively on bigger sites, so excluding the URL pattern is extremely helpful.
Based on our observations above, we might wish to put some crawl limits in place to ensure future audits end up cleaner.
Projects settings persist from one Audit to the next, within the same Project. This means you can update crawl settings and save them against the Project, making your audits more customised over time.
In this case, we want to limit some of the crawl settings in order to remove the unwanted URLs identified above, in order to get a cleaner audit.
Navigate to the Project in question, then click the blue button Edit Settings.
From here you can simply edit any settings, then hit 'Save' and the Project settings will be saved ready for your next audit.
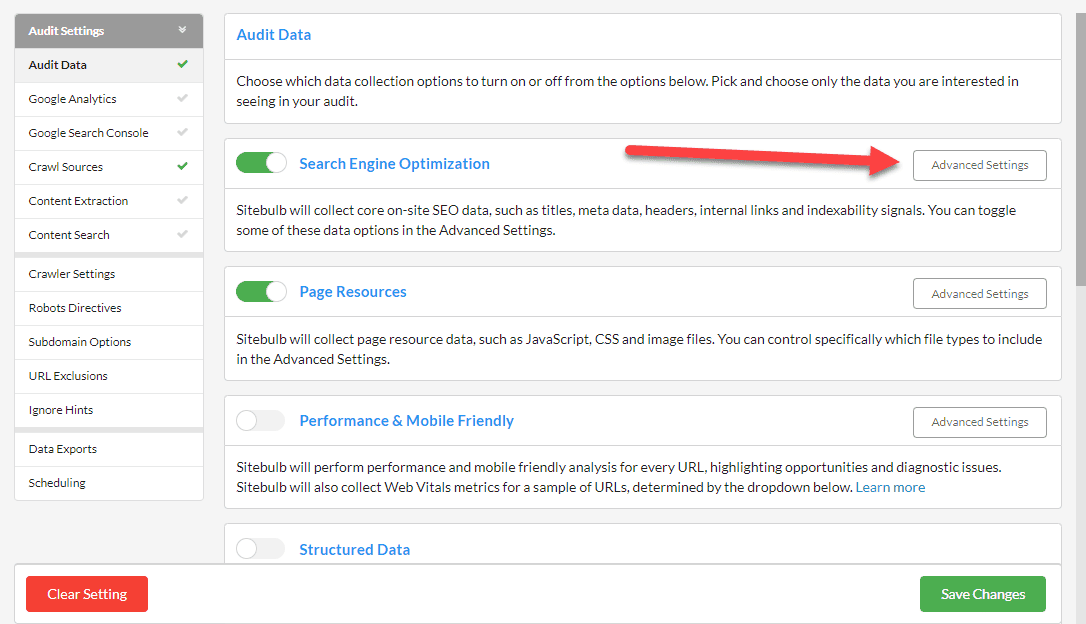
In our case, everything we need lives in 'Advanced Settings', so scroll down to open the Advanced Settings box.
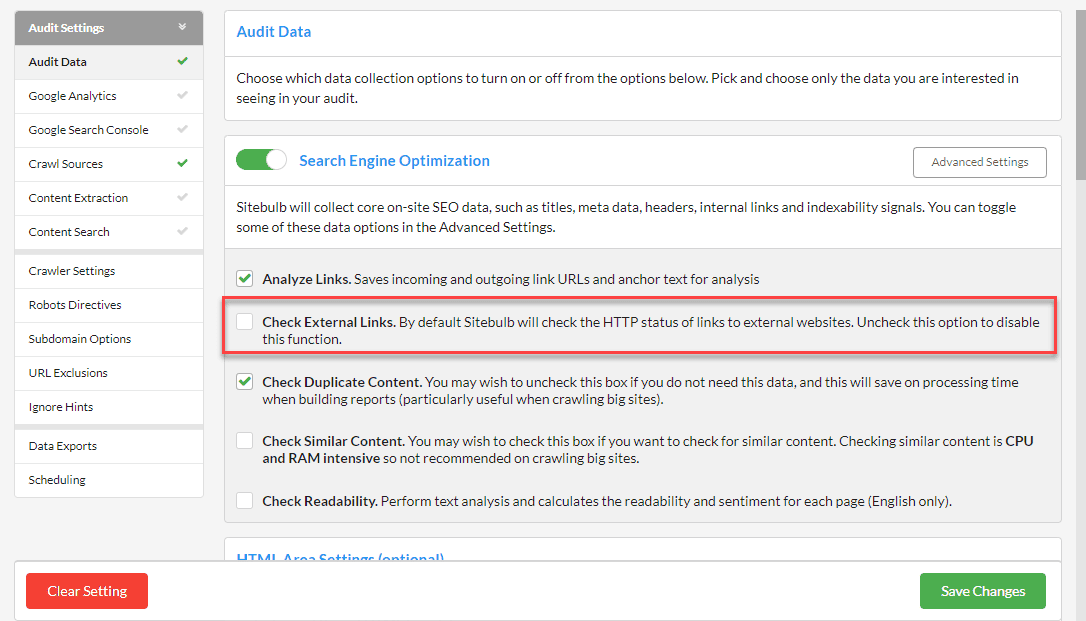
Within Advanced Settings, navigate to the Crawler tab, scroll down and then UNTICK 'Check External Link Status'.
This means that Sitebulb will not crawl any external or subdomain URLs on future audits.
Within Advanced Settings, navigate to the URLs tab, then select the Excluded Parameters option, and on this screen, UNTICK the box for 'Crawl Parameters' (which is always on by default).
This means that Sitebulb will not crawl any parametrized URLs it encounters on future audits.
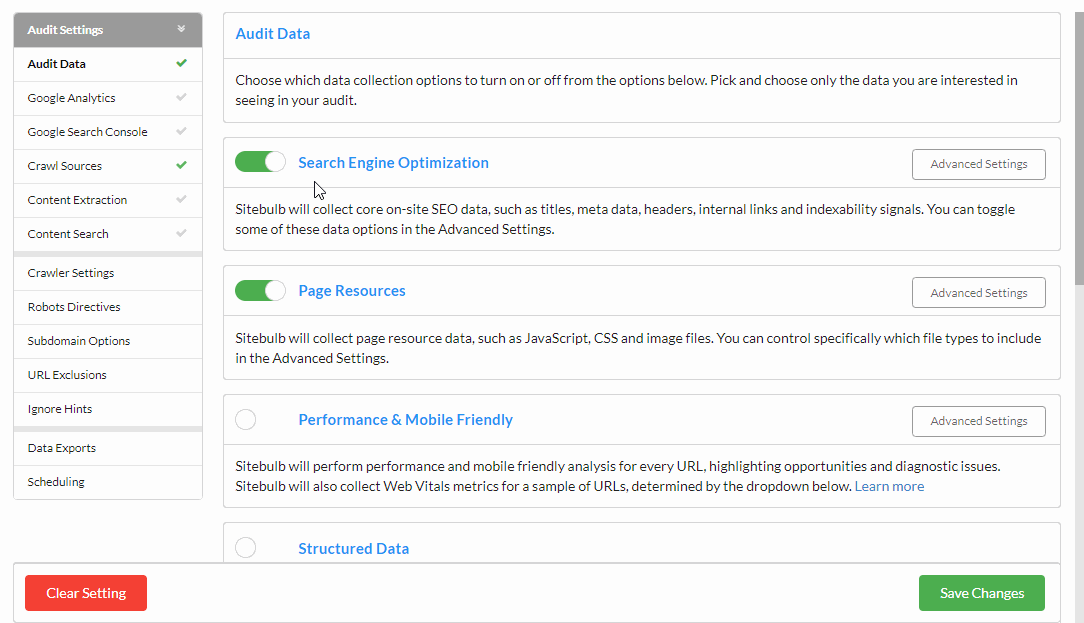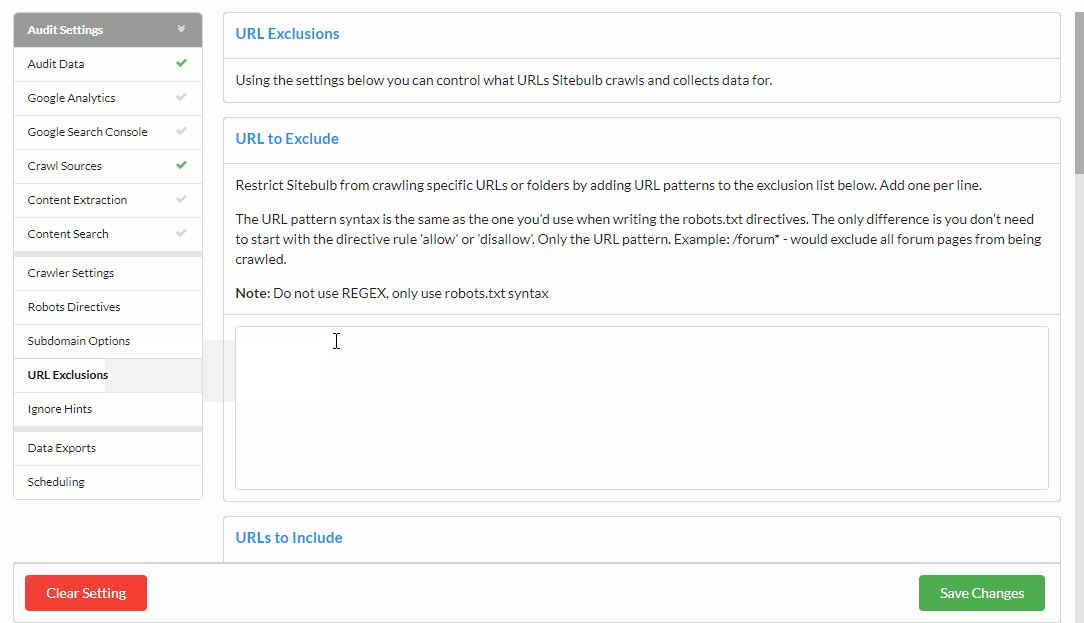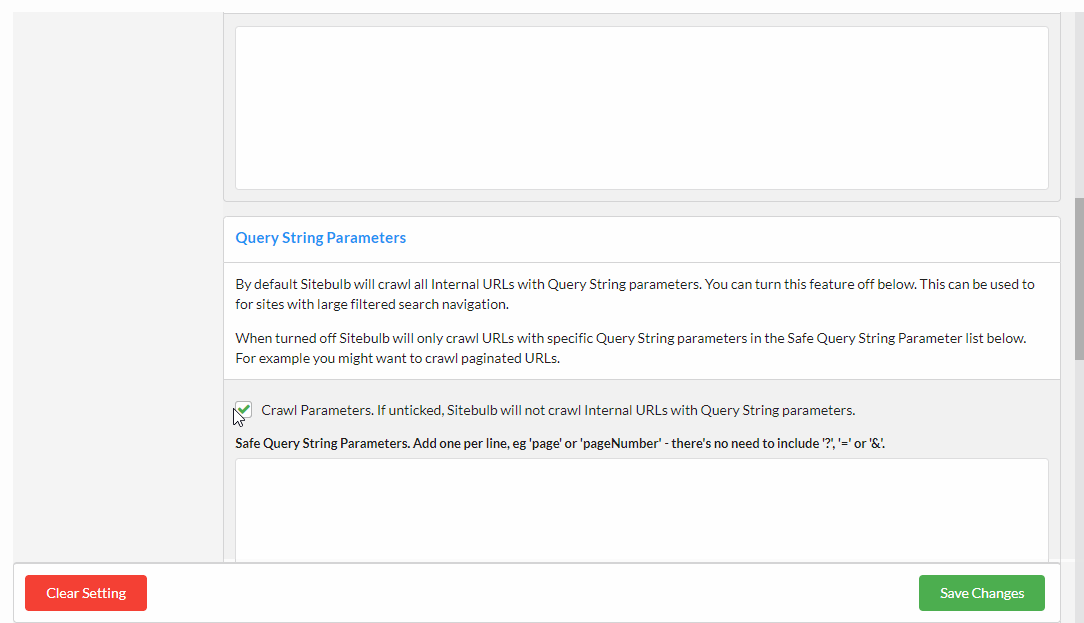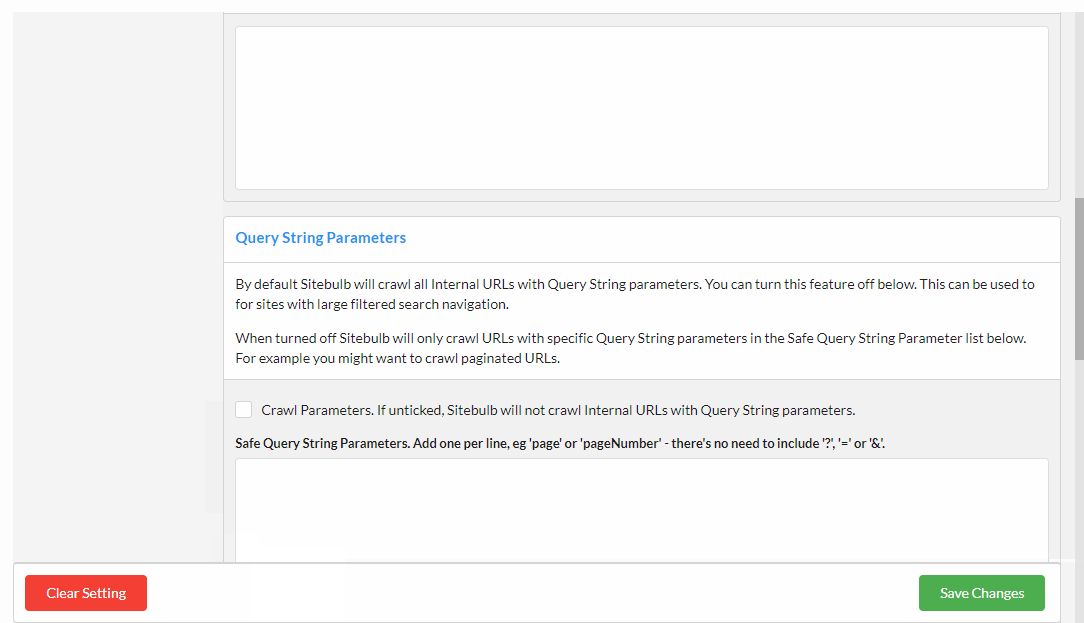
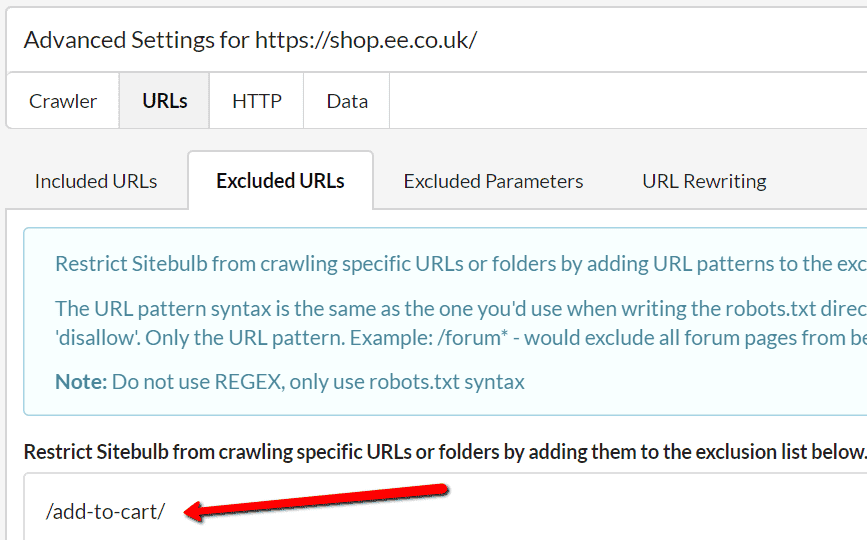
Within Advanced Settings, navigate to the URLs tab, then select the Excluded URLs option, and on this screen, add in the folder path you wish to exclude.
This means that Sitebulb will not crawl any URLs it encounters that start with the string: https://shop.ee.co.uk/add-to-cart/- it will not schedule these URLs to be crawled, so they won't appear in your reports at all.
You can do the same sort of thing in another way by 'including' URLs instead. Say we were only interested in crawling the mobile phones section of the site. To do this, we simply need to add /mobile-phones/ to the Included URLs list in Advanced Settings.
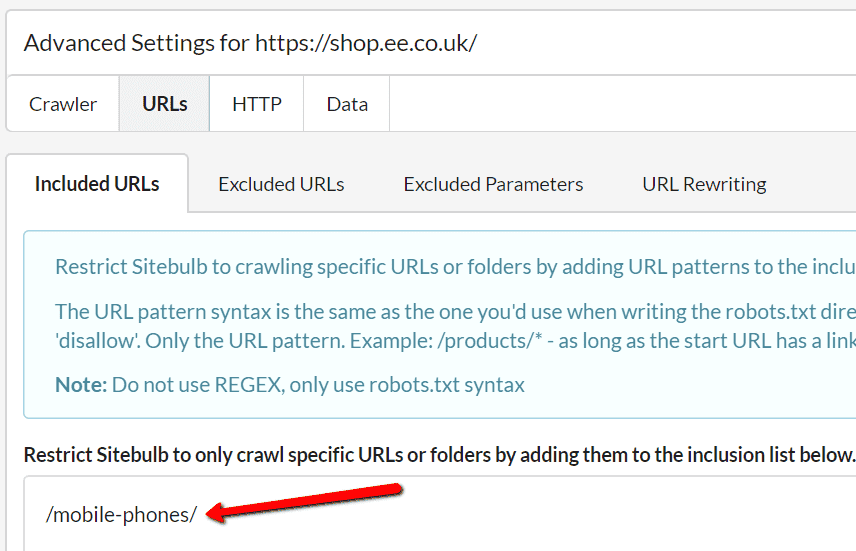
What this does is it excludes everything that doesn't match the specified path. So when the crawler encounters links to https://shop.ee.co.uk/mobile-phones/ - these WILL be scheduled to crawl, but nothing else will be (unless you included some more paths or URLs in the Included URL List).
Recrawling the site again with our new settings (except the 'included' example) results in a much cleaner audit, that takes a lot less time to process and is a lot easier to dig through.

We've reduced the total number of crawled pages by about two thirds. With bigger sites, this could be the difference between 300,000 pages and 100,000 pages (it's just multiples of 3 people, you can quite literally do the math. I hope).
Sitebulb has a wide range of options for limiting the URLs that it crawls, allowing you a great degree of control over the crawler. If you are crawling a particularly large website, these can become invaluable.
It might take a little trial and error to get the Project set up exactly as you want it, but once it is you'll be ready to go for all future Audits.